
Have you noticed a gap in knowledge between learning how to scrape and practicing with your first project?
An introduction tutorial teaches us how to scrape using Beautiful Soup or Scrapy on simple HTML data. After completion, we think to ourselves, "Finally, all the data in the World Wide Web is mine."
Then BAM, the first page you want to scrape, is a dynamic webpage.
From there, you will probably start reading about "how you need Selenium," but first, you need to learn Docker. The problem then gets messier because you're using a Windows machine, so is the community version even supported? The result is an avalanche of more unanswered questions, and we abandon the project altogether.
I'm here to tell you that there is a technique that lies between using HTML scraping tools and learning Selenium that you can try before jumping ship. Best of all, it's probably a technology you already know - Requests.
Goals:
By the end of this tutorial, you'll learn how to mimic a website's request to get more HTML pages or JSON data.
Disclaimer, in some cases, the website will still need to use Selenium or other technologies for web scraping.
Overview:
The method is a three-step procedure.
- First, we will check if the website is the right candidate for this technique.
- Second, we will examine the request and return data using Postman.
- Third, we will write the python code.
Tools and prereqs:
Postman
A basic understanding of Web Scraping
A basic understanding of Python's Requests library
Step 1
My browser is Firefox, but I'm sure Chrome has a similar feature. Under the Web developer option, select the network option.
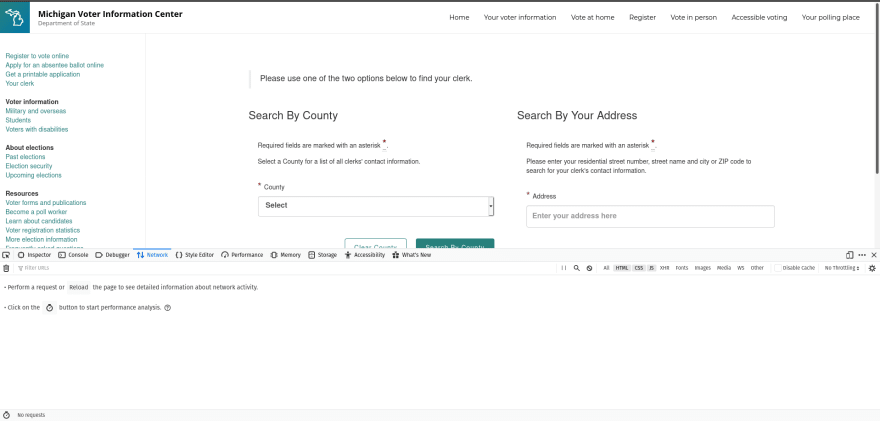
Generate dynamic data and examine the requests. For my example webpage, you can invoke this by selecting an option.
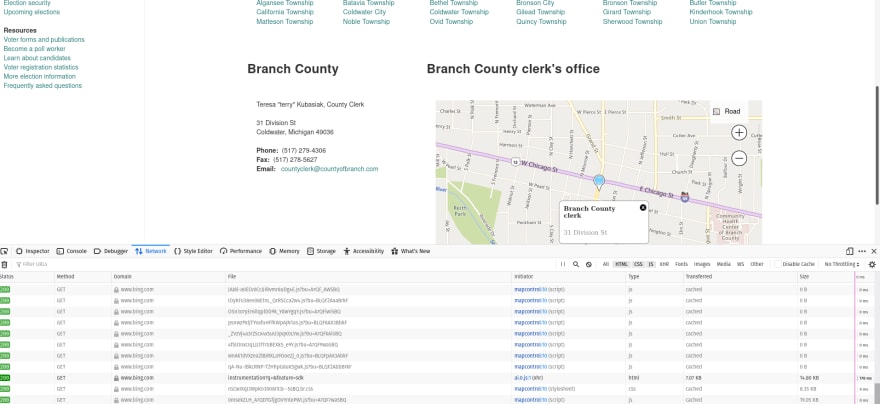
Now, you might have noticed that many requests are happening. So how do you find the one you need? The trick here is to look at the type and the response itself. In my example, there are many js (Javascript) types and two HTML types. Since we are trying to avoid dealing with Javascript, it is a natural move for us first to inspect the two HTML options.
Luckily, the first HTML type is the request we need. We can tell that it's the right choice because we can see the data we want in the response.
