Azure Cosmos DB is a fully managed, elastically scalable and globally distributed database with a multi-model approach, and provides you with the ability to use document, key-value, wide-column, or graph-based data.
We will drill further into the multi-model capabilities and explore the options that are available to store and access data. Hopefully, it can help you make an informed decision on the right API are the right choice.
- Core (SQL) API: Flexibility of a NoSQL document store combined with the power of SQL for querying.
- MongoDB API: Supports the MongoDB wire protocol so that existing MongoDB client continue to work with Azure Cosmos DB as if they are running against an actual MongoDB database.
- Cassandra API: Supports the Cassandra wire protocol so that existing Apache drivers compliant with CQLv4 continue to work with Azure Cosmos DB as if they are running against an actual Cassandra database.
- Gremlin API: Supports graph data with Apache TinkerPop (a graph computing framework) and the Gremlin query language.
- Table API: Provides premium capabilities for applications written for Azure Table storage.
You can read further on the some of the Key Benefits
Before diving in, let's look at some of the common scenarios which Azure Cosmos DB is used for. This is by no means, an exhaustive list.
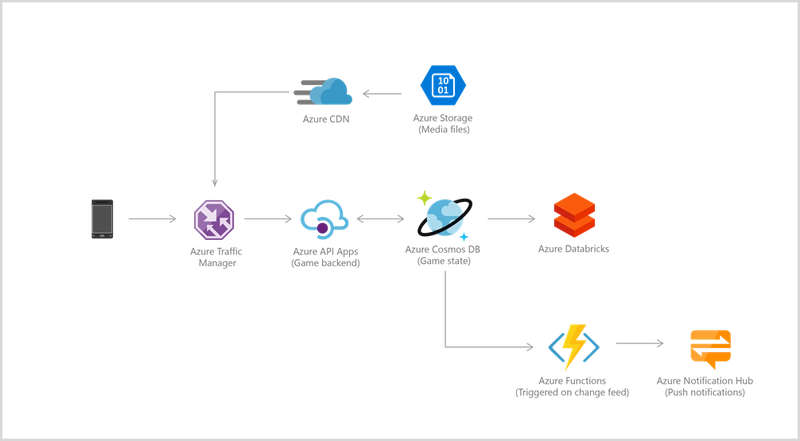
Modern gaming services need to deliver customized and personalized content like in-game stats, social media integration, and high-score leaderboards. As a fully managed offering, Azure Cosmos DB requires minimal setup and management to allow for rapid iteration, and reduced time to market.
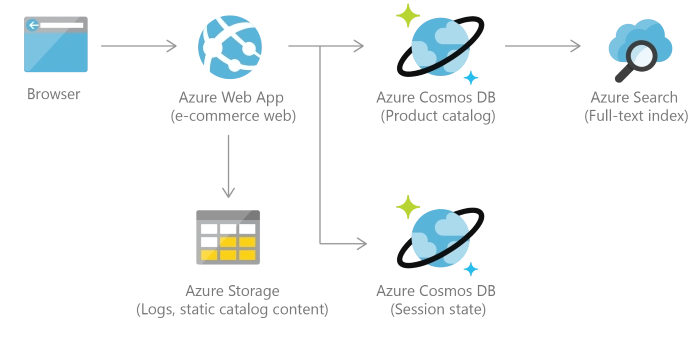
E-commerce platforms and retail applications store catalog data and for event sourcing in order processing pipelines.
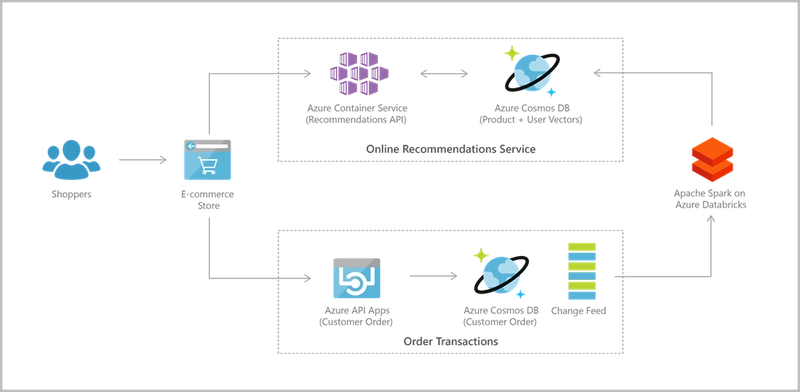
Applications that provide personalized experiences can be quiet complex. They need to be able to retrieve user specific settings effectively to render UI elements and experiences quickly.
Which API to use, and when?
There is no perfect formula! At times, the choice will be clear, but other scenarios may require some analysis.
