
Prerequisites
- Source code for this blog
- Python support
Layout of this guide
- Motivation
- Introduction
- Character Stream
- Prefix Checking (peek, current, advance)
- Recursive Descent
- Error handling
- Skipping white space
- Imports
- From Back-end To Front-end
- The Object Scope
- Flags
- Method Chaining
- Interpreting empty object
- Scoping
- Expressions
- Wrapping up Method Chaining
- Conclusion
- References
Source code for this blog:
the little utility library we use:
Python Support
In this blog, we use Python v3.8.x but you can use v3.5 or greater. Note that the type annotation has been supported since 3.5.
This blog is a good quick start for any developer interested in building the first prototype of their own language. Advanced Python skills are, of course, optimal.
Motivation
I have recently taken a lot of interest in how a prototype of cue language most model-driven applications use behind the scenes. Just the basics of it. But even the basics seemed complicated in my eyes. So I wanted to make it seem simple and sharpen up my understanding of the language along the way. This has worked wonders for me in many ways. From why we can write
foo:bar:zoo: 1
to why JavaScript throws an error on:
console.log('hi!')
(10 + 10) * 1
/*
* Uncaught TypeError: console.log(...) is not a function
at <anonymous>:3:1
*/
Introduction
As developers, we’d always like to try our hand at building and customizing our own toolkit – whether that is out of curiosity or out of necessity.
This blog will give you some guidelines and basic knowledge on how to build your own basic language, in our case a Jsonic language, and customize it to your needs. A Jsonic Language is a JSON-like language with fun but useful syntax features such as expressions, scoping, calling functions, etc.
Upon reading this blog, not only will you understand the basics of how to build an advanced Jsonic language but you will use simple algorithms to do so, which will increase productivity and decrease confusion!
The prototype of our language is in Python but we try to be as abstract as possible so that you can pick a language of your choice to build your own version of this language. Of course, things like garbage collectors are built-in so we won’t cover that if you want to work with languages like C.
Character Stream
To cut right to the chase, we will leave out the implementation of the CharStream class and just demonstrate its functionality. You have the source code as your friend – in fact, the CharStream class is very straightforward and is the core of our project to begin with.
char_stream = CharStream("welcome!")
char_stream.peek() == 'w' # True
char_stream.advance()
char_stream.peek() == 'e' # True
For prefix checking, we use peek() and current methods of the CharStream class and then consume characters with advance() that moves one character ahead and returns the current one.
Compare it to Python built-in iter:
stream = iter("welcome")
next(stream) == 'w'
next(stream) == 'e' # it is 'e' now - there isn't really a way to check the current char but not advance
Prefix checking
If the character stream peeks for a certain character, we could easily determine the type of that token right away, roll with it until the while loop is done, and just evaluate it.
We will be applying scanning, parsing and evaluation all in one go and on the fly – that's to say we are not going to generate Lexer and AST per ser. Instead, we jump straight to interpreting our object.
For a start:
def interpret_obj(char_stream: CharStream, advance: bool, ...):
if advance:
char_stream.advance()
skip_space(char_stream)
if char_stream.peek().isdigit():
value = ''
while char_stream.peek().isdigit():
value += char_stream.advance()
skip_space(char_stream)
return int(value, 10) # base 10
...
Snippet 1
Here, the bool advance parameter will be a help because each time we match a certain character, we might forget to consume it – so we pass True and, if necessary, False.
We come back to this logic to sort out identifiers and also introduce the flags.
def scan_id(char_stream: CharStream, advance: bool):
if advance:
char_stream.advance()
value = ''
if not char_stream.peek().isalpha():
raise SyntaxError("Expected an identifier to start with an alpha")
while char_stream.peek().isalpha() or char_stream.peek().isdigit():
value += char_stream.advance()
return value
def interpret_obj(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
...
elif char_stream.peek().isalpha() and flags.temFlag:
identifier = scan_id(char_stream, False)
skip_space(char_stream) # clear up the following white space
if flags.isKey:
return identifier
if identifier not in scope.keys():
raise NameError(identifier + " not defined!")
return scope[identifier]
...
Snippet 2
What’s more, utils.Map is similar to typical dict except that its values are not accessed just using obj['key1'] but using either obj.key1 or obj['key1'] which is, more JavaScript-like.
Check out the Python docs on setattr, getattribute and getitem, dict. More on Flags – on Flags section.
RECURSIVE DESCENT
Our little language will only use one main algorithm and still be good enough to support advanced syntax features such as: scoping, method chaining, expressions, and calling functions.
In this series, we prioritize typical JSON data that is: null, Number, String, Object, and Array.
