
In recent months, the landscape of Large Language Models (LLMs) has been transformed by groundbreaking developments in LLMs like GPT-4, Gemini, and PaLM v2. These innovations have not only revolutionized the industry but have also set a new standard for what's possible in the realm of artificial intelligence.
At the same time we have seen a huge rise in local LLMs like Mistral and Llama 2. Now, individuals with the requisite technical skills can tailor and deploy these powerful models on cloud-based platforms or local servers. This shift towards greater accessibility has effectively democratized LLM technology, enabling a broader spectrum of users to explore and leverage its vast potential.
As the barriers to accessing state-of-the-art models continue to lower, the time is ripe to formulate a strategic approach for deploying LLMs effectively. A pivotal aspect of this strategy involves evaluating the pros and cons of hosting LLMs on cloud-based versus local servers.
In this blog, we will delve into the nuances of choosing between Local and Cloud LLMs and understanding the best LLM for coding based on specific use cases, while also covering how you can access both Local and Cloud LLMs in Pieces Copilot.
What are Large Language Models?
A Language Model (LM) is a type of machine learning model designed to generate sequences of words based on some initial input. The term 'Large' in Large Language Models (LLMs) distinguishes these models from their smaller counterparts by their extensive training on vast datasets and their significantly larger number of parameters. This extensive training and complexity enable LLMs to possess a broader knowledge base and deliver more detailed and accurate responses to user queries for various programming languages.
In recent developments within the machine learning domain, there's been a notable shift towards the open-sourcing of language models. Pioneering this trend, companies like Meta AI have made their LLMs fully open source, providing public access to the research papers, datasets, and model weights.
This revolutionary approach in the field of artificial intelligence (AI) empowers developers to deploy these models directly onto user hardware, offering unprecedented opportunities for customization and application-specific tuning.
Local vs Large LLMs: Pros and Cons
The evolution of Large Language Models (LLMs) has presented a pivotal choice for users: deploying these powerful tools on cloud-based platforms or running them locally. Each approach comes with its unique set of advantages and challenges. Let's dive into a detailed comparison to help you make an informed decision.
Advantages of Cloud-Based LLMs
- Scalability Aspect: Cloud platforms excel in providing scalable resources, essential for the computationally intensive tasks of training and deploying LLMs in production. They can effortlessly handle demands for high-end GPUs and vast data storage, adjusting resources as needed.
- Ease of Use: Cloud services simplify the development process with a plethora of APIs, tools, and frameworks, streamlining the building, training, and deployment of machine learning models.
- Cost Effectiveness: For those without access to advanced hardware, cloud services offer a cost-effective alternative. You pay only for what you use, often at rates more affordable than maintaining high-end GPUs and CPUs in-house.
The operational burden of setup, maintenance, security, and optimization is managed by cloud providers, significantly reducing user overhead.
Challenges of Cloud-Based LLMs
- Limited Control: Users may find themselves with limited control over the infrastructure and implementation details when relying on cloud-managed services.
- Data Privacy and Security: Using Cloud LLMs involves sending your data to the cloud service, which potentially puts the data at risk.
- Costs at Scale: Despite the pay-as-you-go model, the expenses of training and running LLMs on the cloud can accumulate, especially at scale.
- Network Latency: Real-time applications may suffer from delays inherent in cloud-based model communication.
Advantages of Running LLMs Locally
- Control: Local deployment grants users complete control over their hardware, data, and the LLMs themselves, allowing for customization and optimization according to specific needs and regulations.
- Latency: Local LLMS can significantly reduce latency since the model is running locally
- Privacy: Running LLMs locally enhances data privacy and security, as sensitive information remains within the user's control and on the device and is not being shared with a cloud vendor.
Challenges of Running LLMs Locally
- Upfront Investment: The initial setup for local servers can be very expensive, requiring significant investment in hardware and software.
- Complexity: The operational complexity of maintaining local LLMs can be daunting, involving extensive setup and ongoing maintenance of both software and infrastructure and including engineering steps like fine-tuning and custom training of the models.
What’s the Best LLM for Coding?
Determining the best coding LLM depends on various factors, including performance, hardware requirements, and whether the model is deployed locally or on the cloud.
When it comes to the best offline LLM, Mistral AI stands out by surpassing the performance of the 7B, 13B, and 34B Llama models specifically in coding tasks. This makes Mistral a compelling choice for those looking to run an LLM locally, especially considering its competitive edge in code-related applications.