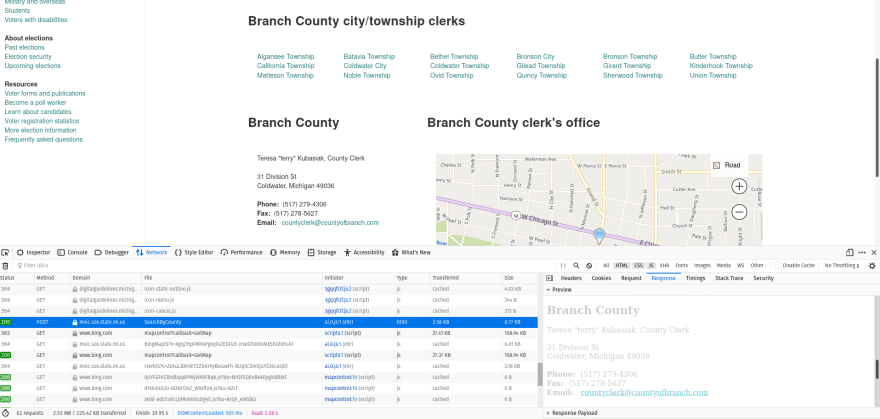
Step 2
Next, we will use Postman to mimic the request. We do this to isolate, inspect, and confirm that this is the data we need.
With Firefox, we right-click to copy and select the URL option.Then paste into Postman with the right request type.

Right-click to copy and select data form.
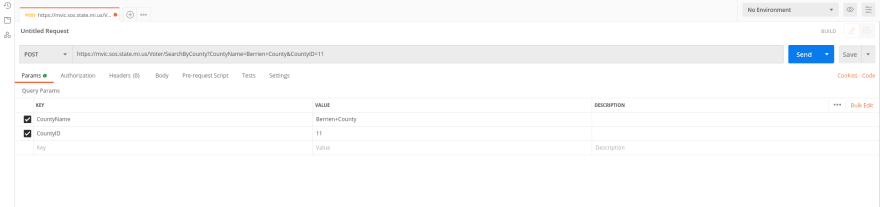
In some cases, you might need to add something to the header, but Postman autocompletes a lot. So in this example, it's not necessary.
Then run it.
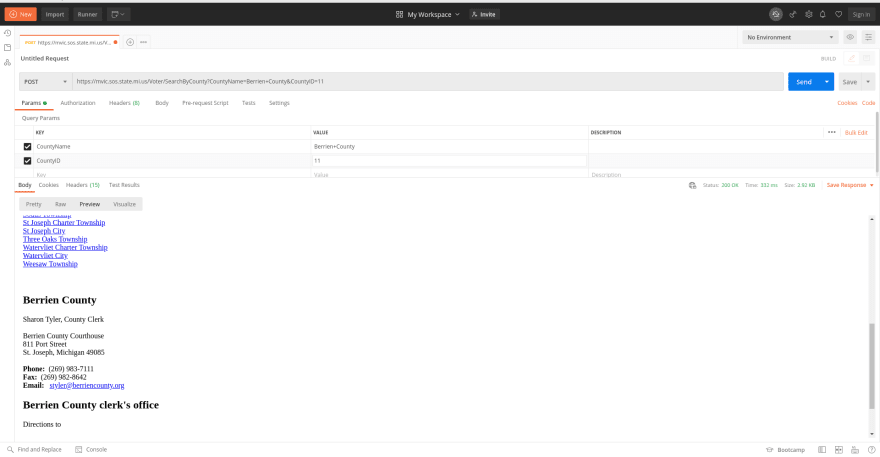
The data looks good. It's a dedicated HTML page that we can scrape.
Step 3
The last step is writing the python code. Because this isn't a Request or Python tutorial, I'm not going to get detailed in this step, but I will tell you what I did.
I messed with the requests a bit and realized that I could get the same data without the county code, so my data form is numerical. Which means using a range is just fine.
Here is my code for creating a request that gets all the HTML for all those pages.
import requests
import json
request_list = []
for i in range(1,84):
response = requests.post(f"https://mvic.sos.state.mi.us/Voter/SearchByCounty?CountyID={i}", verify=False)
request_list.append(response.text)
With this, we can use a combination of an HTML parser and requests to retrieve dynamic data.
BONUS tip:
Here is a website that can turn cURL requests into Python code.
Cool, right? You can use this if your request is simple, or you just are feeling lazy. Be warned, it doesn't work all the time, and some headers may need to be adjusted still.
Conclusion
We went over how to use a web browser, Postman, and the Request library to continue your web scraping journey. An intermediate technique for those who are learning Web Scraping. Good Luck!

Top comments (0)