
Covering the basics
What is incident management?
Incident management is the process used by developer and IT operations teams to respond to system failures (incidents) and restore normal service operation as quickly as possible.
What is an incident?
Incident is a broad term describing any event that causes either a complete disruption or a decrease in the quality of a given service. Incidents usually require immediate response of the development or operations team, often referred to as on-call or response teams in incident management.
5 parts of the incident management process
1. Monitoring
What is incident monitoring?
Monitoring for incidents is the first part of any incident management process. Monitoring spots problems within the system and verifies that they are indeed being experienced by the end-users. Once a problem has been identified, an incident is created, and depending on the incident alerting the relevant team members are notified.
A common example is monitoring accessibility of a company’s homepage. Such automated checking of a specific website is called a monitor. This monitor will automatically check the website every 30 seconds, and if there is a problem and the website becomes unavailable, it will trigger an alert.
An alert is essentially a notification that includes information about the incident, for example, that the website server was overwhelmed, which might suggest an unexpected spike in traffic.
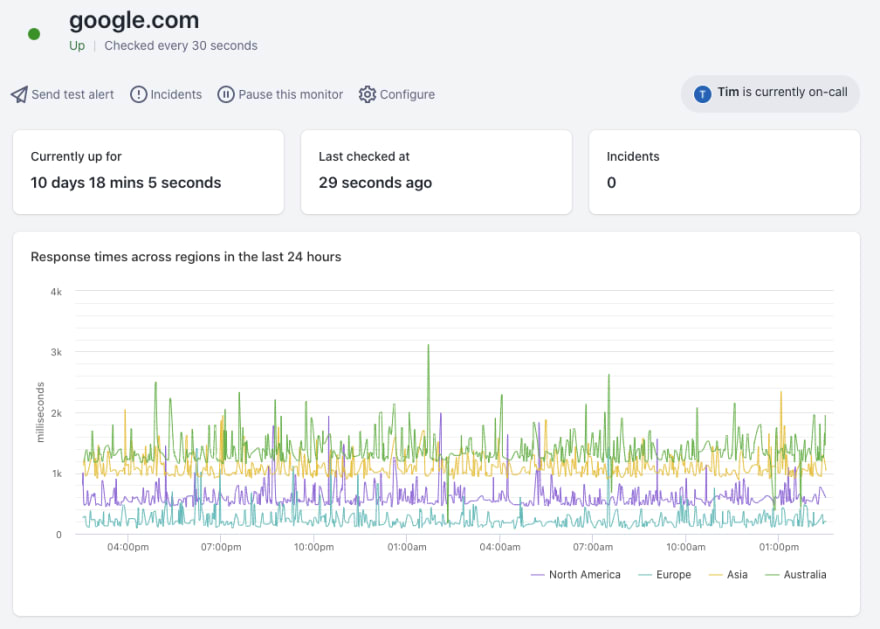
Example of a monitor that checks the availability of google.com.
2. On-call scheduling
What is on-call?
On-call is a practice where designated team members are available to respond to alerts during specific times. Setting up on-call schedules is vital for any incident management as it assures that the correct person will receive the incident alert from the monitor. When someone is ‘on-call’ it means they are the person who will respond to service issues if they arise.
For example, if someone is on-call from 12 AM to 12 PM on Tuesday, it means that if there is an incident during this time, be it at 2 in the afternoon or 3 in the morning, they have to be ready to respond.
The on-call setup is individual for each organization. However, the goal remains the same, make sure that someone on the team is always ready to fix urgent service issues.

Example of a on-call duty system.
3. Alerting
What is IT alerting?
After the monitor spots an incident, it needs to be passed onto the team that is going to solve it. Incident alerting process ensures that the right person is alerted at the right time and in the right way.
An alert is a notification that is automatically sent to a specific team or team member. It can be in the form of an SMS, phone call, push notification, and more depending on the team’s communication processes.
But alerts are not just plain notifications. They often provide detailed information about the incident that might help the team to find the cause and resolve it faster.
