อย่างที่เคยเล่าในบทความก่อน ๆ เรื่องการ scrape ครับ มี use-case หลายอย่างที่สามารถทำได้ เช่น ใช้เพื่อสร้าง dataset สำหรับ train machine learning model ใช้เพื่อทำงานวิจัย หรือใช้ทำ social monitoring เพื่อเก็บรวบรวม comment จากลูกค้าไปพัฒนา product ของบริษัทต่อไป
บทความนี้เป็นบทความสั้น ๆ (แต่พอเขียน ๆ ไปแล้วก็ไม่สั้นเท่าไหร่ 555) ที่จะทำการ deploy Python script ขึ้นบน Google Cloud เพื่อทำการ scrape เว็บแบบอัตโนมัติ พร้อมทั้งพูดถึง services ต่าง ๆ ของ Google Cloud Platform แบบคร่าว ๆ (คร่าว ๆ จริง ๆ ครับ แล้วถ้ามีโอกาสก็จะมาอธิบายในรายละเอียดของแต่ละ service แยกกันไปอีกที)
บทความจะแบ่งเป็น 2 ส่วนนะครับ ส่วนแรกจะอธิบายเกี่ยวกับ Google Cloud services และ architecture ที่เราใช้ สั้น ๆ และส่วนที่ 2 ก็จะมี script ให้ สามารถนำไป deploy ได้ทันทีภายใน 5 นาทีเท่านั้นครับ
โดยในบทความนี้จะ focus ที่ตัว Google Cloud เป็นหลักนะครับ สำหรับท่านที่สนใจเกี่ยวกับการ scrape ทางเพจของเรา Copy Paste Engineer ก็กำลังทำบทความสอนอยู่ ทยอยอัพเรื่อย ๆ สามารถติดตามได้นะครับ อ่าน part 1 ได้ที่นี่
Cloud Platform
สำหรับท่านที่ไม่ทราบ พูดแบบไม่เป็นทางการ ก็คือ Cloud Platform เนี่ย เหมือนเป็น "บ่อ" ใหญ่ ๆ ครับ ที่มี resource อยู่แบบไม่จำกัด หรือมีเยอะมาก เช่นเป็นบ่อของ CPUs ก็มี CPUs กองเอาไว้รวมกันอยู่เต็มไปหมด และก็มีบ่อของ hard disks มีบ่อของ RAMs ...
ทีนี้ Cloud Platform เจ้าต่าง ๆ เนี่ยก็จะเสนอให้เราเช่า resource ต่าง ๆ ของเขาได้ โดยให้เรา request ขอเช่าไปผ่านหน้าเว็บได้เลย เช่น เราอยากได้ VM สักตัวหนึ่งมา deploy web application ของเรา เราก็แค่เข้าไปที่หน้าเว็บของ Cloud Provider อย่างเช่นใน Google Cloud บนหน้าเว็บเราก็สามารถคลิกเลือก spec ได้ว่าอยากได้ RAM กี่ GB มี CPUs กี่ cores จะเอา hard disk กี่ GB จะเอา OS เป็นอะไร พอกรอกข้อมูลเสร็จก็รอไม่กี่นาที เราก็จะมี VM ตาม spec ที่ระบุไปมาให้ใช้ผ่าน SSH protocol
ซึ่ง Cloud Provider ก็จะมีระบบ Cloud Manager ที่ใช้จัดการกับ request การเช่า resource ต่าง ๆ ภายใน "บ่อ" ให้อัตโนมัติ คือระบบก็จะไปหา physical resource ตามที่เราต้องการมาเช่น RAM, CPUs, และ disks แล้วก็เอา VM ไปลง จากนั้นก็เปิด access ให้กับเราเข้าใช้งาน และถ้าเราต้องการจะปรับเปลี่ยน spec ของ VM เรา เช่นอยากเพิ่ม RAM จาก 8 GB เป็น 16 GB ก็สามารถทำได้ผ่านหน้าเว็บเช่นกัน ระบบ Cloud Manager ก็อาจจะทำการย้าย VM ของเราไป physical machine ที่มี resource เพียงพอให้เราใช้ได้ภายในเวลาไม่กี่นาที