A rather obvious point to consider is, whether there are existing applications that use any of the supported APIs via the wire protocol (i.e. Cassandra and MongoDB)? If the answer is yes, you should consider using the specific Azure Cosmos DB API, as that will reduce your migration tasks, and make the best use of previous experience in your team.
If you expect the schema to change a lot, you may want to leverage a document database, making Core (SQL) a good choice (although the MongoDB API should also be considered).
If your data model consists of relationships between entities with associated metadata, you're better off using the graph support in Azure Cosmos DB Gremlin API.
If you are currently using Azure Table Storage, the Core (SQL) API would be a better choice, as it offers a richer query experience, with improved indexing over the Table API. If you don't want to rewrite your application, consider migrating to the Azure Cosmos DB Table API.
Let's look each of the APIs and apply some of this.
Core (SQL) API: best of both worlds
Core (SQL) API is the default Azure Cosmos DB API. You can store data using JSON documents to represent your data, but there are a couple ways you can retrieve it:
- SQL queries: Write queries using the Structured Query Language (SQL) as a JSON query language
- Point reads: Key/value style lookup on a single item ID and partition key (these are cheaper and faster than SQL queries)
For many applications, semi-structured data model can provide the flexibility they need. For example, an e-commerce setup with large number of product categories. You will need to add new product categories and support operations (search, sort etc.) across many product attributes. You can model this with a relational database, but, the constantly evolving product categories may require downtime to update the table schemas, queries, and databases.
With the Core (SQL), introducing a new product category is as simple as adding a document for the new product without schema changes or downtimes. The Azure Cosmos DB MongoDB API is also suitable for these requirements, but Core (SQL) API has an advantage since it's supports SQL-like queries on top of a flexible data model.
Consider the example of a blogging platform where users can create posts, like and add comments to those posts.
You can represent a post as such:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
As well as comments and likes:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
To handle likes and comments, you can use a stored procedure:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
If you want to learn more, refer to Working with JSON in Azure Cosmos DB
Migrate from an existing MongoDB instance
Azure Cosmos DB implements the wire protocol for MongoDB which allows transparent compatibility with native MongoDB client SDKs, drivers, and tools. This means that any MongoDB client driver (as well as existing tools such as Studio 3T) that understands this protocol version should be able to natively connect to Cosmos DB.
For example, if you have an existing MongoDB database as the data store for purchase orders processing application to capture failed and partial orders, fulfillment data, shipping status with different formats. Due to increasing data volumes, you want to migrate to a scalable cloud based solution and continue using MongoDB - It makes perfect sense to use Azure Cosmos DB's API for MongoDB. But you will want to do so with minimal code changes to the existing application and migrate the current data with as little downtime as possible.
With Azure Database Migration Service, you can perform an online (minimal downtime) migration and elastically scale the provisioned throughput and storage for your Cosmos databases based on your need and pay only for the throughput and storage you need. This leads to significant cost savings.
Refer to the pre and post-migration guides.
Once you've migrated your data, you can continue to use your existing application. Here is an example using MongoDB .NET driver:
Initialize the client:
MongoClientSettings settings = new MongoClientSettings();
settings.Server = new MongoServerAddress(host, 10255);
settings.UseSsl = true;
settings.SslSettings = new SslSettings();
settings.SslSettings.EnabledSslProtocols = SslProtocols.Tls12;
MongoIdentity identity = new MongoInternalIdentity(dbName, userName);
MongoIdentityEvidence evidence = new PasswordEvidence(password);
settings.Credential = new MongoCredential("SCRAM-SHA-1", identity, evidence);
MongoClient client = new MongoClient(settings);
Retrieve the database and the collection:
private string dbName = "Tasks";
private string collectionName = "TasksList";
var database = client.GetDatabase(dbName);
var todoTaskCollection = database.GetCollection<MyTask>(collectionName);
Insert a task into the collection:
public void CreateTask(MyTask task)
{
var collection = GetTasksCollectionForEdit();
try
{
collection.InsertOne(task);
}
catch (MongoCommandException ex)
{
string msg = ex.Message;
}
}
Retrieve all tasks:
collection.Find(new BsonDocument()).ToList();
You should also carefully consider how MongoDB write/read concerns are mapped to the Azure Cosmos consistency levels, manage indexing and leverage Change feed support.
Please note that the Core (SQL) API would have been an appropriate choice if there wasn't a requirement to reuse existing code and import data from existing MongoDB database.
