
The start
I have always been interested in artificial intelligence, thats why I have begun to acquire some knowledge about it.
In the last few days I have begun my path from a simple programmer to someone who knows at least a bit about about AIs for then focus my efforts on machine learning. in these few days, this is what I have learned.
Everything began with this youtube video. Besides being 3 years old is still a good starting point for a newbie in artificial intelligences. It talks about AIs in general and their story, the 3 winters, the current situation, and the difference between AI and machine learning.
From this, I have gone through all the resources that I have collected and in few days I have learned all the theoretical knowledge needed to begin machine learning.
The first thing to know is what exactly is machine learning, and all the definitions will be similar to:
Machine learning is the study of algorithms that improve through experience gained from data to make decisions or predictions.
It's then important to know some of the main machine learning problems so that you not only can really know why you are doing it but even to explain it to friends/curious people. And those problems are the ones where manual solutions will not work. It will be too difficult and time-consuming to invent an algorithm that can differentiate between spam and not spam emails, that can detect a face or that can even understand a speech - that's why we create one that can learn how to do it.
But machine learning problems are not so easy to detect - those are in general problems were you know just the scope of the goal but not how to achieve it and where the person cannot map all the decisions that the program will have to make.
Just knowing this we can now proceed through
The types of machine learning algorithms
Supervised learning: input data is called training data and has known labels or results; such as it is spam or not spam. The model is prepared through a training process in which it has to make predictions and get corrected when those predictions are wrong.
Unsupervised learning: input data is not labeled and does not have a known result. A model is prepared by deducing structures present in data input to extract general rules by organizing data by similarities or by reducing redundancy.
Reinforcement learning: The AI learns by trial and error and the aim is to be able to do some kind of skill. An example will be an Ai made to play chess or go.
The scope of a machine learning AI is to use data to achieve the right level of accuracy. - why the "right" and not the "most high"? We'll find the answer only by reading.
To understand better the concept of accuracy you can play a bit on machine learning playground.
Let's say we are making an algorithm for a restaurant and after analyzing the habits of a client we get a graph similar to this:
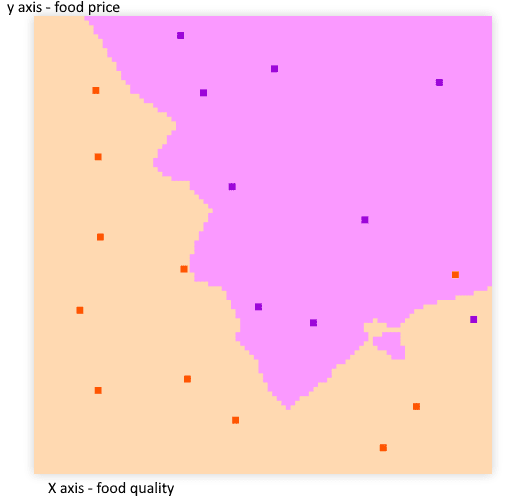 (made on machine learning playground with the k nearest neighbors algorithm and parameters of k: 3 - If you don't what does mean, don't worry, neither do I. The scope of this series of posts will be to finding it).
(made on machine learning playground with the k nearest neighbors algorithm and parameters of k: 3 - If you don't what does mean, don't worry, neither do I. The scope of this series of posts will be to finding it).
Highlighted dots are what the customers liked/not liked.
Now we know what kind of food would like the customers the next time he'll be at the restaurant.
To better assess what you need to know exactly about machine learning I advise you to read this article by machine learning mastery on finding your machine learning tribe.
practical theory
the following section will be in good part a summary of what's written here.
We can divide the main part of a machine learning project in:
Problem definition
We use machine learning when simple code will not work, but how do we exactly define problems in this field?
We have defined the types of algorithms and now we'll define the types of models that these algorithms have.
The types of problem that need supervised learning are:
- classification: "Is this a thing or another one?". We have data and we have to classify it into categories with predetermined labels. When the classification is between 2 options it's called binary classification, when is between more than 2 options it's called multi-class classification.
- Regression: we have to predict what will follow a relationship between two variables, we may use it to answer questions as "what's the correlation between exercise and weight?".

Unsupervised learning:
Cluster: we use it for creating labels between data, for example, if all data are orange or apples we can expect a clustering algorithm to create labels for the images with orange and another label for images with apples.
 source
sourceAssociation rule learning: we use it to discover the relationship between different kinds of data, for example:
meat + bread = hamburger.