และนอกจากการเช่า resource โดยตรง ซึ่งเป็นบริการพื้นฐานของ Cloud Platform แล้ว Cloud Provider แต่ละเจ้าก็จะมี services ที่เป็น high-level ขึ้นมาอีกแตกต่างกันไป
เช่น บริการ Platform as a Service (PaaS) คือแทนที่เราจะเอา VM เปล่ามา install Python เอง install dependencies ต่าง ๆ setup ต่าง ๆ เอาเอง เราก็แค่บอกบริการ PaaS ว่า เราจาก deploy application ภาษา Python นะ! ทาง Cloud ก็จะจัดเตรียม environment สำหรับการทำ application ภาษา Python ไว้ให้ เราก็แค่เอา code แปะเข้าไป หรือ upload container ขึ้นไปก็ใช้งานได้ทันที
หรือแทนที่เราจะต้อง install และ setup Database ด้วยตัวเอง Provider บางเจ้าก็จะมีบริการให้เลย คลิก ๆ สองสามทีก็ได้เครื่อง VM ที่มี Database ติดตั้งไว้เรียบร้อย พร้อมให้ใช้งานได้เลยครับ
และยังมี service ที่เป็น Serverless ต่าง ๆ ที่เราสามารถ develop application ของเราได้ โดยไม่ต้องกังวลเรื่องตัว VM เลย คือ คิดสะว่าไม่มีเครื่อง เพราะ Cloud Provider จะเป็นคน manage ตัว VM ให้ทั้งหมด รวมถึงอาจจะทำ auto-scaling ให้ด้วย เป็นต้น

ตัวอย่าง Google Cloud services บางส่วน จากหนังสือ Building Google Cloud Platform Solutions
Google Cloud Services
สำหรับ services ใน Google Cloud Platform ทั้งหมดนี่ก็มีเยอะมากนะครับ ในบทความนี้จะแนะนำเฉพาะ services ที่ต้องใช้ในการ deploy code ของเรา แบบคร่าว ๆ ไว ๆ เท่านั้นนะครับ ส่วนรายละเอียดของแต่ละอย่างจริง ๆ เนี่ย คิดว่าถ้ามีโอกาสจะแนะนำเพิ่มเติมในบทความต่อ ๆ ไปครับ services ที่นำมาแนะนำได้แก่
- Cloud Functions
- Cloud Scheduler
- Cloud Pub/Sub
- Cloud Datastore
- BigQuery
Cloud Functions
Cloud Functions เป็น service แบบ serverless ตัวหนึ่ง ที่ช่วยเชื่อม service ต่าง ๆ ของ Google Cloud เข้าด้วยกัน เหมาะสำหรับ deploy script งานเล็ก ๆ ที่จะถูกรันเมื่อมี "event" บางอย่างครับ ตัวอย่าง "event" เช่น มี HTTP requests เข้ามาที่ Cloud Function, มีการ update ข้อมูลใน storage, หรือมี message จาก Pub/Sub (เดี๋ยวจะพูดถึงต่อไปครับ)
ยกตัวอย่างเช่น ในบางครั้งเราอาจจะอยาก export ข้อมูลจาก database ลงใน data warehouse ทุก ๆ วัน เวลาเที่ยงคืน เพื่อให้ฝ่าย BI นำไป analyze ในเช้าวันถัดไปได้ ถ้าต้องให้ Data Engineer ไปรอกด export ข้อมูลเองทุกวันตอนเที่ยงคืน น่าจะลำบากนะครับ วิธีแก้ก็คือเราสามารถเขียน script การ export ข้อมูลใส่ Cloud Functions เอาไว้ แล้วก็ตั้งเวลาให้ทำงานทุก ๆ วันตอนเที่ยงคืน Data Engineer ของเราก็จะมีเวลาพักผ่อนมากขึ้นแล้วครับ