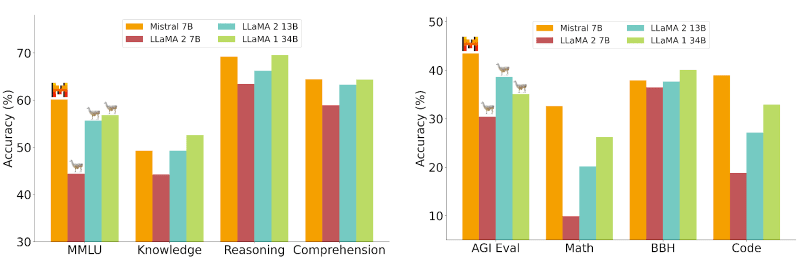
Source: https://mistral.ai/news/announcing-mistral-7b
However, when comparing the best open source LLM models like Mistral to cloud-based models, it's important to note that while Mistral significantly outperforms the Llama models, it still falls short of the capabilities of GPT 3.5, and hence all the other cutting edge cloud LLMs like GPT-4 and Gemini. This distinction is crucial for users prioritizing performance over the deployment method.
Hardware requirements also play a critical role in the selection process. The Llama 7B model requires approximately 5.6GB of RAM, whereas Mistral demands slightly more, at about 6GB. This difference, though marginal, may influence the decision for users with limited hardware resources.
In terms of the best online LLM, Google's recent introduction of Gemini Pro and Ultra, alongside the existing GPT-4, adds to the diversity of options available. A study by Google comparing the performance of Gemini models with GPT-4, Palm v2, and others offers valuable insights into their capabilities and potential applications.
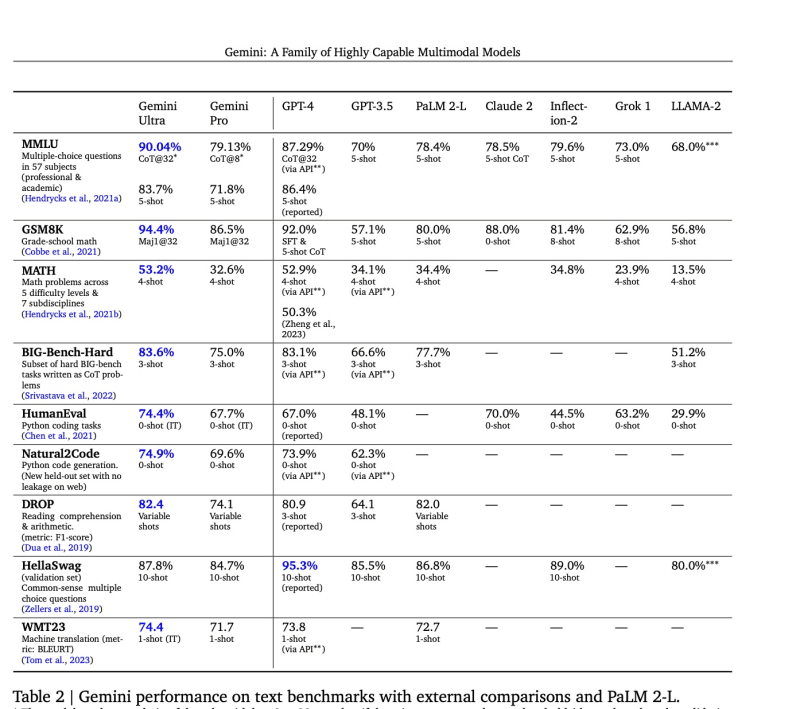
Source: https://storage.googleapis.com/deepmind-media/gemini/gemini\_1\_report.pdf
For developers and organizations evaluating the best LLM for code generation and other development tasks, these considerations—performance, hardware requirements, and the choice between local and cloud deployment—should guide their decision. Ultimately, the "best" LLM for coding will vary based on specific needs, resources, and objectives.
How to Choose a Large Language Model
If you’re wondering how to choose an LLM model, or rather which LLM is best for coding, there are a number of factors that you should consider.
Scalability Needs
Assessing the number of users and the volume of models required to meet your operational demands is crucial. If your application needs to scale dynamically or you plan to use the data to further refine your models, a cloud-based solution might offer the flexibility and scalability required to accommodate these needs efficiently.
Data Privacy and Security Requirements
For organizations operating in sectors where data privacy and security are of utmost importance, and where compliance with stringent data protection regulations is mandatory, an on-premises deployment could be essential. Going with the best local LLM provides greater control over data handling and security measures, aligning with legal and policy requirements.
Cost Constraints
Budget considerations play a significant role in the decision-making process. If budgetary limitations are a concern, yet you have the necessary hardware infrastructure, opting to run LLMs locally might be a more cost-effective solution. This can minimize operational costs, provided that the initial setup and maintenance requirements are within your capabilities.