Transfer learning:
The art of using foundational patterns of another AI to make another one that has to resolve a similar problem.
 source
source
Matching the problems
We use supervised learning when the input and the output are known. An example may be when output data are speeches and we want a program that is able to understand the words for then write them in a file.
We use unsupervised learning when we have just inputs. An example may be if a company has to sell houses but has only the price of when they were bought and their condition now, but not how should be valued exactly.
We use transfer learning when our problem is similar to the one that another AI has already resolved. An example can be if I have to detect if there is a dog in an image and another AI can detect if there are oranges in an image.
Types of data
We have two different types of data:
- structured data. An example may be excel papers.
- unstructured data. An example may be photos and videos.
these two types of data may then be:
- static, when data doesn't change.
- streaming, when data get updated or we know that will change in some way or another.
Evaluation
Then we define what success means for us, but to really understand this concept it's better to see the choosing and tuning section.
Features
The feature of every single piece of data in a collection of data is important in machine learning. Ideally, all the data have the same features.
Their name practically explains themselves:
-numerical features. For example in a data collection of am hospital patients with heart diseases, their height.
-categorical features. Using the same example above, the sex of the patients.
-derivated features. Features that came from already existing features, as if a patient with heart disease already came into the hospital in the last years.
The various types of features introduce the concept of features coverage, that explains what is the cover of a feature in all the data collection. It asks "how many data have different features?"
Modelling
The most important part of a machine learning project is modeling, and is divided into 3 phases:
Choosing and training a model
After you have chosen the model you have to train it, and to do it you need data samples.
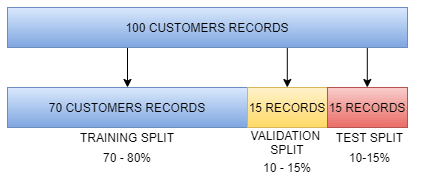
To train a model effectively we split the data into 3 parts:
- training samples.
- validation samples.
- test samples.
Then we have to divide those samples:
 made with draw.io
made with draw.io
The use of training samples is to train our AI into understanding the problem for making the right decisions/predictions, they are usually between 70 - 80% of the samples.
The use of validation samples is to tune our AI to define what parameters suit better the task, they are between 10 - 15% of the samples.
The use of test samples is to see what results will accomplish the AI in the real world, they are between 10 - 15% of the samples.
This concept is called generalization: the ability for an AI model to perform well on unknown data.
Example:
 made with draw.io
made with draw.io
Choosing and tuning
when we train a model we can choose different levels of accuracy depending on what the AI will have to do.
One goal of machine learning is to minimize the time between experiments. The concept of AI training will result in something very similar to this:
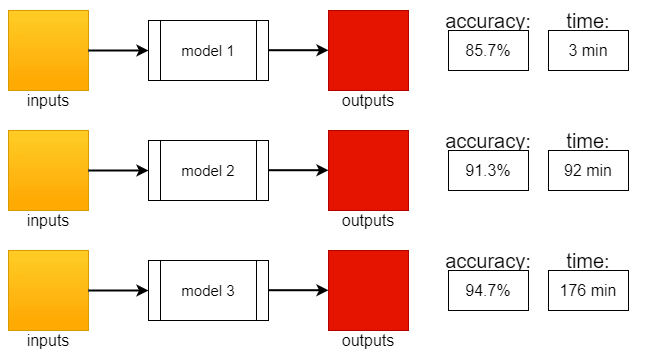 made with draw.io
made with draw.io
Of these 3 models, what do you think is the better?
It depends. to achieve just a bit more accuracy we have to sacrifice much more time, and if the sacrifice is worth is something that only depending on what we have to do can be decided.
Sometimes accuracy will be more important, other times will be the time.
From this section we can extrapolate the main point to always remember:
- Some models work better than others in different problems.
- We have to try many different things.
- It's very efficient to start small and add complexity as we go on.
To exactly tune our model we'll have to modify the hyperparameters, something that will be concretized later, for no,w you can play a little with the parameters under the various algorithms in machine learning playground to have at least a basic idea.
Comparison
We use the last set of data to see how our AI will perform in the real world, but in this phase, we can have 2 problems: underfitting and overfitting
Underfitting is usually caused by data mismatch - the data used for training were too different from the actual data, while overfitting may be due to data leakage - the training data were too similar, if not the same, to the test data.
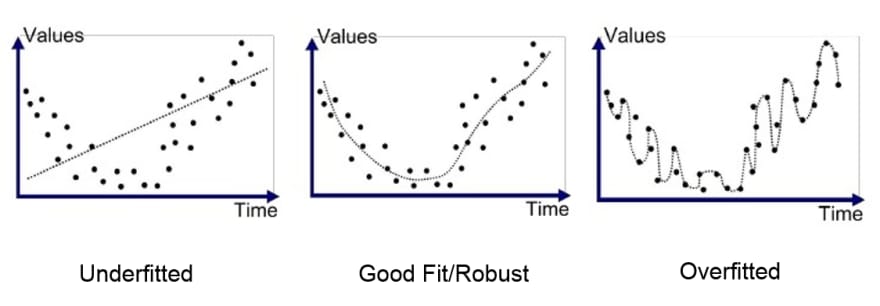
Ways to fix underfitting may be:
- trying more advanced models.
- increase model hyperparameters.
- reduce the number of features.
- train longer.
Ways to fix overfitting may be:
- collect more training data.
- try a less advanced model (very rare, but may happen).
The end (for now)
This is all the theory that you need to begin machine learning.
what will come next will be practice and, believe me, it will be a lot of fun.





Top comments (1)
Very nice . Are you going to get started with programmming after this ?