หรือสมมุติว่าใน Google Cloud Platform ของเรามี VMs อยู่หลายตัว แล้วเราอยากให้ VMs เหล่านี้ เปิดทุก ๆ วันจันทร์ ตอน 9:00น. และปิดทุก ๆ วันศุกร์ ตอน 21:00น. แทนที่เราจะให้พนักงานมานั่งเปิด-ปิดเอง มันก็เสียเวลาใช่ไหมครับ แต่ด้วย Cloud Functions เราสามารถที่จะใส่ script สำหรับ เปิด-ปิด VMs พวกนั้นเอาไว้ แล้วตั้งเวลาให้มันทำงานตามที่กำหนดได้นั่นเอง
หรือแม้แต่การใช้ Cloud Functions ในการทำเป็น backend endpoint อันเล็ก ๆ สำหรับ query ข้อมูลจาก database, insert data, หรือ clean data ก็ทำได้ครับ

ตัวอย่างการใช้ Cloud Functions ในการทำ Slack notification คือ เมื่อมีคน push commit ใน git ของเรา ให้ Github push "event" มาที่ Cloud Functions เพื่อให้ Cloud Functions ได้ process และส่งการแจ้งเตือนไปที่ Slack
จาก https://cloud.google.com/functions
เนื่องจาก เราสามารถ trigger Cloud Functions ให้ทำงานได้หลายทาง (มี event ที่ใช้ trigger หลายอย่าง) และเราไม่ต้อง manage ตัว server เอง (serverless) สามารถทำ auto-scaling ได้เอง และราคาถูก จึงทำให้มีคนนำเอา cloud function ไปประยุกต์ใช้งานหลายอย่างมาก ทั้งในด้าน Data processing, Webhooks, หรือ IoT แต่ Cloud Functions ก็มีข้อจำกัดเล็กน้อยเช่นในเรื่องของขนาด Memory ในแต่ละ instance และ execution time คือ script ต้องใช้ RAM ได้สูงสุดแค่ 2GB และทำการประมวลผลได้มากสุดไม่เกิน 540 วินาทีเท่านั้น
Cloud Scheduler
Cloud Scheduler ก็ตามชื่อเลยครับ คือเป็นตัวตั้งเวลา เพื่อสร้าง "event" บางอย่างขึ้นมา ซึ่งในที่นี้จะใช้เป็นตัวที่คอยสร้าง Pub/Sub event เพื่อ trigger Cloud Functions ให้ทำงานครับ (เช่น ทุก ๆ 3 นาที, ทุก ๆ 6 ชั่วโมง, หรือ ทุก ๆ 7 วัน) ถ้าเปรียบเทียบ ก็เหมือนการเขียน cron job บน Linux server นั่นเองครับ (แถมวิธีการตั้งเวลาก็ใช้เป็นแบบ 5 tokens เหมือนกับ cron เป๊ะ ๆ ด้วย)
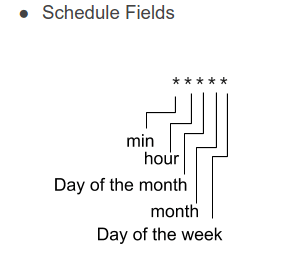
5 tokens ที่ใช้ในการ config Cloud Scheduler จาก https://cloud.google.com/scheduler/docs/configuring/cron-job-schedules
Cloud Pub/Sub
บทบาทของ Cloud Pub/Sub ก็เป็นอย่างที่ได้พูดถึงใน 2 services ข้างต้นนะครับ คือ Cloud Scheduler จะสร้าง event Pub/Sub ขึ้น และตัว event Pub/Sub นี้ ก็จะ trigger ให้ Cloud Functions ทำงาน
ทีนี้มาพูดถึงตัว Pub/Sub กัน จริง ๆ แล้ว Pub/Sub เนี่ย เป็น message broker เหมือนพวก Kafka อะไรแบบนั้นครับ พูดแบบไม่เป็นทางการก็คือ คล้าย ๆ เป็น "ไปรษณี" ที่ผู้ส่งสามารถส่งข้อความ หรือข้อมูล ไปหาผู้รับ ที่รออยู่ได้ แต่ต่างกันตรงที่ว่า Pub/Sub จะใช้ "topic name" ในการอ้างอิงครับ