However, this guide only shows you how to support Numbers as it is easier to make complete sense of it and you can use those same methods to scan the other types. They will easily fit the rest of the code – you just need to write a few conditions to identify those types.
For example, Arrays start with the character [ and end with ] while strings start and end with ".
Don't sweat it! This is a blog series so there will be more to come.
Error handling
It is important to detect the syntax errors. The way to handle them is by throwing exceptions!
Throwing exceptions for this kind of algorithm is ideal as it will stop all the recursive calls up to the base call no matter the depth.
Skipping white-space
To skip the white space, we simply peek for ' ' or '\n' and advance to the next character.
def skip_space(char_stream: CharStream):
while not char_stream.is_over() and (char_stream.peek() == ' ' or char_stream.peek() == '\n'):
char_stream.advance() # consume the white space
Snippet 3
Imports
In this blog, we use: sys, utils and parser.
import sys # built-in python sys module
import utils # this-project-specific set of utilities – see examples: https://github.com/BeAllAround/py_utils
from parser import CharStream # library that will help us with scanning/lexical analysis
Snippet 4
We recommend that you write your own back-end libraries as much as you can. It makes your language open to bigger features like merging nested objects such as: { a: 1, { b: 2 } } and others.
From back-end to front-end
For us, the front-end would be scanning and parsing the text so that we could evaluate it with the back-end modules:
front-end – scanning and parsing
back-end – evaluation
front-end + back-end – interpretation
Python itself is the back-end engine of this language for its built-in error handling system and methods under the hood of dict, str, list such as add, eq, getitem, etc. but we are going to take a step back and focus on the modules that are not built-in.
When scanning and parsing, we have to think about the evaluation. That is when utilities come into play depending on what we want to do.
A great example would be the deep extend function for merging objects.
merge({foo: {a: 1}}, {foo: {b:2}}) => {foo: {a: 1, b: 2}}
With that in mind, we would need a function to merge two objects, as the ones in the example above.
utils.deep_update(obj1, obj2)
The Object Scope
The aim of our language would be interpreting the object. Now that we know how to apply the prefix checking, we are all set to kick off!
If we try to interpret: "{1: 1}"
def interpret_obj(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
if advance:
char_stream.advance();
...
elif char_stream.peek() == '{':
obj = {}
while True:
key = interpret_obj(char_stream, True, scope, utils.Map({'temFlag': True, 'isKey': True,}) ) # key == 1
skip_space(char_stream)
if char_stream.peek() == ':':
value = interpret_obj(char_stream, True, obj, utils.Map({'temFlag': True, 'isKey': False,}) )
utils.deep_update(obj, { key: value }) # obj now equals to "{1: 1}" – see docs: https://github.com/BeAllAround/py_utils
if char_stream.peek() == '}':
char_stream.advance() # eat '}'
skip_space(char_stream)
return obj
elif char_stream.peek() == ',':
continue
else:
raise SyntaxError("Unexpected char " + char_stream.current)
else:
raise SyntaxError("Unexpected char " + char_stream.current)
else:
raise SyntaxError("Unexpected char " + char_stream.current)
Snippet 5
Flags
To enable and register features, we could simply use an instance of utils.Map that will contain the flags for us to use.
We could pass Booleans to our function but that would be very hard to maintain.
Compare the following two snippets:
def interpret_obj(char_stream: CharStream, ..., flags: utils.Map):
...
value = interpret_obj(char_stream, ..., utils.Map({'temFlag': True,
'isKey': False,}) )
...
Snippet 6
def interpret_obj(char_stream: CharStream, ..., temFlag = False, isKey = False):
...
value = interpret_obj(char_stream, ..., True, False)
...
Snippet 7
As you can see, the former significantly improves readability and would simplify adding new flags as you pick up new features.
Still, this approach isn’t great and would require a bit of refactoring, which we can look at in the next volume of this series.
Method Chaining
For method chaining, we will need another infinite loop that breaks if none of our existing conditions match.
value_ptr – is just an array of one element that tries to mimic a pointer in Python or other scripting languages that don’t really have an equal.