If you’re asking yourself “which LLM should I use?”, you also need to consider which AI code generation tools you can afford to leverage. For example, GitHub Copilot costs around $19/mo around the time this article was published, so you may want to look for free GitHub Copilot alternatives that support many of the best LLM models, such as Pieces.
Ease of Use
The complexity of deploying and managing LLMs should not be underestimated, especially for teams with limited technical expertise or resources. Cloud platforms often offer user-friendly, plug-and-play solutions that significantly reduce the technical barriers to entry, making the process more manageable and less time-consuming. However, may consider an offline AI tool that works directly in your browser, IDE, and collaboration tools for less context switching.
Use the Best Code Generation LLM with Pieces
Pieces Copilot is engineered to cater to the diverse needs of your workflow by offering a wide array of Large Language Model (LLM) runtimes, both cloud-based and local. This flexibility ensures that regardless of your project's requirements, Pieces Copilot has the right tools to support your endeavors, including the best code LLMs.

Cloud LLMs in Pieces
OpenAI Offerings:
- GPT-3.5 Turbo: A highly optimized LLM designed for swift and precise responses, making it ideal for time-sensitive tasks.
- GPT-3.5 Turbo 16k: This version utilizes an expanded parameter set, providing an extended context window of 16,000 tokens for more detailed inquiries.
- GPT-4: The latest from OpenAI, offering unparalleled context understanding and the ability to tackle more complex tasks than ever before.
- BYoM: Add your own custom OpenAI key if you’re working with an existing enterprise license, and want to maintain that intelligence while leveraging it within your favorite tools.
Gemini by Google:
- Gemini Pro: Google's flagship AI model, multimodal in nature, capable of executing a broad spectrum of tasks with remarkable efficiency.
PaLM 2:
- Chat Bison: A developer-centric model, optimized for grasping multi-term conversations, enhancing user interaction.
- Code Chat Bison: Specially fine-tuned to generate code from natural language descriptions, bridging the gap between idea and implementation.
Local LLMs in Pieces
- Llama 2: Developed by Meta AI, this model is fine-tuned for general tasks and is available in both CPU and GPU versions, requiring 5.6GB of RAM and VRAM, respectively.
- Mistral 7B: A dense Transformer model, swiftly deployed and fine-tuned on code datasets. Despite its size, it's mighty, outperforming Llama 2's 13B and 34B models in most benchmarks. It requires a minimum of 6GB RAM for the CPU model and 6GB of VRAM for the GPU model.
Important Considerations
Local LLMs demand significant hardware resources. Ensure your system meets these requirements before proceeding. For older machines or those with limited RAM, cloud LLMs, starting with Llama 2's 7 billion parameter model, are recommended due to their lower hardware demands. There is plenty of discussion on the best GPU for LLMs run locally without a definitive answer, but you can explore more on that here. If you aren’t sure whether or not your hardware can handle it, choosing the CPU model is recommended.
Seamless Model Integration and Switching
Pieces Copilot not only simplifies the process of downloading and activating these models but also allows for effortless switching between them mid-conversation. This feature ensures that you can always use the model best suited to your current task without interruption, showcasing the seamless integration of cloud and local models within Pieces.
Let’s take a look at how to choose between cloud and local LLMs in Pieces Copilot:
If you are interested in how to build a copilot using local LLMs with Pieces OS endpoints, then checkout this blog post from our open source team.
So, Which LLM is the Best?
With Pieces Copilot, you're equipped with the best open source LLM and cloud-based LLM options, ensuring your workflow is as efficient and effective as possible. Whether you opt for the scalability and ease of cloud runtimes or the control and privacy of local models, Pieces Copilot is here to support your journey by further fine-tuning all LLMs and enabling you to add AI context to get the most out of your LLM context length. That being said, Gemini seems to be the best LLM for question-answering and GPT-4 the best LLM for writing code.
Conclusion - Which LLM is Best for Me?
In this blog, we've explored the advantages and disadvantages of deploying Large Language Models (LLMs) on cloud platforms versus local servers. Choosing the best LLM and the optimal deployment strategy hinges on several key factors, including the LLM's size and complexity, the application's specific requirements, budgetary considerations, and the need for security and privacy. It's also noteworthy that, in many coding-related tasks, cloud-based LLMs tend to outperform their local counterparts, offering superior performance and efficiency.
If you want to further the conversation, join our Discord server and let us know what you think is the best LLM for coding!

Top comments (0)