หมายความว่า สมมุติมีโปรแกรม A รอรับข้อมูล (subscribe) อยู่ที่ topic ชื่อ "scraper-trigger" โปรแกรม A ก็จะรอไปเรื่อย ๆ ครับ จนกว่าจะมีใครส่ง message มาที่ topic "scraper-trigger" นี้ สมมุติ P push ข้อมูล (publish) ไปที่ topic "scraper-trigger" Pub/Sub ก็จะไปเรียกโปรแกรม A ให้ทำงาน พร้อมกับส่งข้อมูลที่ P pushed ไปให้ครับ ซึ่ง topic "scraper-trigger" นั้นก็สามารถมี subscriber หลายคนได้ครับ Pub/Sub ก็จะส่งข้อมูลให้ทุกคนได้รับข้อมูลเดียวกันเหมือนกันหมดนั่นเองครับ
note: อันนี้เป็นการ subscribe topic แบบหนึ่งเท่านั้นนะครับ ยังมีรูปแบบอื่น แต่จะไว้กล่าวถึงในโอกาสถัดไปครับ

diagram แสดงลำดับการทำงานของ Pub/Sub
จาก https://cloud.google.com/pubsub/docs/overview
Cloud Datastore
Cloud Datastore นี่เป็น serverless NoSQL Database ครับ ทำ auto-scale และมี replication ให้ ปกติพวกข้อมูล JSON ที่ต้องอ่านและอัพเดตบ่อย ๆ แต่ไม่รู้จะเอาไว้ไหน เช่นพวก config ค่าต่าง ๆ ผมก็จะเอามาใส่ในนี้แหละครับ เพราะมันไม่ต้อง setup อะไรเลย สามารถใช้งานได้ทันทีและราคาถูก แต่ feature การ query การ update อะไรต่าง ๆ มันจะค่อนข้างน้อยไปหน่อย ถ้าเคยใช้ MongoDB มาก่อนแล้วมา Cloud Datastore ก็อาจจะหงุดหงิดหน่อยนะครับ 555 แต่เข้าใจว่า Google กำลังพัฒนาอยู่ครับ
BigQuery
BigQuery เป็น data warehouse แบบ serverless ก็คือจะเอาไว้ใช้เก็บ structured data ที่มีการ optimize ให้สามารถ query ได้เร็ว เพื่อนำไปใช้ในการ analyze และทำ dashboard ได้อย่างมีประสิทธิภาพ และเช่นเดียวกัน ก็คือเราไม่ต้อง manage ตัว server ครับ ไม่ต้องสนใจว่ามันจะใช้เครื่องไหนประมวลผลอะไรยังไง เพราะภายในมันจะทำการ auto-scaling และ optimize ให้เองครับ และก็ราคาค่อนข้างถูก
Pantip Scraper
สำหรับตัว Python script ของ scraper เนี่ยจะไม่ลงรายละเอียดลึก ๆ นะครับ เพราะทางเพจก็กำลังมี series Python Web Scraping อยู่แล้ว
คร่าว ๆ ก็คือเป็น script ที่จะ scrape กระทู้ล่าสุดใน tag ความรักวัยรุ่น ซึ่งเป็นที่นิยม โดยข้อมูลที่ดูดมาได้แก่ "ชื่อหัวข้อ" ของกระทู้ใน Pantip, id ของหัวข้อ, เวลาที่เขียน, user ที่เขียน, ฯลฯ ออกมาเรื่อย ๆ จนกว่าจะถึง last_id ก็คือ id ของหัวข้อที่เคย scrape เอาไว้ล่าสุด
ดังนั้นสิ่งที่เราต้องการจากระบบของเราก็มีดังนี้
- ส่วนที่ใช้ในการรัน Python script โดยจะตั้ง limit ไว้ให้ scrape มาในแต่ละครั้ง มากที่สุดแค่ 50 กระทู้เท่านั้น
- ส่วนที่ใช้ในการตั้งเวลา เพื่อเรียก Python script ขึ้นมารัน โดยจะตั้งเวลาให้รันทุก ๆ 10 นาที เพราะอัตราการสร้างกระทู้ไม่ได้สูงมาก ไม่มีความจำเป็นต้องทำถี่กว่านี้
- ส่วนที่เก็บ last_id ของการ scrape ครั้งล่าสุด
- ส่วนที่เก็บข้อมูลผลลัพธ์
