Apprentissage machine évolutif en Python avec Dask et Kubernetes …

Dask est une bibliothèque flexible pour le calcul parallèle en Python. Dask fournit une interface de planification des tâches, permet le calcul distribué en Python avec accès à la pile PyData. Dask fonctionne avec une faible surcharge, une faible latence et une sérialisation minimale nécessaire pour des algorithmes numériques rapides et s’exécute de manière résiliente sur des clusters avec des milliers de cœurs. Dask peut s’installer et utiliser un ordinateur portable en un seul processus. Conçu pour l’informatique interactive, Dask fournit une rétroaction et des diagnostics rapides :
Dask - Dask 2.1.0 documentation

Il est possible de lancer un scheduler Dask, des Workers et un serveur de Notebook Jupyter sur un cluster Kubernetes facilement en utilisant Helm.
Kubernetes - Dask 2.1.0 documentation
Dask déploie des workers Dask sur un cluster Kubernetes en utilisant les API Kubernetes natives. Ceci afin de lancer dynamiquement des déploiements de workers de courte durée pendant la durée de vie d’un processus Python.
Dask Kubernetes - Dask Kubernetes 0.9.0 documentation
Actuellement, Dask est conçu pour être exécuté à partir d’un pod sur un cluster Kubernetes qui a les permissions de lancer d’autres pods. Cependant, Dask peut également fonctionner avec un cluster Kubernetes distant (configuré via un fichier kubeconfig) à condition qu’il soit possible d’ouvrir des connexions réseau avec tous les nœuds du cluster distants :
Adding Dask and Jupyter to a Kubernetes Cluster
Pour cette expérience, je pars d’instance AMD EPYC chez Scaleway :

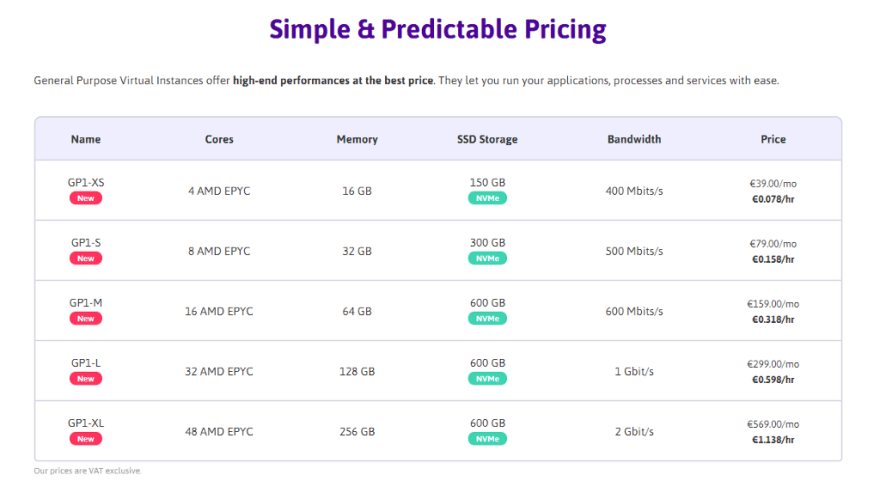
Deploiement de quatre noeuds pour la constitution rapide d’un cluster Kubernetes via Rancher encore une fois :

accompagné de ce script au démarrage :
#!/bin/bash
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
usermod -aG docker ubuntu
curl -s https://install.zerotier.com | bash
zerotier-cli join <NETWORK ID>
Déploiement du serveur Rancher :

qui une fois actif me permet de définir un cluster Kubernetes en mode HA :
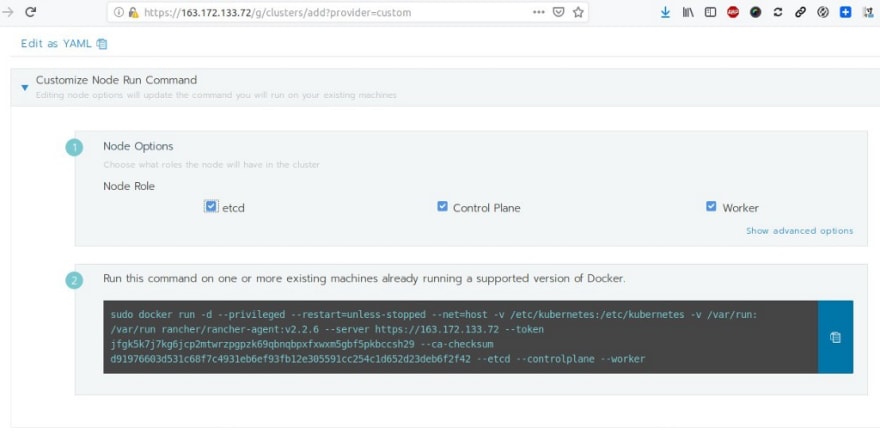
Déploiement des noeuds du cluster :