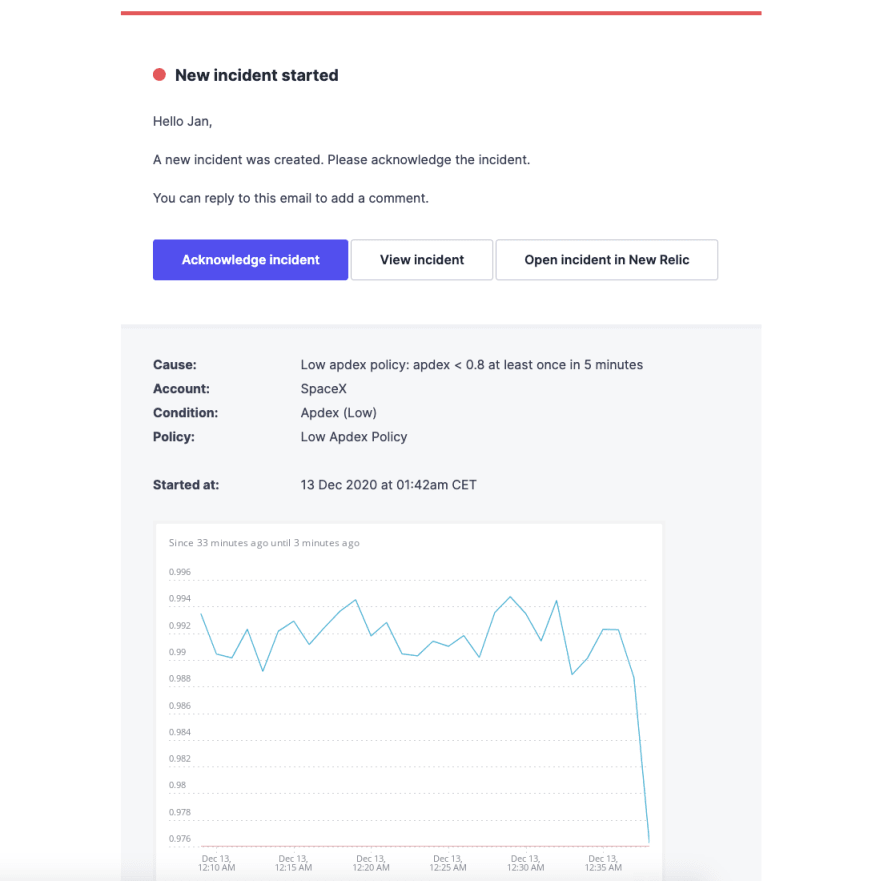
Example of an email incident alert for a spacex.com website.
4. Communication
What is incident communication?
Once an incident happens, it is necessary to communicate it properly with everyone who is affected by it. The response team is automatically notified by the alerting system, but what about other teams inside the company, product users, clients, or potential customers?
In order to communicate with everyone internally and externally, there are several communication channels available. The most common one is a dedicated status page, which shows the current status of the website.
For users and customers, an embedded status widget on the affected page is often put to use. Twitter and other social media are also useful channels for broader incident communication.

Example of a Dedicated status page.
5. Response
What is incident response?
Incident response is a process describing how the team collaborates on solving the cause of an incident. This part of the process is very specific to each team as different companies use very different tools and software.
In general, most of the actual troubleshooting will take place within the specific software, which is believed to be the cause of the incident.
The thing that incident responses have in common is that they are all being directed from one centralized tool. In this incident management tool, individual team members communicate with each other and share critical updates. It is also a single source of information as it shows the detailed timeline of the incident as well as all the actions that were taken to solve it.
