
Initially I planned to write only about DOM and even wrote the first article. But I came to the conclusion that in order to fully understand some of the concepts, I need to touch a little bit on how the browser works. Then I decided - Why "a little"? Maybe no? That's what I've decided.
Now my article about DOM is this second article in the series. It's just like in Star Wars :)
In this article I will consider those basic things of browser work, which are most important for web developers.
How it all started
I'm not going to go into that, but to understand the context, I'll tell you a little bit about it. In the mid-90s, there were so-called "browser wars". Each company, in addition to its HTML, had its own versions of DOM and browser engines until W3C obliged all companies to standardize technology. A common standard has not yet been achieved, which is why we have to create cross-browser versions of web applications.
REMARK
Browser engine != Browser.
Often, the browser engine is equated with the browser. But that's not really true. All the engine does is parset and display the content. The browser, on the other hand, performs much more, more complex tasks. However, it is the different engine that makes us support all sites.
Browser architecture scheme
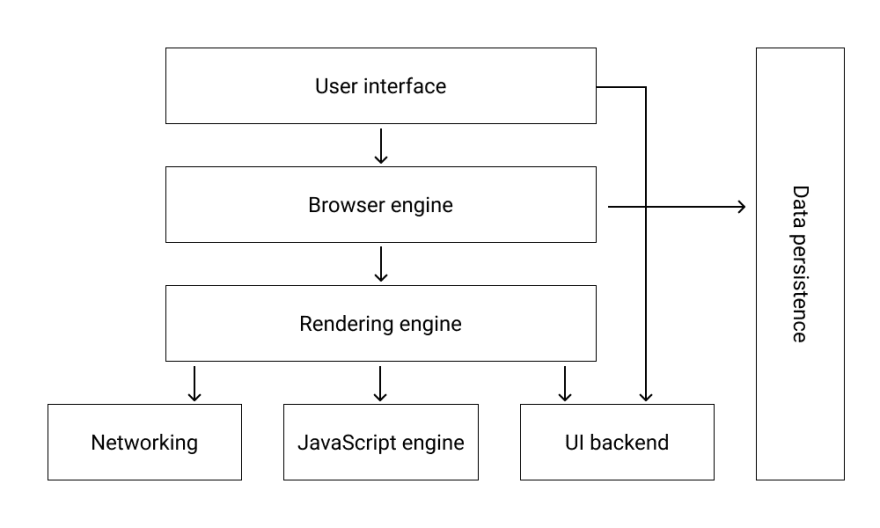
Okay, how does it all work?
While it's running, the browser runs several processes.

REMARK
The computer program itself is just a passive sequence of instructions. While the process is the direct execution of these instructions. The process can generate other processes as well as threads that share the resources of the parent process.
Since in this article we consider the browser in the context of web development, we are interested only in one process - rendering process.
IDEA
Maybe in the future, I'll take a closer look at the browser work.
For each tab, the browser launches this process. Moreover, modern browsers also run the rendering process for each iframe. This is done in order to isolate each tab and iframe. And if any child process fails, kill it, not the main process. It's called site isolation.
The rendering process runs threads. We will only consider the main thread. Almost all the work in the rendering process is done by browser engines.
The main engines at the moment are:
- Blink.
- Gecko
- WebKit
REMARK
During development, you should also considerEdgeHTML, but soonMicrosoftwill completely abandon it.
Now let's take a look at what happens when drawing a page.
this is a simplified model

First of all, resources (HTML and CSS) are parsed and converted to object trees. They are combined and another tree is constructed based on them - the render tree. This tree contains only those elements that will be drawn on the screen.
REMARK
An element with the styledisplay: none- will not be contained in this tree. Because the element does not have its own visual representation.
After that, a walk through this tree to calculate their size and location on the screen. This process is called layout (or flow in Firefox).
Then, all calculated elements are drawn onto the screen.
Let us dwell on each point.
HTML parsing.
Many parsers are based on context free grammar, which allows them to work very efficiently. But the main problem with parsing HTML is that it cannot be defined usingcontext free grammar. This is because the browser needs to keep track of how HTML is written. If the tag is not closed somewhere, then the browser will close it and so on. Even if you do not make mistakes, this feature slows down parsing very much.
Another important feature of HTML parsing is how it reacts when it encounters the <script>tag. Parsing stops until the script is executed and only after that continues to work. This is why you should place scripts before the </body> tag or use async and defer. async anddefer - allow loading scripts in parallel with parsing.
REMARK
deferdiffers in that it guarantees the execution order.
It should be noted that if there are very large scripts, the browser starts to allocate separate streams and tries to optimize the download.
A similar situation occurs when the parser encounters CSS. Style loading blocks parsing.
CSS parsing.
CSS parsing is free of such problems as when parsing HTML and, in principle, is no different.
Attachment
At this point, the render tree` begins to be constructed.
Layout (Flow)
After the render tree is formed, the position and geometric dimensions of the elements of this tree are calculated.
The speed of layout directly depends on the quality of the CSS you wrote.
What does it mean?
This means that each CSS rule needs to be applied to a separate DOM node. This is achieved by recursively traversing the HTML tree, another tree - the CSS tree. And the more difficult it is to write CSS, the longer it will take.
CSS - selectors are not equal in performance.
The most productive are: #(id), .(Class) Slightly less productive - type(for ex. - h1)
Combinations of attributes are not productive, and the most not productive are pseudo elements.
REMARK
There are variouscss methodologieswhich are based on productive selectors.
Painting
Here the image is constructed and sent to the GPU to draw it onto the screen.
that's how the layout process goes

REMARK
source
In browsers, in devtools you can enable a mode that will show the rendering of elements.
Conclusion
We examined the main points of the browser. In some of the following articles, we will touch upon a few more interesting points.
Afterword.
Thank you very much for your attention. I hope it was useful for you 🙏
Follow me, it makes me write new articles 😌
I'd be happy for your feedback.
C u! 😉


Top comments (0)