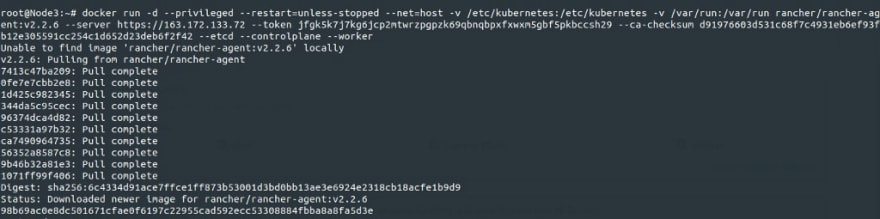
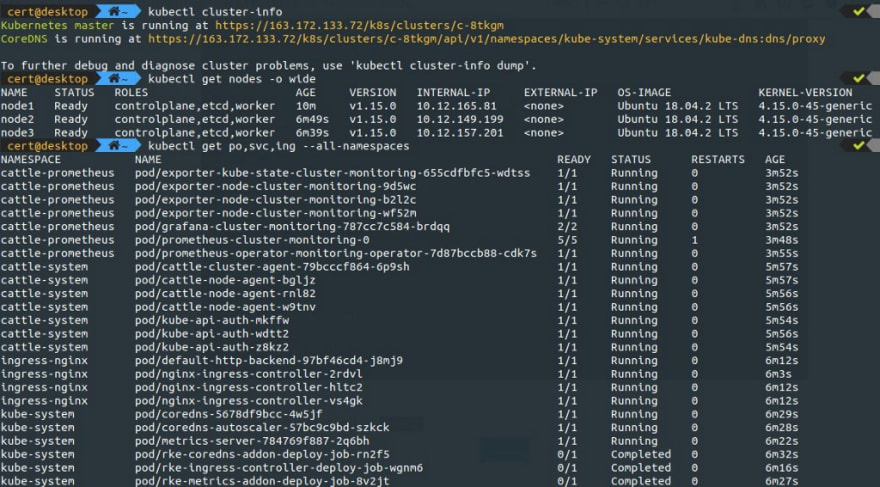
Le cluster Kubernetes est alors prêt :


Pour profiter d’un service de Load Balancing dans ce cluster, comme précédemment je déploie MetalLB :
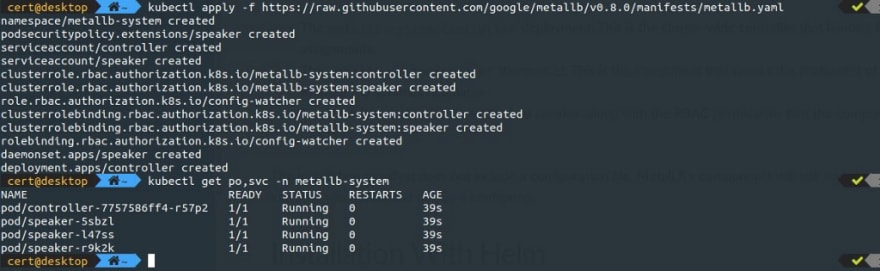
avec cette configuration :

qui résulte du plan d’adressage fournie par ZeroTier qui est déjà lié aux noeuds existants du cluster :

Pour déployer Dask dans ce cluster, j’installe au préalable Helm :


que l’on récupère dans son dépôt sur Github :

Je peux procéder à l’installation de Dask dans ce cluster Kubernetes avec son Scheduler, ses Workers et son serveur de Notebook Jupyter Lab :


On peut alors voir les éléments déployés par Dask :

dans cette structure :