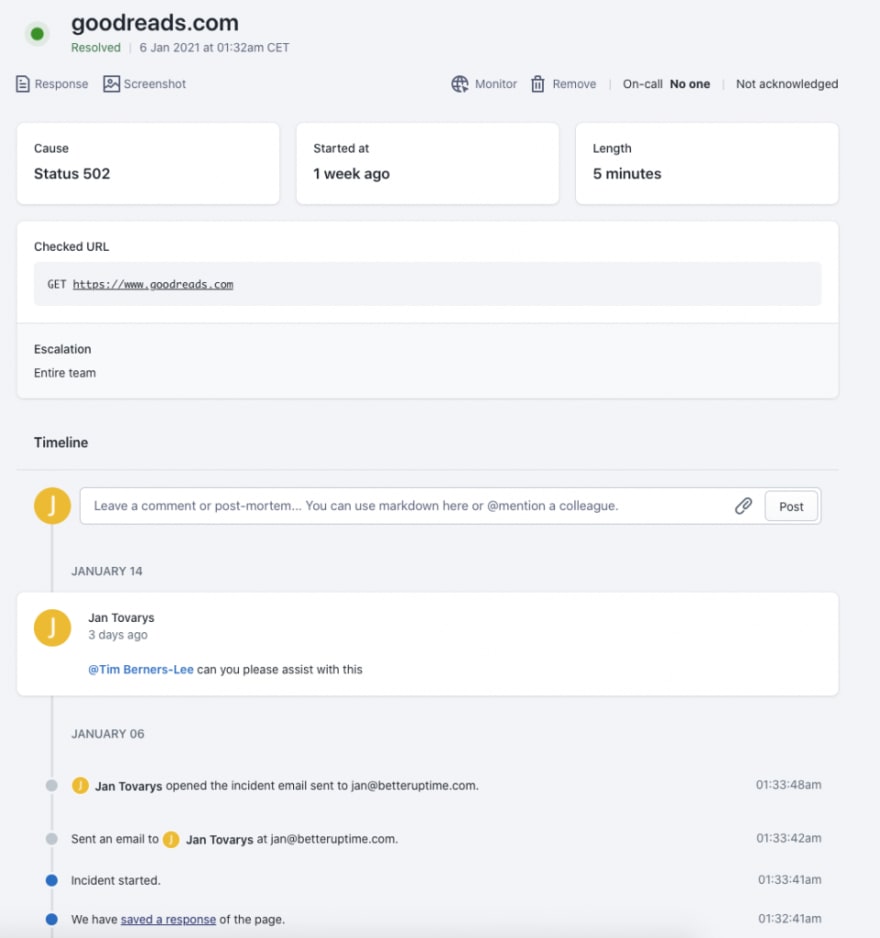
Example of centralized incident communication with a detailed incident timeline.
5 steps to a bulletproof incident management process
1. Best incident monitoring practices
Any alerts are only as good as the monitoring tool triggering them. The three main things you want to focus on when setting up monitoring solutions are incident verification, check frequency and alert thresholds.
Incident verification
Incident verification is essentially how the tool ensures that the incident is indeed occurring. Proper incident verification ensures that no false positives happen and you don’t get meaningless alerts.
Check frequency
Check frequency is important as it determines how often the monitor checks the desired service. This determines how quickly the potential incidents get spotted and how quickly you get the alert. For example, for uptime checks, the 30-second check frequency is considered to be best practice.
Alert thresholds
Alert thresholds are the conditions under which an alert is triggered. It is vital to set those incidents triggering thresholds to be realistic so only real incidents create an alert. Correct setup of thresholds can assure that no time of the on-call team goes to waste.
2. Best on-call practices
When it comes to on-call schedules, there is no one-size-fits-all solution. In order to create the most suitable on-call system for your organization, it is important to consider your team size, team locations, individual team members’ abilities, and preferred working hours.
On-call rotation
On-call rotation is a pre-set repeating on-call schedule. On-call rotations are useful as they eliminate the ad hoc approach and create a repeatable system that once established repeats throughout the year.
Team size
The first thing to consider when drafting an on-call rotation is the team size. For teams of two, it is common to go with every other day rotations. This means that one person does Monday, Wednesday, Friday, and Sunday and the other one Tuesday, Thursday, and Saturday, with the Sunday duty changing every other week. In the case of larger teams, weekly rotations are a popular practice.
