Guidelines for a newly formed team on building a CI/CD Infrastructure and development process
This is the English version of the article. Thanks to Akkarine!
A little over a year ago I witnessed how an entire web development department, which I got to manage, grew out of an internal project of a company that has nothing to do with IT. The workflow seemed to have settled down, and everybody was fine with it, but there were still some problems:
- Each branch was checked locally. We had to roll back the changes from the previous check in the database, build the front end. When several developers were about to finish their work that needed to be checked for the small details, it turned into a living hell;
- The production and dev (development) environments were different, which led to this kind of errors: “It works on my machine”.
My inner perfectionist was desperate to organize everything in the right way. Here I am sharing the results of my search for an answer to the question: “What actually is the right way”?
Our achievements:
- easy and fast deployment in production (for the sake of experiment, we deployed every day for two weeks straight);
- a guarantee of protection against errors caused by differences in the application environment;
- got possibility to effective interaction with the customer:
- demonstrating each feature branch;
- providing guest access for task creation and monitoring the progress of work.
This article will be useful if:
- you are a young IT company, or it’s your first teamwork on a large project;
- you want to bring your old development workflow up to date;
- you are looking for the best practices and want to see how others do it;
- you often come across articles about DevOps, CI/CD, clouds; want to create test environments at the touch of a button, and be sure that every next production update is not Russian roulette.
You will find:
- typical workflow from task to release;
- infrastructure solution for building any modern development process using the minimum number of tools;
- example for a common case: web application development.
The article consists of three parts:
- my vision of a typical development process;
- an infrastructure for the implementation of any modern workflow;
- a case for web development.
Search for information, relevance of the issue
While searching for the best practices, I came across a lot of theory on methodologies, different tools, but the information was scattered. There wasn’t anything that showed a single process from the point of view of a manager, developer and system administrator (à la DevOps). For example, these articles with abstract discussions on the development process leave unanswered questions: “Well, okay. And what tools should I use to do this?”
There is a need for a real practical example of a “basic” process implementation, which you could use to build your own.. The authors of the articles seem to find this self-evident. An obvious option would be to adopt the experience of large companies or hire a person with such experience, but this approach might be ineffective. Since a large company’s infrastructure is most likely tailored to tasks much more complicated than your current needs and requires a lot of resources and knowledge to implement it.
Eventually, I went through a lot of related materials, got acquainted with various infrastructure tools and compared with my own experience. During the implementation process, I hit all the pitfalls, that were hardly covered in the official documentation, but I had to overcome them for the sake of “best practices”. It also took time to adjust the department to working in a new way.
And even though I got this experience already a year ago, Google shows that the guide, that I was looking for once, has not yet appeared.
So, let's get started.
You will need:
- Some computing capacities at your disposal. Maybe your own server or a cloud infrastructure;
- Understanding of your application: how it works, how it is deployed at this point;
- Basic knowledge of networks, git, Linux, Docker, GitLab, Traefik.
Typical development process
Mandatory components
1. Working with the classic model in git
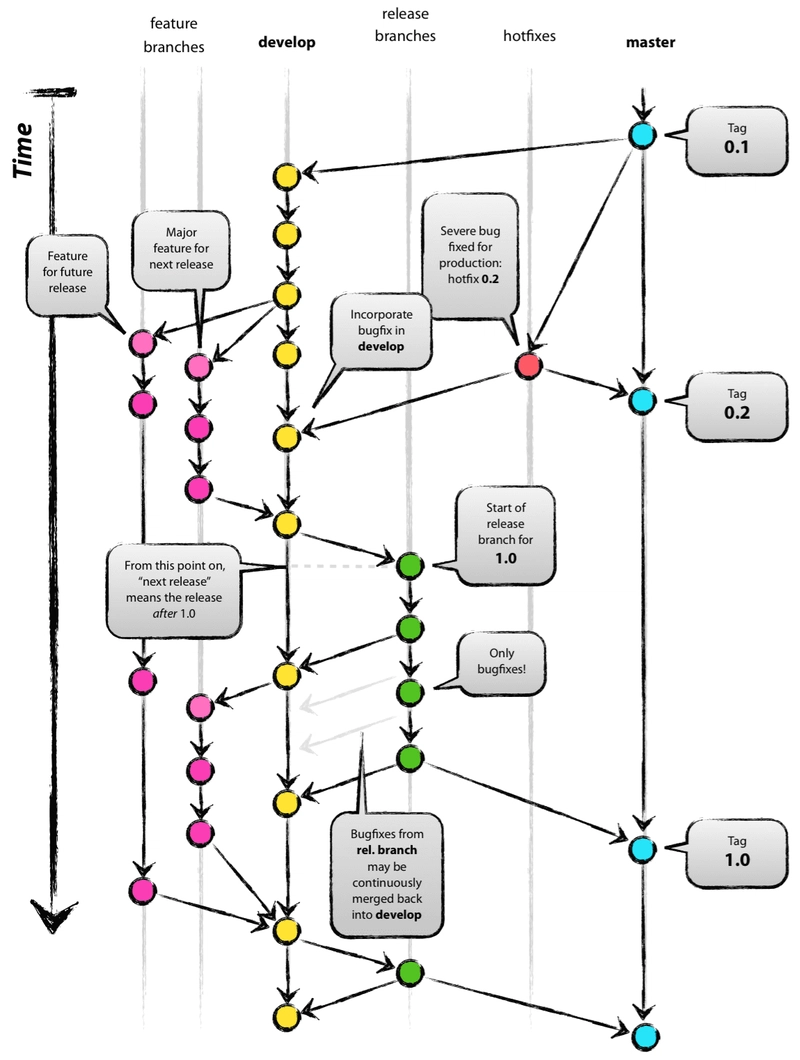
A successful Git branching model by Vincent Driessen
The required minimum is to have the following branches: master, dev and feature.