note: ผู้เขียนจงใจนะครับ ทั้งเรื่องที่จะ scrape แค่ชื่อหัวข้อเท่านั้น, ตั้ง limit จำนวนกระทู้ต่อครั้ง แค่ 50 กระทู้, และตั้งเวลาให้ไม่ถี่มาก เหตุผลก็เพื่อไม่ให้รบกวนเว็บ Pantip ครับ และถ้า scrape ข้อมูลส่วนอื่น ๆ ไปมากกว่านี้คงจะไม่เหมาะสมครับ
ดังนั้นเราจึงออกแบบ architecture คร่าว ๆ ได้ตามนี้ครับ

คือ
- ใช้ Cloud Functions ในการ run Python script
- ใช้ Cloud Scheduler ในการตั้งเวลา เพื่อเรียก Cloud Functions
- ใช้ Cloud Datastore ในการเก็บ last_id ของการ scrape ครั้งล่าสุด
- ใช้ BigQuery ในการเก็บผลลัพธ์สุดท้าย เผื่อจะเอาไปทำ dashboard หรือ export เป็นไฟล์ csv ออกมาใช้งานต่อได้
สิ่งที่ต้องเตรียม
- account gmail ที่รับ credit Google Cloud $300 ฟรี เรียบร้อยแล้ว จาก บทความก่อนหน้านี้ ครับ ถ้ายังไม่มีก็ให้ดำเนินการตามในบทความนั้นก่อนนะครับ ถึงจะสามารถ deploy ได้
Deploy Pantip Scraper
ผู้เขียนได้เตรียม script ทั้งหมดของระบบไว้ให้ใน Colab notebook นี้ แล้วนะครับ สามารถรันเพื่อได้ทันที พร้อม ๆ กับที่อ่านบทความนี้ครับ วิธีการรันเขียนไว้ใน notebook แล้วนะครับ
อย่างที่ได้บอกข้างต้นนะครับ เราจะ focus ที่ Cloud Platform เพราะฉะนั้นจะไม่ขออธิบาย Python script ที่ใช้ scrape ในบทความนี้ และจะอธิบายเฉพาะส่วนที่สำคัญนะครับ
ตรงนี้ไม่เชิงว่าเป็นคำเตือนนะครับ แต่แนะนำว่าขณะที่รันแต่ละคำสั่ง ให้สังเกตุ output ของมันด้วยครับ ถ้ามีตรงไหนที่เหมือนเป็น ERROR ควรหยุดรันทันทีแล้วลองเริ่มรันใหม่ดูแต่แรกนะครับ เพราะเป็นไปได้ว่าอาจจะลืมรันบรรทัดไหนไป
ซึ่งจริง ๆ แล้วมันไม่มีอันตรายใด ๆ ทั้งสิ้นแหละครับ เพราะเราใช้ credit free $300 อยู่ แล้ว และราคาของแต่ละ service ที่เราใช้ก็ถูกมาก และถ้ามีปัญหายังไงก็สามารถมาปรึกษาในเพจได้นะครับ
1. สร้าง Python script
ขั้นแรกนะครับให้รัน code ในส่วน เขียน scraping script ทั้งหมดก่อนครับ เมื่อทำเสร็จ ไฟล์ script สำหรับ scrape จะถูกสร้างขึ้นครับ ได้แก่ main.py, requirements.txt, และ scraper.py
พอรัน ls script จะต้องได้ผลลัพธ์แบบนี้ครับ
$ ls script/
main.py requirements.txt scraper.py
ซึ่ง script เหล่านี้จะถูก deploy ขึ้นไปที่ Cloud Functions ครับ โดยไฟล์ main.py จะเป็น script หลักที่จะถูกเรียกไปรัน ส่วน requirements.txt จะเอาไว้บอก Cloud Functions ว่าเราต้องใช้ module อะไร version เท่าไหร่บ้าง Cloud Functions ก็จะ install รอเอาไว้ให้ครับ
2. Login เพื่อใช้ gcloud CLI
ต่อไปให้รันคำสั่งนี้เพื่อ login ครับ
$ gcloud auth login
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?code_challenge=...