Via les adresses IP fournies par MetalLB dans le cluster, je peux accéder au serveur Jupyter Lab :


mais également à l’interface web du Scheduler :
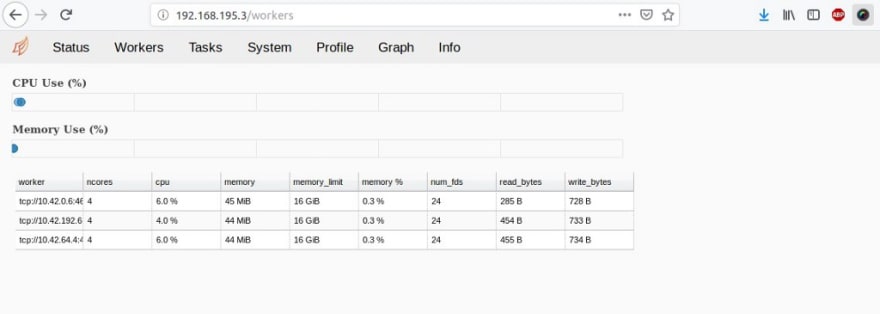
Les graphes dans l’interface web du Scheduler sont fournis via Bokeh, une bibliothèque de visualisation interactive :


Des éléments d’information que l’on retrouve également sur le serveur Jupyter Lab :


Test rapide de Dask avec ce notebook qui crée un tableau et calcule sa moyenne :

avec visualisation des tâches qui en résultent :
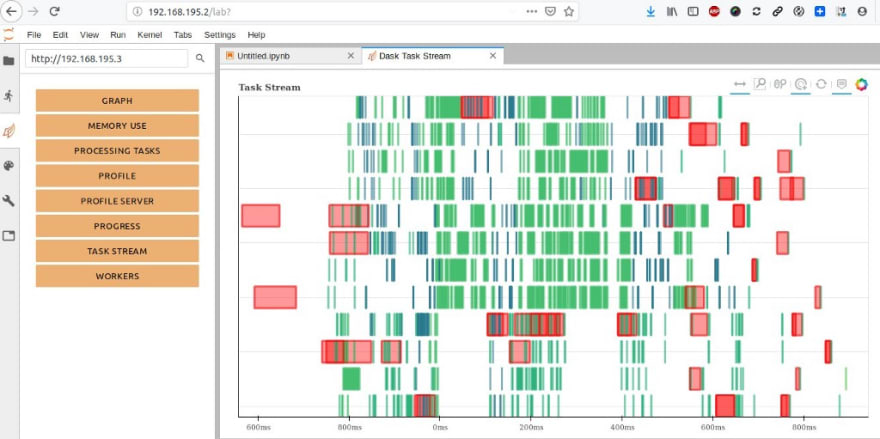


Je peux modifier le nombre de workers Dask dans le cluster Kubernetes toujours via Helm via un fichier de configuration :

Je mets ici à jour mon cluster Kubernetes avec quinze workers pour Dask :


Pour tester les capacités de calcul parallèle offerte par Dask, je vais reprendre ce Notebook sur la stratégie marketing des banques portugaises et qui utilise pour cela TPOT, un outil d’apprentissage machine automatisé en Python qui optimise les pipelines d’apprentissage machine en utilisant la programmation génétique :
https://medium.com/media/6c65491e3e820a42bd51a0711d81b05e/href
Les données exploitées dans ce Notebook sont liées aux campagnes de marketing direct d’une institution bancaire portugaise. Les campagnes de marketing étaient basées sur des appels téléphoniques. Souvent, plus d’un contact avec le même client était nécessaire pour savoir si le produit (dépôt bancaire à terme) serait souscrit (‘oui’) ou non (‘non’) :
J’installe au préalable Scikit-learn, une bibliothèque libre Python destinée à l’apprentissage automatique et conçue pour s’harmoniser avec d’autres bibliothèques libres Python, notamment NumPy et SciPy. Ainsi que Dask-ML qui fournit un apprentissage machine évolutif en Python à l’aide de Dask et de bibliothèques d’apprentissage machine populaires comme Scikit-Learn :
Dask-ML - dask-ml 1.0.1 documentation
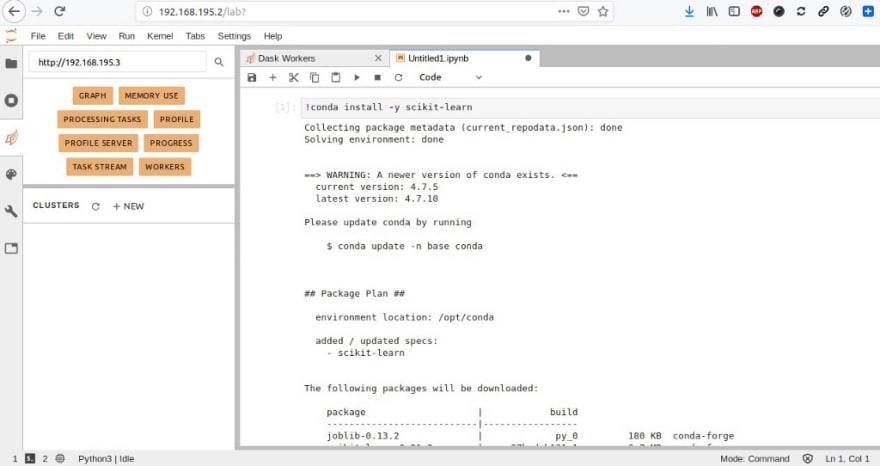