Handle real-time data with Cassandra
If your application needs to handle high volume, real-time data, Apache Cassandra is an ideal choice. With Azure Cosmos DB Cassandra API, you can use existing Apache drivers compliant with CQLv4, and in most cases, you should be able to switch from using Apache Cassandra to using Azure Cosmos DB's Cassandra API, by just changing a connection string. You can also continue to use Cassandra-based tools such as cqlsh.
For advanced analytics use cases, you should combine Azure Cosmos DB Cassandra API with Apache Spark. You can use the familiar Spark connector for Cassandra to connect to Azure Cosmos DB Cassandra API. Additionally, you will also need the azure-cosmos-cassandra-spark-helper helper library from Azure Cosmos DB for features such as custom connection factories and retry policies.
It's possible to access Azure Cosmos DB Cassandra API from Azure Databricks as well as Spark on YARN with HDInsight
To connect to Cosmos DB, you can use the Scala API as such:
import org.apache.spark.sql.cassandra._
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql.CassandraConnector
import com.microsoft.azure.cosmosdb.cassandra
spark.conf.set("spark.cassandra.connection.host","YOUR_ACCOUNT_NAME.cassandra.cosmosdb.azure.com")
spark.conf.set("spark.cassandra.connection.port","10350")
spark.conf.set("spark.cassandra.connection.ssl.enabled","true")
spark.conf.set("spark.cassandra.auth.username","YOUR_ACCOUNT_NAME")
spark.conf.set("spark.cassandra.auth.password","YOUR_ACCOUNT_KEY")
spark.conf.set("spark.cassandra.connection.factory", "com.microsoft.azure.cosmosdb.cassandra.CosmosDbConnectionFactory")
spark.conf.set("spark.cassandra.output.batch.size.rows", "1")
spark.conf.set("spark.cassandra.connection.connections_per_executor_max", "10")
spark.conf.set("spark.cassandra.output.concurrent.writes", "1000")
spark.conf.set("spark.cassandra.concurrent.reads", "512")
spark.conf.set("spark.cassandra.output.batch.grouping.buffer.size", "1000")
spark.conf.set("spark.cassandra.connection.keep_alive_ms", "600000000")
You can perform aggregations, such as average, min/max, sum etc.:
spark
.read
.cassandraFormat("books", "books_ks", "")
.load()
.select("book_price")
.agg(avg("book_price"))
.show
spark
.read
.cassandraFormat("books", "books_ks", "")
.load()
.select("book_id","book_price")
.agg(min("book_price"))
.show
spark
.read
.cassandraFormat("books", "books_ks", "")
.load()
.select("book_price")
.agg(sum("book_price"))
.show
Connect everything using the Gremlin (Graph) API
As part of a personalized customer experience, your application may need to provide recommendations for products on the website. For example, "people who bought product X also bought product Y". Your use cases might also need to predict customer behavior, or connect people with others with similar interests.
Azure Cosmos DB supports Apache Tinkerpop's graph traversal language (known as Gremlin). There are many use cases with give rise to common problems associated with lack of flexibility and relational approaches. For example, managing connected social networks, Geospatial use cases such as finding a location of interest within an area or locate the shortest/optimal route between two location, or modelling network and connections between IoT devices as a graph in order to build a better understanding of the state of your devices and assets. On top of this, you can continue to enjoy features common to all the Azure Cosmos DB APIs such as global distribution, elastic scaling of storage and throughput, automatic indexing and query and tunable consistency levels.