Enter verification code:
มันก็จะสร้าง link ขึ้นมา link หนึ่ง ให้กดเข้าไปแล้ว login ด้วย gmail ที่เราเพิ่งได้รับ credit free $300 มาครับ
จากนั้นมันก็จะ generate code มั่ว ๆ ขึ้นมา ให้ copy code ตรงนั้นมาวางในกล่องสีขาว ๆ หลังคำว่า Enter verification code: แล้วกด Enter ครับ

ตรงนี้คือการยืนยันให้สิทธ์ Colab notebook ที่รันอยู่นี้ให้สามารถ manage Google Cloud Account ของเราได้ครับ
3. สร้าง project ใหม่ และผูก project กับ billing account
ให้รัน script ในส่วน สร้าง Project ใหม่ เพื่อสร้าง project ใหม่ขึ้นมา และจะเห็น output ที่เขียนว่า your new Project ID: ... ให้ copy Project ID เก็บเอาไว้ด้วยนะครับ เพื่อเวลาที่เราจะลบ project ทิ้ง จะได้ลบถูก project

จากนั้นก็รัน script ในส่วน เปิด Billing Account ครับ ตรงนี้ผูก Billing Account ที่เรามี credit ฟรี $300 เข้ากับ project ที่สร้างใหม่นี้ครับ
4. ต่อไปก็เปิดใช้งาน services ต่าง ๆ ที่เราใช้ใน project ทั้ง 4 ตัวครับ
$ gcloud services enable cloudscheduler.googleapis.com
$ gcloud services enable cloudfunctions.googleapis.com
$ gcloud services enable datastore.googleapis.com
$ gcloud services enable bigquery.googleapis.com
5. สร้าง scheduler
ให้รันโค้ดในส่วน ตั้ง Scheduler ทั้งหมดครับ คำสั่งนี้ก็จะสร้าง scheduler ขึ้นมา โดยตั้งชื่อ scheduler ตามค่าของตัวแปร SCHEDULER_NAME ครับ
$ gcloud scheduler jobs create pubsub $SCHEDULER_NAME \
--topic=$PUBSUB_TOPIC_NAME \
--schedule="*/10 * * * *" \
--message-body="start" # ตรงนี้คือตัวข้อความ จะใส่อะไรก็ได้ครับ ไม่สำคัญ
*/10 * * * * อันนี้เป็นการตั้งเวลาตามแบบ Cron ปกติครับ หมายความว่าให้รันทุก ๆ ครั้งที่ เวลามีเลขบอกนาทีหาร 10 ลงตัว (เช่น 13:10น., 09:00น., 21:50น.)
โดย scheduler ตัวนี้เมื่อทำงาน จะส่ง message ไปที่ Pub/Sub ที่ topic ชื่อ "scraper-pantip-trigger" (ค่าของตัวแปร PUBSUB_TOPIC_NAME)
6. deploy Cloud Functions สะที 555
ต่อไปเราก็ deploy Cloud Functions ชื่อ "pantip-scraper" โดยทำงานเมื่อมีข้อความส่งมาที่ Pub/Sub topic ชื่อ "scraper-pantip-trigger" (จากตัวแปร PUBSUB_TOPIC_NAME ซึ่งเป็นชื่อเดียวกับที่ scheduler ส่ง message ไปหา)
$ yes n | gcloud functions deploy pantip-scraper \
--region=asia-east2 \
--trigger-topic=$PUBSUB_TOPIC_NAME \
--source=./script \
--set-env-vars GCLOUD_PROJECT=$GCLOUD_PROJECT \
--entry-point=main \
--runtime=python37 \
--timeout=540
โดยให้ใช้ code ที่อยู่ใน folder ./script ที่เราสร้างขึ้นมาตอนแรกสุด และให้รัน function ชื่อ main ใน main.py
(yes n นี่ใส่มาเพราะเวลา deploy มันจะถามว่าจะ allow unauthorized access หรือไม่ ใส่ yes n เพื่อให้ตอบ No ให้เราครับ)
หลังจาก run code ด้านบนเสร็จหมด เท่านี้ก็ deploy ทุกอย่างเสร็จเรียบร้อยครับ ให้รอสัก 10 นาที หรือรอให้ผ่านเวลาที่หาร 10 ลงตัว เพื่อให้แน่ใจว่า Cloud Functions เราได้ถูกรันแล้วครั้งหนึ่งนะครับ
จากนั้นก็ให้รันโค้ดบรรทัดต่อไป
print(f'link to BigQuery table: https://console.cloud.google.com/bigquery?project=...
