
One of the most classic use-cases for Kubernetes is Horizontal auto-scaling: the ability of your system to increase its resources automatically in reaction to higher demand by adding new machines. The need for auto-scaling is not just about reducing need to accurately project load and manual work of adjusting hardware. It can also be existential as in case of my team at Coolblue (Dutch web-shop present in Benelux and Germany) when the marketing emails with Black Friday discounts start reaching customers, causing enormous peak in traffic. For some types of workloads: like optimising delivery routes (Vehicle Routing Problem with additional constraints, more complex version of famous Traveling Salesman Problem) CPU demand grows very fast and can not only dominate your infrastructure spending with over-provisioned hardware for handling the peak, but in the worst case scenario - without horizontal auto-scaling you can be surprised by the black Friday peak bigger than forecasted and experience an outage at the most important time of the year for the business.
When do you need auto-scaling?

- Your traffic varies over time
- Your traffic is hard to predict or its impact on the CPU and memory is hard to determine

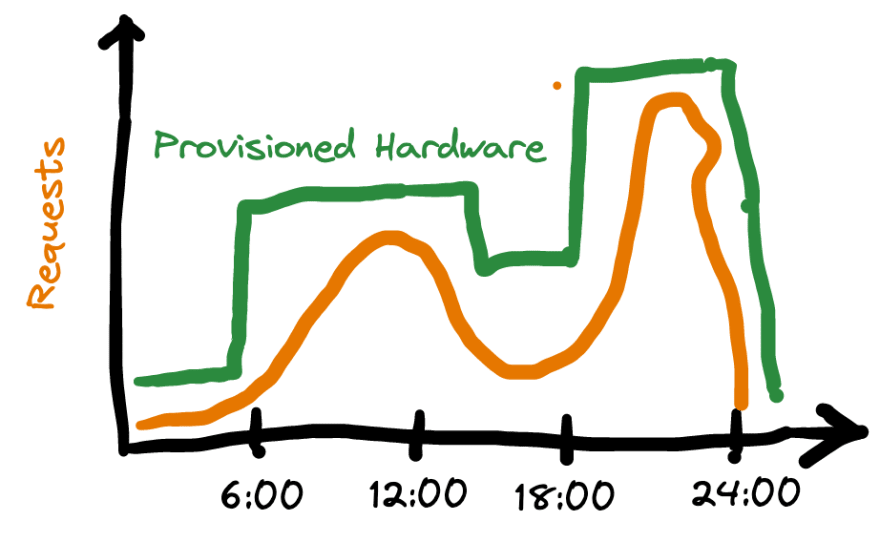
In the picture above Coolblue fits the right-most chart - Q4 is the busiest season for e-commerce. Forecasting of sales provides good basis for preparation, but may still leave a huge range of possible hardware specs, leading to over-provisioning hardware and then of course over-paying. Which brings me to the next point

Load varying through the year is much easier to plan for. Big daily range of load is harder to cope with, just like the annual peak it leads to over-provisioning, but unlike the over-provisioned hardware on the scale of the year, you cannot scale down and adapt after daily peak. Not when your operations are manual that is. Not to mention, that in the scenario with high daily peak despite over-provisioning you are still left vulnerable to unexpectedly big peak in traffic.
The easiest architecture for most web-applications (or back-ends for them) is a vertically scaled single host deployment. When you start maxing it out - you bump the specs. The simplicity of it of course comes at a cost: if it really is just a single host you need downtime to add more CPU and RAM.

At certain point there isn't any bigger boat for you

More complex architecture that lets you increase capacity without bumping specs of individual machines - causing their downtime - is horizontal scaling. In this architecture you have more than one instance of your application and requests are handled by any of those machines that are currently available.
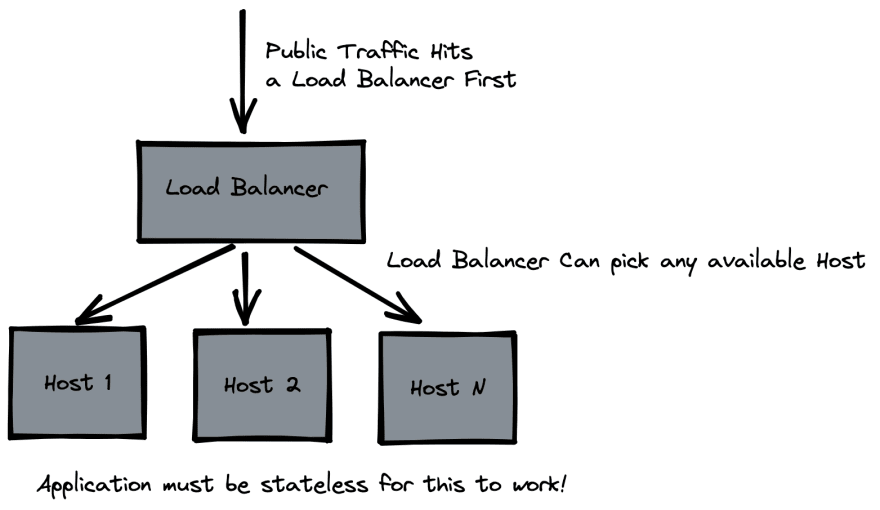
There is a catch: your application must be stateless for this architecture to work this way, if it is stateful, complexity of routing requests will grow further as you need to ensure the right instance receives its own requests.