Je peux exécuter mon Notebook :
https://medium.com/media/2cfbba4798f4409a0a2bf262fc835faa/hrefhttps://medium.com/media/b5cb221c8657f83fe2bd87832397491d/href
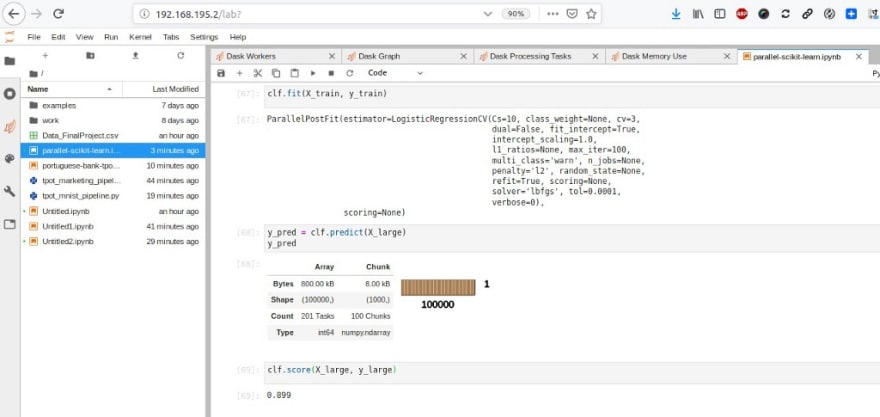
Dernier exemple avec ParallelPostFit et Scikit-learn pour paralléliser et distribuer les étapes de notation ou de prédiction via ce Notebook :
https://medium.com/media/790a120de5df256f34a0da40fab4a2b8/href





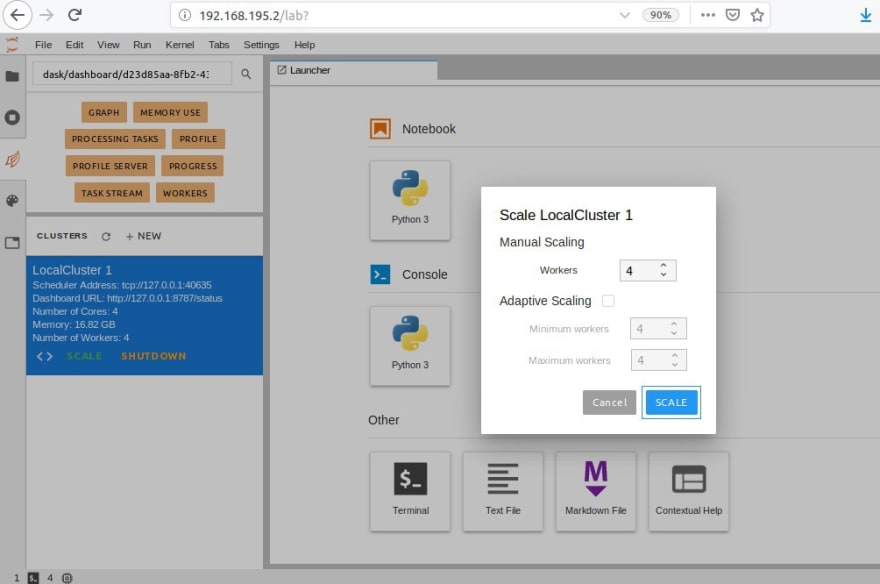
Il est possible de mettre à l’échelle le nombre de workers Dask directement depuis le serveur de Notebook Jupyter Lab :

L’utilisation du serveur Rancher permet de bénéficier du monitoring du cluster (et donc de ces workers Dash) via Grafana et Prometheus :





O n peut utiliser tout aussi facilement Dask pour constituer son cluster de Workers via Docker-compose localement sur une instance (chaque image Docker comprend Dask (y compris l’ordonnanceur distribué), Numpy et Pandas en plus d’une installation Miniconda, le tout sur la base d’une image Debian) :
A suivre ! …


Top comments (0)