It will help us achieve the following:
a = 1
def modify_a(a):
a = 2
modify_a(a)
> a # still 1 but we need it to be 2
Snippet 8
But at least, it mimics pointers in that regard:
a = [ 1 ]
def modify_a(value_ptr):
value_ptr[0] = 2
modify(a)
> a[0] # our main value is now 2
Snippet 9
def chain_obj(char_stream: CharStream, value_ptr: list, scope: dict):
while True:
if callable(value_ptr[0]) and char_stream.peek() == '(':
args = [] # a place to store the evaluated arguments
# evaluating "func()"
cs = CharStream(char_stream.source, char_stream.c)
char_stream.advance()
skip_space(char_stream) # evaluate "func( )"
if char_stream.peek() == ')':
char_stream.advance() # eat ')'
skip_space(char_stream)
value_ptr[0] = value_ptr[0]() # evaluate the function with no arguments passed
continue
else:
char_stream.set_cs(cs) # reset the char stream to last matched '('
while True:
args.append(parse_obj(char_stream, True, scope, utils.Map({'temFlag': True, 'isKey': False,}) )
if char_stream.peek() == ',':
continue
elif char_stream.peek() == ')':
char_stream.advance() # eat ')'
skip_space(char_stream)
value_ptr[0] = value_ptr[0](*args) # evaluate the function with x number of arguments passed
break
else:
raise SyntaxError("Unexpected char while evaluating a function: " + char_stream.current)
elif type(value_ptr[0]) == dict and char_stream.peek() == '.':
identifier = scan_id(char_stream, True)
skip_space(char_stream)
value_ptr[0] = value_ptr[0][identifier]
continue
else:
break
Snippet 10
This code implements obj.a.b, obj.a().b, func(1, 2), "func()() - calling functions" and vice versa depending on what you want to do.
Since our language does not support function definition, we need to pass in Python functions. After all, this will come in handy as you can add up any Python code and use it from the language code itself.
Formally, we provide some "context".
For example:
def json_export():
scope = {'func': lambda x,y: x+y,} # our language can call functions
default_flags = utils.Map({})
utils.export_json( interpret_obj(CharStream('{' + input() + '}'), False, scope, default_flags) )
# Note that 'utils.export_json' is a custom alternative to 'json.dump' from Python Standard Library
# more details on that here: https://docs.python.org/3/library/json.html
Snippet 11
While on the point of printing out our final object, there is an interesting detail to point out. That is, Python actually uses sys.stdout.write(obj.repr() + '\n') to convert an object to a string and, then, show it to the console.
In this snippet, we used utils.export_json just that print uses single quotation marks to encode Python strings. "a" will be 'a' – which isn't standard JSON.
Generating out the JSON data for reuse:
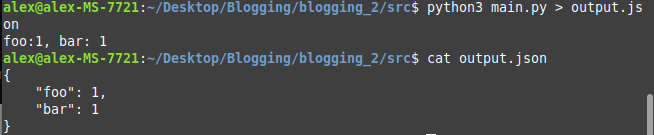
To further customize our formatting, you could code your own object_to_string function:
def object_to_string(obj: dict):
# handle obj
return str(...)
# Afterwards, you can add it up like this:
print(object_to_string(interpret_obj(CharStream('{' + input() + '}'), False, scope, default_flags)))
Snippet 12
To get a better sense of how you could format your object with somewhat a simple set of rules, check out the implementation of utils.export_json from the source code.
To enable the method chaining, we would turn a part of the code from Snippet 5 into:
...
if char_stream.peek() == ':':
value = interpret_obj(char_stream, True, scope, utils.Map({ 'isKey': False, 'temFlag': True, }) )
value_ptr = [ value ]
chain_main(char_stream, value_ptr, scope)
value = value_ptr[0]
utils.deep_update(obj, { key: value })
...
Snippet 13
Or we could wrap it inside a single function for reusability.
def interpret_obj_and_chain(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
value = interpret_obj(char_stream, advance, scope, flags)
value_ptr = [ value ]
chain_obj(char_stream, value_ptr, scope)
return value_ptr[0] # return the final value
Snippet 14
Now, a part of Snippet 5 translates into
...
if char_stream.peek() == ':':
value = interpret_obj_and_chain(char_stream, True, scope, utils.Map({'temFlag': True, 'isKey': False,}) )
utils.deep_update(obj, { key: value })
...
Snippet 15
Interpreting empty object
There is a special case we have yet to set. That is, interpreting {}
Let's turn a piece of Snippet 5 into
def interpret_obj(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
...
elif char_stream.peek() == '{':
obj = {}
# interpreting "{}"
cs = CharStream(char_stream.source, char_stream.c)
char_stream.advance()
skip_space(char_stream) # with this, we can interpret "{ }"
if char_stream.peek() == '}':
char_stream.advance() # eat '}'
skip_space(char_stream)
return obj
else:
char_stream.set_cs(cs) # trace the char_stream back to last matched '{' and proceed
...
Snippet 16
Scoping
Scoping, most of all, enables you to use the predefined context as detailed in Snippet 11.
To make sure we don’t mutate our context, we are going to make a copy of it into obj_scope and, from then on, use it as a dictionary to get items from.
