Hello! Today I'd like to talk about the problem of publishing images. Why talk about this at all? Every day, millions of people publish millions, or even billions of images - what's there to discuss? Surely for a web developer, especially an experienced one, this isn't a problem at all. Well, not quite.
I'll start by describing the perspective from which I personally look at this issue. Perhaps this will add some color to the technical narrative.
I'm a full-stack developer who specializes in projects with a significant R&D focus. I often need to publish side artifacts of my work, such as web pages with documentation, technical articles, interactive demos, prototypes and experiments, promotional pages, and so on. Naturally, all of this needs to be illustrated with interface screenshots, diagrams, various render examples, and other cat photos.
At the same time, I prefer approaches and practices that minimize context switching and the proliferation of entities I have to interact with. This allows me to be more effective. I write docs and articles directly in my IDE, in markdown format, and store them in git. Building and publishing to the web happens automatically through git hooks and actions. This makes collaboration with technical colleagues comfortable, and our common business processes more lightweight. Ideally, I want images to be part of this zen too. But...
The first "chicken and egg" question: to place an image on a page, you first need to get its URL. The simplest way, at first glance, is a relative path. You simply save the image somewhere in your project structure and publish it along with other files.
CDN
We don't want to store images in git. I hope you don't either. Especially if there are many of them. Because it increases repository size, slows down cloning and synchronization, increases build time, and so on. We want the images to be separate, somewhere in the cloud. Preferably in a special CDN, to avoid burning extra traffic from our main server and to speed up page loading for our respected readers and users. Using such CDNs has long been an established best practice.
We face a new question: how do we reconcile our lightweight workflow with the need to interact with a separate external service? After all, we still need convenient collaboration and automation, and that feeling of superiority over those who do everything manually through various inconvenient third-party UIs...
What else needs to be considered: CDN services typically create a flat storage structure where there's only a unique identifier for the uploaded asset and nothing more. Yes, often you can get additional metadata through a separate request using your API access key, but this isn't always convenient or applicable.
Adaptivity
In today's world, it's not enough to just insert an <img> tag with a src="..." attribute. We need to take care of users with different screens having different pixel densities. Otherwise, some will see "blur" while others will download more useless megabytes (which we'll pay for). We also need to take care of the optimal format (webp, avif, etc.). And on top of everything else, we need different image sizes simultaneously for different possible layouts (mobile, desktop, etc.).
It's good that CDN services handle the preparation of multiple variants, and we don't need to worry about their generation. But the HTML insertion code that takes everything into account becomes quite cumbersome, and we don't want to write it manually each time. Instead, we want to have a convenient tool that will do this automatically, in accordance with our settings.
Dream Web Media Asset Management
So, let me describe my ideal solution within the described goals. Here's an approximate list of what I want:
- Collaborative work with the project's media collection through Git (but without uploading original images to the repository)
- Automatic synchronization of local media directory with CDN (Like in Dropbox, roughly: drop files in a folder, and they automatically fly to the cloud)
- Mandatory support for local directory structure (mapping nested folder addresses to file ID in CDN)
- Generation of HTML insertion code with support for adaptiveness, lazy loading, and other modern features (srcset, sizes, loading="lazy")
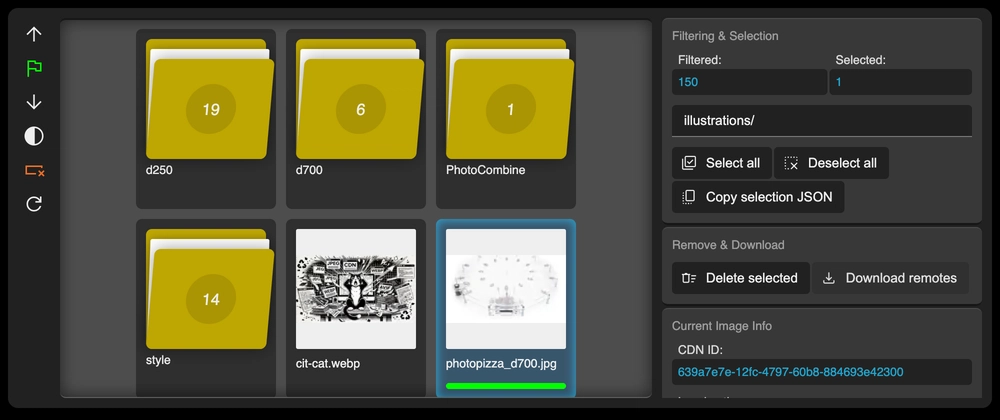
- Ability to sort and filter images by metadata
- Ability to view and edit cloud collections without the need for all process participants to have local file copies
- Ability to download and save local copies when needed
- Storage of upload data in a format convenient for use in CI/CD pipelines and any other automatic processing (JSON)
- Locally available web management interface without the need to create an additional account and authorize in a separate service
- Binding cloud collections to projects, as well as the ability to use shared resources across different projects
- Solution lightness. Absence of endless dependency lists. Simplicity for auditing and modifications
- Independence from CDN service provider
A Bit More Personal History
I've been dealing with the technical side of this image kitchen for a long time. Once, I led a startup: we were making a service for publishing 360-photos. 360-photos is an interactive display method that allows you to view an object from all sides using a sequence of photos taken from different angles. You've probably seen this on some online store pages where products can be rotated with the mouse. That startup didn't survive, but it left behind rich experience applicable in many aspects. A peculiarity of that project was uploading a VERY large number of images by users: more than a hundred source photos might be needed for just one interactive publication.
