
Read the latest version of this article here
Introduction
Traditionally most chatbots were a tree of if-else blocks. Some had a layer of sophistication where users’ intent was captured, to decide which function should be triggered. However, the tech was never good enough to resolve an actual query — until now.
After GPT-3, we've seen how large language models are able to formulate near-human answers.
In this tutorial, we'll index documents, create a GPT-powered bot on top of it, and finally expose it as an API.
Context + LLM
These LLMs like ChatGPT aren't trained on enterprise data. They are general purpose models, created to chat and complete sentences.
To solve this problem, you don’t need to fine-tune these models. Instead, the better solution is to pass some knowledge along with the question. Let me give you an example.
We're "what is the top speed?" to ChatGPT:
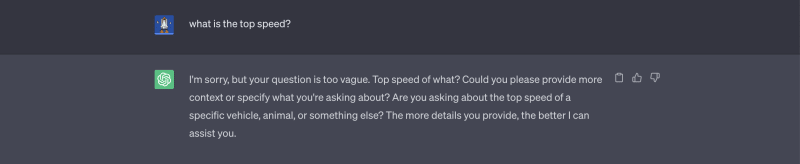

Both answers are correct, however, the second one is more useful for the customer.
The next challenge here is to get the “knowledge”, and use it to set the context for the LLM, along with the question. For this, we can use a retriever. Imagine you’ve database of all possible information about the car. You can perform a lexical search and find the rows that might have the answer. Then, pass these rows along with the customer’s question to the LLM.
Here's how the complete flow will look like —
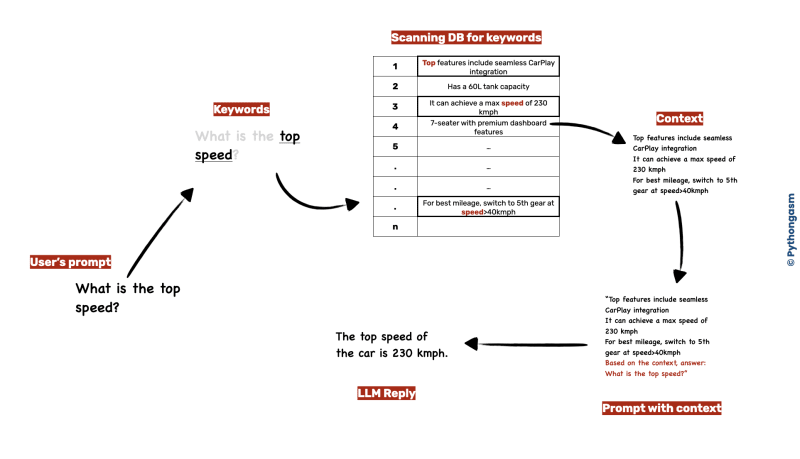
In the above example, we scanned the DB for the words "top" and "speed", concatenated the results together. For a better experience, we also added some instruction (to keep the answer concise) with the original question the customer asked. Put everything together, passed to the LLM and boom — we have the answer.
Indexing
In this exercise, we’ll build a simple bot that answers questions about the Mercedes-Benz A-Class Limousine.
Now companies don't have such pristine tables about the product information. They are available in the form of documents like the one above.
So, the first step is to create a database or a search index. To extract the text, we’ll use PyPDF2:
pip install PyPDF2
from PyPDF2 import PdfReader
import csv
SOURCE_FILE = "The Mercedes-Benz A-Class Limousine.pdf"
OUTPUT_CSV = "Mercedes-Benz-A-Class-Limousine.csv"
reader = PdfReader(SOURCE_FILE)
n_pages = len(reader.pages)
header = False # file is empty, so no header row is present
for n in range(n_pages):
page = reader.pages[n]
text = page.extract_text()
with open(OUTPUT_CSV, "a+") as f:
writer = csv.DictWriter(f, fieldnames=["page", "content"])
if not header:
writer.writeheader()
header = True # header row added
writer.writerow({"page": n + 1, "content": text.lower()})
f.close()
| page | content |
|---|---|
| 1 | the new mercedes-benz a-class limousine. |
| 2 | *please read the disclaimer2 nearest showroom contact us live chat design technology ... |
This creates a CSV file. To KISS, we'll use this CSV file + pandas as our index with our own version of retriever.