For example, you could use the following commands to add three vertices for product and two edges for related-purchases to a graph:
g.addV('product').property('productName', 'Industrial Saw').property('description', 'Cuts through anything').property('quantity', 261)
g.addV('product').property('productName', 'Belt Sander').property('description', 'Smoothes rough edges').property('quantity', 312)
g.addV('product').property('productName', 'Cordless Drill').property('description', 'Bores holes').property('quantity', 647)
g.V().hasLabel('product').has('productName', 'Industrial Saw').addE('boughtWith').to(g.V().hasLabel('product').has('productName', 'Belt Sander'))
g.V().hasLabel('product').has('productName', 'Industrial Saw').addE('boughtWith').to(g.V().hasLabel('product').has('productName', 'Cordless Drill'))
Then, you can query the additional products that were purchased along with the 'Industrial Saw':
g.V().hasLabel('product').has('productName', 'Industrial Saw').outE('boughtWith')
Here is what the results will look like:
[
{
"id": "6c69fba7-2f76-421f-a24e-92d4b8295d67",
"label": "boughtWith",
"type": "edge",
"inVLabel": "product",
"outVLabel": "product",
"inV": "faaf0997-f5d8-4d01-a527-ae29534ac234",
"outV": "a9b13b8f-258f-4148-99c0-f71b30918146"
},
{
"id": "946e81a9-8cfa-4303-a999-9be3d67176d5",
"label": "boughtWith",
"type": "edge",
"inVLabel": "product",
"outVLabel": "product",
"inV": "82e1556e-f038-4d7a-a02a-f780a2b7215c",
"outV": "a9b13b8f-258f-4148-99c0-f71b30918146"
}
]
In addition to traditional clients, you can use the graph bulk executor .NET library to perform bulk operations in Azure Cosmos DB Gremlin API. Using this will improve the data migration efficiency as compared to using a Gremlin client. Traditionally, inserting data with Gremlin will require the application send a query at a time that will need to be validated, evaluated, and then executed to create the data. The bulk executor library will handle the validation in the application and send multiple graph objects at a time for each network request. Here is an example of how to create Vertices and Edges:
IBulkExecutor graphbulkExecutor = new GraphBulkExecutor(documentClient, targetCollection);
BulkImportResponse vResponse = null;
BulkImportResponse eResponse = null;
try
{
vResponse = await graphbulkExecutor.BulkImportAsync(
Utils.GenerateVertices(numberOfDocumentsToGenerate),
enableUpsert: true,
disableAutomaticIdGeneration: true,
maxConcurrencyPerPartitionKeyRange: null,
maxInMemorySortingBatchSize: null,
cancellationToken: token);
eResponse = await graphbulkExecutor.BulkImportAsync(
Utils.GenerateEdges(numberOfDocumentsToGenerate),
enableUpsert: true,
disableAutomaticIdGeneration: true,
maxConcurrencyPerPartitionKeyRange: null,
maxInMemorySortingBatchSize: null,
cancellationToken: token);
}
catch (DocumentClientException de)
{
Trace.TraceError("Document client exception: {0}", de);
}
catch (Exception e)
{
Trace.TraceError("Exception: {0}", e);
}
Although it is possible to model and store this data using the Core (SQL) API as JSON documents, it's not suitable for queries which need to determine relationships between entities (e.g. products).
You may want to explore Graph data modeling as well as data partitioning for the Azure Cosmos DB Gremlin API.
Azure Table Storage on steroids!
If you have existing applications written for Azure Table storage, they can be migrated to Azure Cosmos DB by using the Table API with no code changes and take advantage of premium capabilities.
Moving your database from Azure Table Storage into Azure Cosmos DB with a low throughput could bring lots of benefits in terms of latency (single-digit millisecond for reads and writes), throughput, global distribution, comprehensive SLAs and as well as cost (you can use consumption-based or provisioned capacity modes. Storing table data in Cosmos DB automatically indexes all the properties (without an index management overhead) as opposed to Table Storage that only allows for indexing on the Partition and Row keys.
The Table API has client SDKs available for .NET, Java, Python, and Node.js. For example, with the Java client, use a connection string to store the table endpoint and credentials:
public static final String storageConnectionString =
"DefaultEndpointsProtocol=https;" +
"AccountName=your_cosmosdb_account;" +
"AccountKey=your_account_key;" +
"TableEndpoint=https://your_endpoint;" ;
.. and perform CRUD (create, read, update, delete) operations as such:
try
{
CloudStorageAccount storageAccount =
CloudStorageAccount.parse(storageConnectionString);
CloudTableClient tableClient = storageAccount.createCloudTableClient();
CloudTable cloudTable = tableClient.getTableReference("customers");
cloudTable.createIfNotExists();
for (String table : tableClient.listTables())
{
System.out.println(table);
}
CustomerEntity customer = ....;
TableOperation insert = TableOperation.insertOrReplace(customer);
cloudTable.execute(insert);
TableOperation retrieve =
TableOperation.retrieve("Smith", "Jeff", CustomerEntity.class);
CustomerEntity result =
cloudTable.execute(retrieve).getResultAsType();
TableOperation del = TableOperation.delete(jeff);
cloudTable.execute(del);
}
Refer to Where is Table API not identical with Azure Table storage behavior? for more details.
Conclusion
Azure Cosmos DB supports offers a lot of options and flexibility in terms of APIs, and has it's pros and cons depending on your use-case and requirements. Although the Core (SQL) is quite versatile and applicable to a wide range of scenarios, if your data is better represented in terms of relationships, then the Gremlin (graph) API is a suitable choice. In case you have existing applications using Cassandra or MongoDB, then migrating them to the respective Azure Cosmos DB APIs provides a path of least resistance with added benefits. In case you want to migrate from Azure Table Storage and do not want to refactor your application to use the Core (SQL) API, remember that you have the option of choosing the Azure Cosmos DB Table API, that can provide API compatibility with Table Storage as well as capabilities such as guaranteed high availability, automatic secondary indexing and much more!

Top comments (0)