Team locations
When your team is spread across the world you might be able to mitigate the effects of the dreaded night shifts. WIth team members, in different timezones, a follow-the-sun approach can assure that most of the on-call time is spent during sunlight hours. This will create a better work-life balance for the team members and should be applied when possible.
Individual preferences
Before creating an on-call rotation, it is vital to talk to everyone involved. Different individual preferences might often help to avoid necessary compromises. For example, a morning person on the team might prefer a 4:00 AM to 4:00 PM duty, while a night owl might be happy taking the 4:00 PM to 4:00 AM one. This way, both can be relatively happy, and there is no need to force anyone into full-day duty rotations.
Team member abilities
In most cases, not all team members have the same knowledge of the different systems, and sometimes they need help from more senior colleagues or the specific system owners. In order to do that, the on-call teams need to set up what happens when an incident needs escalating to another employee.
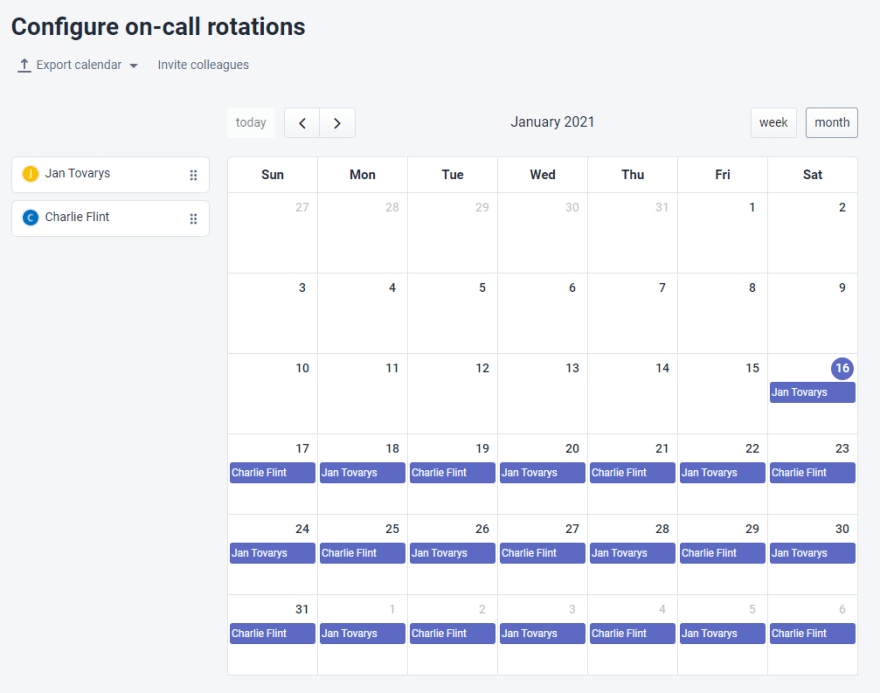
Example of monthly on-call schedule for a team of two.
Escalation policies
Escalation policy describes how an on-call team handles incident escalations. Incident is escalated in two cases. The first one is when the first responder isn’t able to solve the issue alone and needs assistance from another team member.
The second case is when the first on-call person doesn’t acknowledge the incoming alert. This can happen during night shifts when the alert doesn’t wake up the designated team member and the issue is then automatically escalated to another colleague.
Seniority-based escalation
The most basic escalation is calling in a more experienced person. Ideally, all the members should be able to solve incidents on their own, but on rare occasions, this is what can be done to assure that the incident is solved.
Function-based escalation
In some cases, the incident is specific to a system that the first responder is not equipped to resolve. To solve this issue, an escalation to a specific colleague with the needed knowledge of the specific systems is needed.
Automatic escalation
Sometimes the first-in-line person doesn’t respond to the alert within a pre-set time. In this case, the incident should be automatically escalated to another team member or, in critical cases, even the whole team.