Let’s work on Snippet 5 a bit further.
def interpret_obj(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
...
elif char_stream.peek() == '{':
obj = {}
obj_scope = {}
...
utils.deep_update(obj_scope, scope)
...
if char_stream.peek() == ':':
value = interpret_obj_and_chain(char_stream, True, obj_scope, utils.Map({ 'temFlag': True, 'isKey': False, }) )
utils.deep_update(obj_scope, { key: value })
utils.deep_update(obj, { key: value })
...
...
...
Snippet 17
Expressions
For a start, think of it as a desk calculator! We first have to handle basic arithmetic operations: multiplication, division, addition, and subtraction.
Consider: (3 + 3) * ( 3 * 3)
To achieve this, we need to prioritize multiplication and division over addition and subtraction; expr revolving around term with term revolving around prim.
In computer science, the term is Operator-precedence parser or just precedence.
def expr(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
left = term(char_stream, advance, scope, flags)
while True:
if char_stream.peek() == '+':
left += term(char_stream, True, scope, flags)
elif char_stream.peek() == '-':
left -= term(char_stream, True, scope, flags)
else:
return left
def term(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
left = prim(char_stream, advance, scope, flags)
while True:
if char_stream.peek() == '*':
left *= prim(char_stream, True, scope, flags)
elif char_stream.peek() == '/':
left /= prim(char_stream, True, scope, flags)
else:
return left
def prim(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
if advance:
char_stream.advance()
skip_space(char_stream)
if char_stream.peek() == '(': # enable ((2 * 2) + 1)
value = expr(char_stream, True, scope, flags)
if char_stream.peek() != ')':
raise SyntaxError("Missing ')'")
char_stream.advance() # eat ')'
skip_space(char_stream)
return value
return interpret_obj_and_chain(char_stream, False, scope, flags) # use the complete variant of interpret_obj with method chaining
Snippet 18
Our function can be illustrated using either AST or Parse Tree.
Visually, we have:

To cap it off, let’s replace interpret_obj_and_chain with this new function!
Back to Snippet 5:
def interpret_obj(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
...
elif char_stream.peek() == '{':
...
if char_stream.peek() == ':':
value = expr(char_stream, True, obj_scope, utils.Map({ 'temFlag': True, 'isKey': False, }) )
...
...
...
Snippet 19
Additionally, don’t forget to call expr from chain_obj as well – particularly instead of interpret_obj when getting a function arguments.
For example, interpreting { f: func(1+1, 2*2) } would require:
args.append( expr(char_stream, True, scope, utils.Map({'temFlag': True, 'isKey': False,}) )
Wrapping Up Method Chaining
Now, if we write {c: {b: 1, d: {a: 21}}, d1: (c.d.a)*2+1 } – that works giving us the correct result. But what if we tried to write ((c.d).a) instead of just (c.d.a). Well, that easy to implement! If you retrace your steps back to prim – you will find the part that matches parentheses and hit the nail on the head! That’s the block of code we need to work on!
def prim(char_stream: CharStream, advance: bool, scope: dict, flags: utils.Map):
...
if char_stream.peek() == '(': # enable ((2 * 2) + 1)
value = expr(char_stream, True, scope, flags)
value_ptr = [ value ]
if char_stream.peek() != ')':
raise SyntaxError("Missing ')'")
char_stream.advance() # eat ')'
skip_space(char_stream)
chain_obj(char_stream, value_ptr, scope) # just enable method-chaining
value = value_ptr[0] # the final value
return value
...
Snippet 20
Next, go ahead and try (c.d).a !
Because of our recursion logic, we also must not forget to check for unmatched characters if there are extra characters, which should produce an error - for example: {}}, ()) and similar.
In that case, we have:
def interpret_object(stream: CharStream, scope: dict):
default_flags = utils.Map({})
obj = interpret_obj(stream, False, scope, default_flags)
if not stream.is_over():
raise SyntaxError('unmatched ' + stream.current)
return obj
def main():
text = CharStream(r'''{}''')
# text = Char_stream(r'''{}}''') # we now get "SyntaxError('unmatched }')"
scope = { 'func': lambda x,y: x+y, 'func1': lambda: print('hi!'), }
obj = interpret_object(text, scope)
utils.export_json(obj)
Snippet 21
Conclusion
Understanding how programming languages work opens up many opportunities in the computer science world by introducing you to natural language processing, pattern matching, evaluation, compilers, interpreters, etc.
It helps you picture how each expression you have written is processed before you even hit the enter key trying to run just a few lines of code – it can inspire you to put the programming language you are using under the microscope for the first time.
There is plenty of room to structure and improve our code. One of the ways is to lean towards OOP, which is exactly what the next volume will be about – one step at a time!
We wish you luck with the prototype of your language and look forward to sharing more advanced guidance with you soon.
Let us know about any typos and your takeaways in the comments.

Top comments (1)
I am always here for a good parser article.