Retriever
Let's create a class Retriever which will be responsible for retrieving results based on customer query. The class will have the following functionalities:
- Removing stopwords Stopwords are common words like "a", "the", "in", etc., that don’t contribute to the search; negatively impact it more often than not. For example, if someone asks you "what are the top features of the car", you'll ignore most of the words in the question, and only look for the word "features".
stopwords = [...]
return [word for word in words if word not in stopwords]
- Filtering top rows Once we have extracted all the rows with matching keywords, we'll prioritise those with higher frequency of the keywords. This also becomes important considering the token limit of LLMs.
df = pd.read_csv('Mercedes-Benz-A-Class-Limousine.csv')
# add a column frequency which will contain the sum of frequencies of keywords words
df["freq"] = sum([df['content'].str.count(k) for k in keywords])
# sort the dataframe by frequency of keywords
rows_sorted = df.sort_values(by="freq", ascending=False)
- Retrieve The actual retrieve function which will be responsible for giving us the context based on customer query.
query = "top speed"
# select all rows where the content column contains the words "top" or "speed"
df = df.loc[df['content'].str.contains("top|speed")]
return f"{''.join(top_rows['content'])}"
Note that this is a very basic implementation of a retriever. The standard practice is to use something like ChromaDB or Azure Cognitive Search for indexing and retrieving.
Also, you can get the complete list of stop words this GitHub gist.
Let's put everything into the class:
import pandas as pd
class Retriever:
def __init__(self, source, searchable_column):
self.source = source
self.searchable_column = searchable_column
self.index = pd.read_csv(source)
@property
def _stopwords(self):
return [
"a",
"an",
"the",
"i",
"my",
"this",
"that",
"is",
"it",
"to",
"of",
"do",
"does",
"with",
"and",
"can",
"will",
]
def remove_stopwords(self, query):
words = query.split(" ")
return [word for word in words if word not in self._stopwords]
def _top_rows(self, df, keywords):
df = df.copy()
df["freq"] = sum([df[self.searchable_column].str.count(k) for k in keywords])
rows_sorted = df.sort_values(by="freq", ascending=False)
return rows_sorted.head(5)
def retrieve(self, query):
keywords = self.remove_stopwords(query.lower())
query_as_str_no_sw = "|".join(keywords)
df = self.index
df = df.loc[df[self.searchable_column].str.contains(query_as_str_no_sw)]
top_rows = self._top_rows(df, keywords)
return f"Context: {''.join(top_rows['content'])}"
Now, we can easily instantiate this class :
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
LLM
The next step is to pass this context to an LLM. We'll use SOTA gpt-3.5-turbo model. You'll need an OpenAI API key for this, which you can get here.
Here's a sample OpenAI API Request:
OAI_BASE_URL = "https://api.openai.com/v1/chat/completions"
API_KEY = "sky0urKey"
CONTENT_SYSTEM = "You're a salesman at Mercedes, based on the query, create a concise answer."
def llm_reply(prompt: str) -> str:
data = {
"messages": [
{"role": "system", "content": CONTENT_SYSTEM},
{"role": "user", "content": prompt},
],
"model": "gpt-3.5-turbo",
}
response = requests.post(
OAI_BASE_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json=data,
).json()
reply = response["choices"][0]["message"]["content"]
return reply
>>> llm_reply("hello")
"Hello! How can I assist you today?"
messages is a list of dictionaries. Each dictionary has two keys — role and content. The "system" role sets a role for the bot, and works like an instruction. We'll pass our messages under role "user".
Let's ask our first question about the A Class Limousine:
query = "What is the size of alloy wheels?"
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
reply = llm_reply(f"{context}\nquery:{query}")
>>> reply
"The size of the alloy wheels is 43.2 cm (17 inches)."
🎉 Congrats! You successfully created your a GPT-powered bot from a PDF file.
FastAPI application
Let's expose our function as an endpoint using FastAPI.