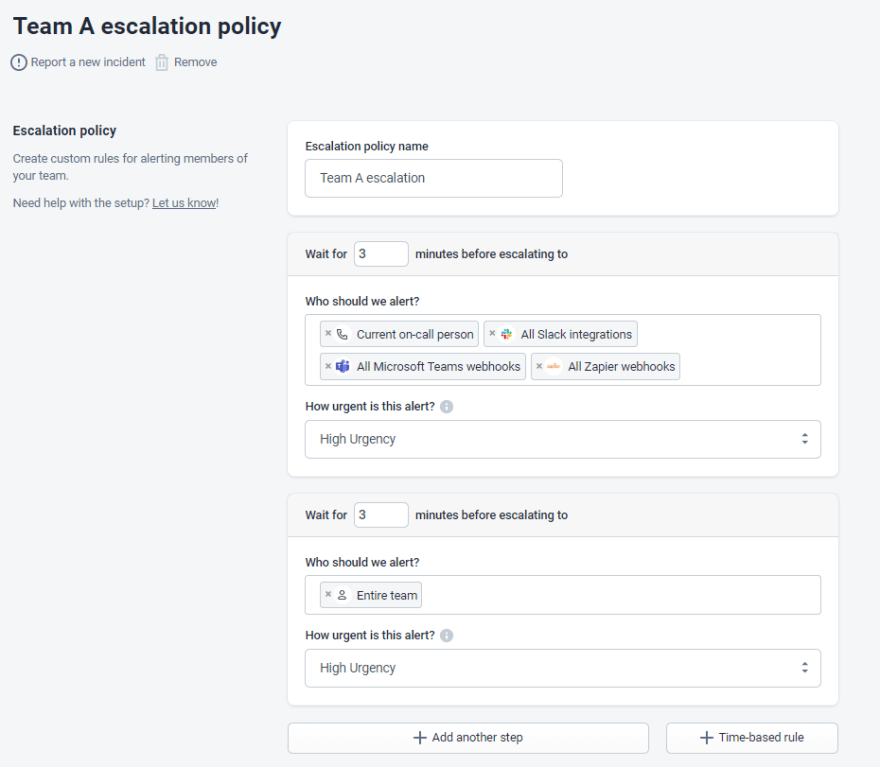
Example of an automatic escalation policy.
3. Best incident alerting practices
Compared to on-call, incident alerting rules are not that individual, and most of them can and should be adopted by all incident response teams. Overall, successful alerting is when your response team gets the minimum necessary amount of alarms, with all the necessary information, and via the right channel.
Use the right notification channels
There are many different ways to get notified about system downtime. The most common ones are phone calls, SMS, Slack & Microsoft teams, email, and push notifications. Since some alerts are more important than others, it is necessary to distinguish how on-call teams get notified about incidents with different priority levels.
Phone calls and SMS are a great way to get alerted about critical issues. Slack and email, on the other hand, are preferred for low priority incidents, which might be even of an informative nature rather than something needing an immediate fix.
When selecting the right notification channels, it really depends on the on-call schedules and on the individual team preferences. For example, phone calls might not be useful when fulfilling an on-call duty in the office, however when at home it might be the best option.
De-duplicate and group your alerts
When more significant problems happen, multiple alerts are often triggered. A proper alerting system will automatically de-duplicate those alerts. As a result, related alerts will be grouped into a single one, so no redundant or unactionable alerts reach the on-call team.
Create actionable alerts
Getting an alert stating that there is a problem is great, but having the insight into how to solve it is equally important. That is why alerts need to include quality debugging data like helpful event logs, error screenshots, and system performance graphs. This extra information can make the diagnostics process noticeably easier.

Example of an actionable alert sent via Slack.
Avoid alert fatigue
Alert or alarm fatigue is a situation where an overwhelming number of alerts received by the on-call team leads to increased response time and, in more severe cases, to missed alerts. The psychological reason behind this is that the more people get exposed to false alerting, the more they are to normalize incoming alerts, tolerate them, and neglect them or even purposefully ignore them.
By de-duplicating alerts, making them as actionable as possible, and only using the most relevant notification channels, the possibility of alert fatigue can be severely decreased. Read more about how to avoid alert fatigue by measuring what matters in our MTTR and incident management KPIs article.