Some time later, I was responsible for developing a set of widgets for uploading and displaying files at a company - a specialized CDN provider, one of those I mentioned above.
Besides this, I constantly experiment and publish something, both for my current projects and for fun. And despite all my experience, I haven't found a ready-made solution that would fully satisfy both myself and my team. At one perfect moment, we finally got fed up with this, and we decided to make our own.
CIT - Cloud Images Toolkit
I don't want to be accused of self-promotion, so I'll immediately clarify that we're talking about a free Open Source tool that isn't monetized in any way. My main goal is to share with the audience the story of a specific solution, as well as the approaches that we, as a team, developed in the process. Goal number two is to try to get feedback and motivation for further development of a useful tool.
So, CIT (Cloud Images Toolkit) is a web developer's workspace tool that allows automating the process of working with media content in web projects. It includes a utility for synchronizing a local directory with CDN, as well as a web interface for viewing and managing image collections.
Project GitHub link: https://github.com/rnd-pro/cloud-images-toolkit
At the current stage, CIT is adapted to work with the Cloudflare Images CDN service but is, in principle, independent of it. If there's interest, we can add built-in support for any other providers. But adapting it for your service is not a complicated matter, and you can add it yourself if needed. Later I plan to write a simple instruction on how to do this in Node.js.
Installation:
npm install --save-dev cloud-images-toolkit
Configuration (cit-config.json) in the project root:
{
"syncDataPath": "./cit-sync-data.json",
"imsDataPath": "./ims-data.json",
"imgSrcFolder": "./cit-store/",
"apiKeyPath": "./CIT_API_KEY",
"projectId": "<YOUR_PROJECT_ID>",
"imgUrlTemplate": "https://<YOUR_DOMAIN>/images/{UID}/{VARIANT}",
"previewUrlTemplate": "https://<YOUR_DOMAIN>/images/{UID}/{VARIANT}",
"uploadUrlTemplate": "https://api.cloudflare.com/client/v4/accounts/{PROJECT}/images/v1",
"fetchUrlTemplate": "https://api.cloudflare.com/client/v4/accounts/{PROJECT}/images/v1/{UID}/blob",
"removeUrlTemplate": "https://api.cloudflare.com/client/v4/accounts/{PROJECT}/images/v1/{UID}",
"variants": ["120", "320", "640", "860", "1024", "1200", "2048", "max"],
"imgTypes": ["png", "jpg", "jpeg", "webp", "gif", "svg"],
"wsPort": 8080,
"httpPort": 8081
}
What to pay attention to here:
imgSrcFolder - path to the local directory with images, which should be added to .gitignore, along with the file specified in apiKeyPath;
Image size variants and their formats are set in the config. During synchronization, CIT automatically generates all variants for each image using URL templates. It's important that your CDN supports automatic resizing and format conversion. In the case of Cloudflare Images, this is done in the service settings. Variant names should contain the image size in pixels, or the keyword max for the original. For example, if your template uses an image with a width of 320px, then you need to add variant 320 and variant 640 for screens with double pixel density.
Mapping of the local directory structure is implemented through a string containing the local path to the image. For filtering images in the UI, its substring is used, so it's desirable to ensure that folder names are unique where possible and the overall collection structure is meaningful.
IMS - Interactive Media Spots
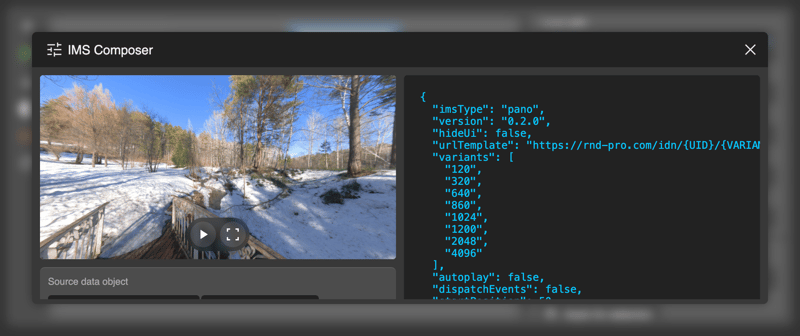
CIT supports generating interactive widgets using your cloud images. For this, the OpenSource (MIT) widget library - IMS (https://github.com/rnd-pro/interactive-media-spots) is used.
Conclusion
If you have questions about implementation and usage - write, I'll be happy to answer them in the comments. The project is very young and is currently actively used as our internal working tool, so, of course, I'll be glad for any feedback, stars on GitHub, and suggestions for improvement or collaboration.
And of course, we have plenty of our own plans for developing the tool. For example, built-in image generation using AI, prompt management, auto-generation of descriptions (alt) for better SEO, support for video collections (streaming video), a dashboard section for working with IMS object collections, splitting the media collection description file into parts and managing different collections... And so on.
Thank you for your attention.

Top comments (0)