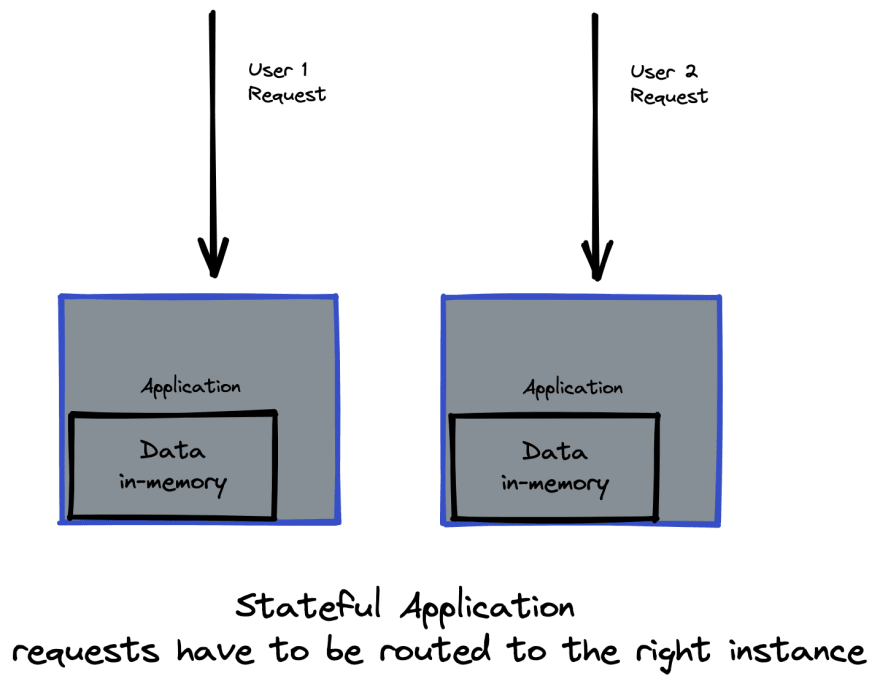

Our Delivery Routes Optimisation is Stateful and needs to scale for annual and daily peaks
This is the case for our package delivery route optimisation service at Coolblue, for which my team is responsible. In order to cope with the Black Friday peak we needed to provision 128 CPUs VM, at the moment of writing it, it is the biggest machine available in GCP in our region and compatible with our software. We can only go horizontal from here.
Optimising delivery routes on top of being famously CPU intensive leads also to stateful architectures, as any optimisation job will need information about all delivery orders, vehicles, shifts and other constraints in memory at every step of the optimisation process. This data is big enough that fetching it from the database on each mutation would reduce system performance and the mutations happen multiple times a second both as a result of an ongoing process of optimisation and incoming requests to schedule new orders.
Are We ready for Black Friday 2023?
This year only one stateless micro-service responsible for calculating travel time between deliveries is in Kubernetes. Last year it was the one that gave in during the peak causing partial outage, this year it scales by itself under the same circumstances not only avoiding outage but also over-provisioning during quiet times (all our customers are in the same time-zone).
How exactly is Kubernetes helping here?
For our stateless microservice, the k8s setup is pretty simple and standard. The most important resource types we use:
-
Deploymentto specify config of the travel-time service itself (env vars, hardware required to run single instance, etc) -
Serviceto specify its internal endpoint where other components can reach it -
HorizontalPodAutoscalerwhere we specify minimum and maximum number of replicas (app instances) that can be provisioned and most importantly: the CPU utilisation threshold that k8s can use to trigger the horizontal scaling
Early next year we will also put our stateful route optimisation application in Kubernetes, removing the ceiling from our capacity and also reducing how much over-provisioning for the daily and annual peaks we need. This work is significantly more complex (due to its stateful nature and custom scaling) and deserves a dedicated article.

Top comments (0)