ก็จะ generate link ไปหาข้อมูลใน BigQuery ที่ Cloud Functions scrape มาให้ครับ
ถ้าเข้าไปแล้วยังไม่เห็น อาจจะต้องรออีกสักพักแล้วลอง refresh ดูนะครับ

ตัวอย่างข้อมูลในตารางที่ scrape ออกมานะครับ
ส่วนด้านบน สามารถเขียน SQL เพื่อ query ข้อมูลออกมา analyze หรือสร้าง dashboard ได้นะครับ จะพูดถึงในบทความถัด ๆ ไปครับ
7. delete Project
สุดท้าย พอเราเล่นจนพอใจแล้วก็ delete project ทิ้งด้วยคำสั่งนี้ครับ
$ gcloud projects delete $GCLOUD_PROJECT --quiet
Pricing
ถึงจะบอกว่าฟรีก็จริงครับ แต่ลองมาเช็คราคาดูจริง ๆ กันหน่อย ว่าใน service แต่ละตัวถ้ารันจริง ๆ จะต้องใช้เงินเท่าไหร่ต่อเดือนนะครับ
ซึ่งใน document ของ service แต่ละตัวก็จะมี detail การคิดเงินที่ต่างกันออกไป แล้วก็ซับซ้อน แต่ Google ก็มีบริการ Price Calculator ออกมาให้ เพื่อให้สามารถคำนวณกันเองได้ง่าย ๆ ครับ เข้าไปตามลิ้งนี้เลย > Google Cloud Price Calculator
Cloud Functions
เนื่องจากเราตั้งเวลาให้ Cloud Functions ทำงานทุก 10 นาทีนะครับ เพื่อฉะนั้นจำนวนครั้งการ invocation ใน 1 เดือน ก็จะเป็น 6 * 24 * 30 = 4,320 ครั้ง แล้วก็ใส่ spec ของ Functions ที่เราใช้ลงไป ได้แก่ CPU 400MHz และ RAM 256MB ตัว calculator ก็จะคำนวน GiB-seconds และ GHz-seconds ต่อเดือนออกมาให้เรานะครับ แล้วก็ผมประมาณปริมาณข้อมูลขาออกเป็นครั้งละ 1MB พอกด estimate calculator ก็จะบอกว่าใช้เงินเท่าไหร่

$0 ต่อเดือน! เพราะว่าแต่ละ service ของ Google เขาก็จะมี quotas ฟรีต่อเดือนให้กับทุกคนอยู่ครับ ซึ่งการใช้งานของเราต่ำกว่า quotas ที่เขาตั้งเอาไว้ เพราะฉะนั้นก็เลยใช้ได้ฟรีครับ
โดย quotas ฟรีต่อเดือนตรงนี้ไม่เกี่ยวกับ credits $300 ของเรานะครับ หมายความว่าเราสามารถรันตัวนี้ไปได้เรื่อย ๆ โดยที่ยังไม่ต้องเสีย credits $300 นี้ไปด้วยซ้ำครับ
BigQuery
BigQuery นี้ผมสมมุติให้เราเก็บข้อมูลนี้ไปเรื่อย ๆ แบบนานมาก ๆ เลยนะครับ จนพื้นที่ storage ของเรามีขนาดเป็น 10GB ไปแล้ว (ในปัจจุบันถ้าลองรันทิ้งไว้สัก 1 วัน พื้นที่ storage จริงจะใช้แค่ไม่กี่สิบ kB เท่านั้นครับ เพราะฉะนั้น 10GB นี่เป็น upper bound มาก ๆ ครับ น่าจะต้องเก็บไว้หลายสิบปีอยู่ 5555) แล้วก็ประมาณว่า ข้อมูลที่อัพโหลดขึ้นไปในแต่ละครั้งเฉลี่ยประมาณ 5 kB ดังนั้นในหนึ่งเดือนก็จะมีข้อมูลที่ insert เข้าไปเป็น 4,320 * 5 = 21,600 kB = 21.094 MB ครับ