4. Best incident communication practices
Incidents happen, and any modern company must be transparent about them because if communicated properly, the damages can often be mitigated. Communication needs to be as fast as possible so whenever the response teams confirms that there is an incident, the following incident resolution should go hand in hand with the incident communication.
Now when it comes to the distribution of honest and timely incident updates, there are three major channels that are considered best practices.
Create useful status pages
The main incident communication channel for the majority of companies is a dedicated status page. A dedicated status page is a webpage that displays updates about ongoing incidents. When you subscribe to a status page, you automatically receive updates the moment they are posted there by the response team.
Leverage embedded status
The easiest way to communicate incidents to your website visitors or users is via embedded status. This embedded widget shows on the top of the website and tells users the incident details. It is usually clickable and leads to a dedicated status page that provides all the necessary information. Communication via widgets can be applied in case of incidents that decrease the performance of the system but don’t create downtime.
Don’t overlook social media
Social media are another way of transparently communicating incidents. Many companies choose Twitter to broadcast downtime. It is also possible to combine social media with previously mentioned channels by integrating updates to your status page.
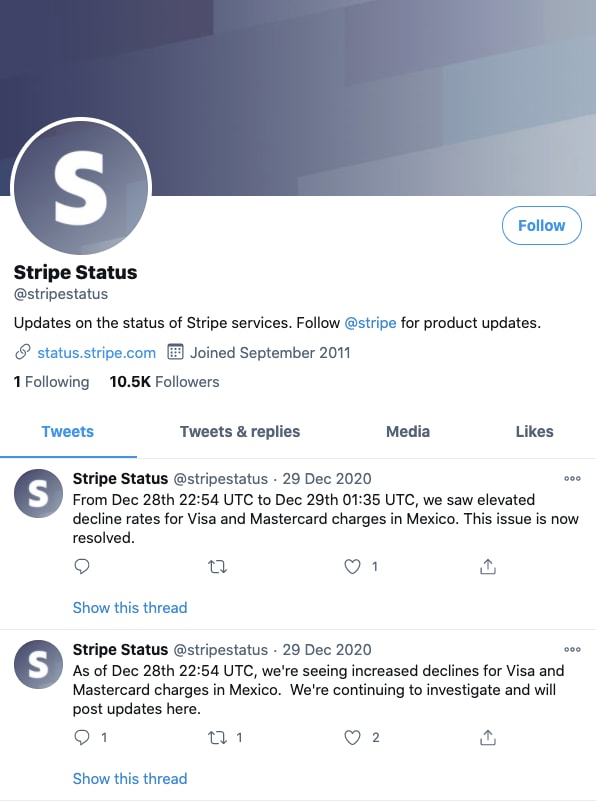
Stripe’s status profile on Twitter.
5. Best incident response practices
When it comes to actually solving incidents is best to remove any unnecessary manual tasks and diagnostics processes. Any manual tasks of gathering information from different sources can be eliminated by using a centralized mission control tool. The diagnosis process can be easily standardized with an action plan or a runbook.
Since not all team members are experts in all of the systems that might potentially go down, it is best practice to have an action plan that everyone can follow to diagnose the root cause properly.
Have an action plan
When it comes to incident response, all teams should have an action plan of what steps to take in a given scenario. An action plan helps any on-call person to access the given problem and gives the response relevant course even when the on-call expert is not available.
Centralize mission control
A centralized workplace prevents team members from having to search multiple tools and documents to find the necessary information like contact lists, on-call schedules, or escalation policies.
Centralized mission control also means that a precise timeline of the incident is recorded. This includes critical information like what were the different steps different team members took to resolve the incident as well as what was communicated with the public. Having a single source of truth like this prevents repetition of the same tasks and serves well in accessing the KPIs of the incident resolution process.
Don’t underestimate postmortems
Postmortems are often overlooked as they are only reported after everything is back to normal, and no immediate action is necessary. But in-depth postmortems and incident analysis can make a significant difference between solving an incident for once and preventing it from occurring ever again in the future.

Top comments (1)
Good Post!