We're also mounting a static directory, and rendering templates to integrate this API with an UI.
requirements.txt
fastapi==0.78.0
pandas==1.5.3
pydantic==1.9.1
requests==2.27.1
uvicorn==0.17.6
bot.py
import pandas as pd
import requests
OAI_BASE_URL = "https://api.openai.com/v1/chat/completions"
API_KEY = "sky0urKey"
CONTENT_SYSTEM = "You're a salesman at Mercedes, based on the query, create a concise answer."
class Retriever:
...
def llm_reply(prompt: str) -> str:
...
main.py
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
from fastapi.staticfiles import StaticFiles
from bot import Retriever, llm_reply
from pydantic import BaseModel
class ChatModel(BaseModel):
query: str
templates = Jinja2Templates(directory="./")
app = FastAPI()
app.mount(
"/static",
StaticFiles(directory="./", html=True),
name="static",
)
@app.get("/")
def root(request: Request):
return templates.TemplateResponse("index.html", context={"request": request})
@app.post("/chat")
def chat(cm: ChatModel):
query = cm.query
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
prompt = context + "\n" + "Query:" + query
return llm_reply(prompt=prompt)
We will use uvicorn to run the app:
uvicorn main:app --port 8080 --reload
You can go to localhost:8080/docs and send a sample request from Swagger UI or simply send a curl request:
curl -X 'POST' \
'http://127.0.0.1:8080/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "What is the size of alloy wheel?"
}'
Now that the API is live, you can connect it to your frontend. For this tutorial, I used this beautiful design on codepen (Credits: abadu).
Demo
Link to the complete source code is attached below.
Challenges & Next steps
Retriever: As we discussed, there's scope of improvement in the retriever. For e.g., you can implement a function for spell check, or integrate the whole thing with some cloud based service like Azure Cognitive Services.
Ring fencing: Improve the prompt/system instructions so that the bot is constrained to answer only Mercedes-related questions, and politely declines other questions.
Chat history: The current bot doesn't send historical messages. Also, it doesn't recognise follow-up questions. For example, I should be able to ask "what other devices" (follow-up question) after asking "can i connect my iphone?". Hence, you should identify follow-up questions, and also send chat history.

Top comments (6)
I just pulled the code to my Ubuntu box from your github.
I then followed the steps for installing dependencies via pip. All went well.
BTW, I actually had to install uvicorn separately because I don't have it on my machine.
After that I CD to backend directory and tried to start the app and here is what I get (you can see that uvicorn starts, then I saw the following error:
I had to run
$ pip install jinja2in my backend directory to get the app to start successfully.Thanks for letting me know, I'll add "jinja2" in
requirements.txt.Wow! I've only done an initial quick-read of this article so far, but it looks really good.
Right after I write this comment up, I'm going to go back and follow all your steps and see if I can get it all running.
This is a very cool and inspiring article.
I've been looking for something to show me the basics of how to do this and if this all works as well as you've shown it is very cool.
Thanks for writing this one up and sharing.
Thanks for reading :D
Wow! As someone who is just starting out in the programming world, this blog has been incredibly helpful to me.
The tutorial is very detailed and the way you explain is very easy to understand. The code examples and explanations helped me understand the flow better and I will put it into practice right now.
I NEED to see more tutorials like this in the future. thanks for sharing this valuable information!
Here are some more details.
First of all I had to set
API_KEYinmain.pyto my current api key value.Of course, that meant I had to go out to my chatGPT account and generate a new one because I never had used an API Key before. I had just used the chatGPT interface previously.
Every time I tried querying the app, it would just spin and then I would get an error which looked something like (truncated for this message):
Line 77 in bot.py looks like:
After a session of
debuggin-via-loggingI was able to determine that it is because I don't have any free API access available. 💰💵 💸 😞The reason it failed is because when an error is returned from chatGPT API it doesn't contain the "choices" element.
I added the following code on line 76 of bot.py (so I could see what was being returned):
The returned error looks like the following:
I'm sure you'll add some error-handling code for the error case later.
Well, I gave it a shot and it looks interesting. Maybe I'll try it again later when I add a Credit Card 💳 to my chatGPT account. 🤓