เช่นกันก็คือเป็น $0 ต่อเดือน เพราะต่ำกว่า quotas ฟรีที่ให้นะครับ
service อื่น ๆ ก็เช่นกันครับ อย่าง Scheduler เขาก็ให้รันได้ฟรี 3 ตัวในแต่ละเดือน ส่วน Datastore เขาก็ฟรี storage 1GB และอ่าน/เขียนได้ฟรีเป็นหมื่นครั้งเลยครับ ซึ่งเราใช้เก็บแค่ last_id เป็นตัวเลขตัวเดียวเท่านั้น ก็ไม่มีทางเกินครับ เช่นเดียวกันกับ Pub/Sub ครับ คือมี quotas ขนาดของ message ตั้ง 10GB ไม่มีทางเกินเช่นกัน
Summary
บทความนี้อาจจะยาวนิดนึงนะครับ 55 คิดว่าน่าจะพอให้เห็นภาพคร่าว ๆ ของ Google Cloud service บางตัวว่าเอาไปใช้ทำอะไรได้บ้าง
แล้วก็ย้ำอีกครั้งนะครับ ตัว scraper นี้เอาไว้เพื่อการทดลองเท่านั้นนะครับ ไม่ควรไปปรับให้มันถี่ขึ้น หรือ scrape ข้อมูลเพื่อไปใช้หากำไรจนทำให้ผู้อื่นเดือดร้อนนะครับ
แล้วถ้ามีเรื่องไหนที่สนใจเพิ่มเติมสามารถ comment เอาไว้ได้นะครับ
FB Page: Copy Paste Engineer
อ้างอิง:
- Cloud Functions Pricing - https://cloud.google.com/functions/pricing
- Cloud Scheduler Pricing - https://cloud.google.com/scheduler/pricing
- Cloud Pub/Sub Pricing - https://cloud.google.com/pubsub/pricing
- Cloud Datastore Pricing - https://cloud.google.com/datastore/pricing
- BigQuery Pricing - https://cloud.google.com/bigquery/pricing

Top comments (5)
น่าจะคำนวณราคา กรณีเกิน free quota ให้ดูด้วยนะครับ. สมมติว่าไม่มี free quota ก็ยังถูกมาก เช่น แค่ $1 ต่อเดือน.
free quota ที่นำมาหักลบนี่ เป็น free quota ต่อเดือนครับ คือทุกเดือนจะได้ส่วนลดนี้ และจ่ายแค่ราคาเท่าที่คำนวณไว้ครับ ถึงจะหมดช่วง free trial แล้วก็ตาม
อย่างเช่นใน Cloud Functions Pricing Document แต่ละ section ก็จะมีเขียนคำว่า Free ไว้ชัดเจนให้สบายใจกันครับ55
รายละเอียดตรงนี้คิดว่าอาจจะสื่อผิดพลาดไปหน่อย เดี๋ยวจะอธิบายเพิ่มเติมในบทความต่อไปครับ ขอบคุณครับ
อยากรู้ว่า ถ้าใช้เยอะกว่านี้ 10 เท่าหรือ 100 เท่า จะต้องจ่ายเท่าไหร่น่ะครับ. คือจะได้ประเมินได้ว่า ถูกหรือแพง
พอเอา free quota มาคิด เป็น 0 หมด เลยประมาณอะไรไม่ได้เลย.
ได้เลยครับผม เดี๋ยวทำมาเป็นอีกบทความแยกต่างหาก
ระบบ pantip น่าจะมีระบบป้องกันไม่ให้ scrape เยอะๆจนเว็บล่ม
ถ้าจำไม่ผิดน่าจะเคยเจอ rate limit 429
Google Console มี app เช็คยอดเงินด้วย ไม่รู้ AWS มีหรือเปล่า