Feature
Each feature branch is created for working on an individual feature / bugfix, it branches off from the dev branch. They are deleted after the changes are merged into dev.
Dev
In dev, the final co-debugging and testing of all new changes takes place, after which the release is deployed to master.
Master
The release to the production server is deployed from this branch. Also, if you need to apply urgent fixes, hotfix branches are branched off master, then merged back into it and deleted. Master and dev are protected from direct pushes, they are constant branches.
2. Collaboration in the task tracker. Keeping records of all taken decisions

It’s a very important thing. When switching between several feature branches, programmers lose context literally the following day. Creating a low-priority task like “check what's wrong with xxx” isn't enough to remember what this is about. All comments must be recorded in the Merge Request discussions of the thread. It is necessary to maintain the project wiki to speed up the adaptation of new team members and approve taken decisions.
You should always remember that if something is not written down, it does not exist.
An extreme degree of record-keeping is GitLab’s experience, which was a company without an office even before ~~ it has become too mainstream~~ the pandemic.
3. Infrastructure automation for testing and releases
It's simple — the faster you can bring your solutions into production, the more reliable they are and the more competitive edge you have. One might often come across articles where the number of releases per month/week/day is measured.
I believe this shaped DevOps and was the catalyst for the development of all modern IT giants. First, they automated the process of testing and rolling out their monolith. But the problem of waiting and impossibility to deploy an environment for development locally came up. The solution was to introduce a microservice architecture, which brought new challenges. Somewhere at this point, containerizing (LXC) appeared, then came Docker, orchestrators, and it spiralled from that...
Functional roles
In teamwork you need to understand who is responsible for what. Please note that these are functional roles, not positions. Which means one person may take on several functional roles. I am sure that in every project these functions are fulfilled to some extent, even if the team is not aware of it. I’m sharing my vision, because many articles are written as if everyone was born with the understanding of who is who.
Project Manager
This team member communicates with key customer representatives, the senior management, determines key indicators, maintains document flow, solves all financial and human resources issues, promotes the product — either without any assistance or by interacting with other company departments. This person is responsible for the business result, puts pressure on the product owner.
Product Owner
The person with this role has the general vision of the product and knows what it should become, what it brings to the client. He is the maintainer of the product backlog (list of tasks), prioritize tasks, know about all the product functions, including the technical side to a certain extent. Must have development experience. This is the person who should say that “the team needs more people” and protect the team from the management pressure.
Analyst / Technical Writer
This team member is always close to the end user of the product, studies the customer's business processes, collects feedback after the implementation of each feature. Analyst / Technical Writer can be called “the product owner’s information provider”, they help to form the technical requirements. They must also know about all the product functions. This person participates in client training and writing documentation for the customer.
Designer UI/UX
The designer is responsible for making the product user-friendly. It’s a critical element of success (unless, of course, you are Microsoft)
Architect
This team member probably works on more than one project. Architect is the most experienced developer in the company. Architect consult the team lead.
Team Lead
An experienced developer who consults the product owner, evaluates the complexity of tasks, distributes them between developers, and handles their further decomposition and technical elaboration. Conducts the final acceptance of finished works.
Developer
This person writes and documents the code; performs code reviews of colleagues.
Developers specialize in their areas: backend, frontend, mobile development, etc., depending on the project.
Tester (QA / QC)
Quality Control (QC) tests the product. Both manually and by coding. Quality Assurance (QA) tester also takes part in the development of the project architecture and infrastructure to ensure that the focus on a high-quality result is embedded in the production process (The Toyota Way — the principle of embedding quality). For example, test exactly the docker image that will be rolled out to production, instead of rebuilding it after the tests.
System Administrator (DevOps)
Like an architect, team member probably works on several projects. They create infrastructure at the start of a project, make changes as it develops.
Information Security
There are many varieties of IS specialists for different software development stages. But all they must ensure that data, managed by your application, is confidential, holistic and available.
Development process

Workflow stages
- Any task begins with a need for some kind of improvement (feature) or a bug report that is sent to the product owner. It is recorded in the tracker.
- The product owner on their own or with the help of an analyst finds out all the details. Everything is written into the task. An initial estimation of work time is carried out. Priorities are set, and the task is probably added to the project management schedule.
- When it’s the time for implementation, the task is decomposed (divided into subtasks) together with the team lead, the performers are determined, together they walk through the task, and implementation descriptions sufficient for the performers are recorded. If you need clarifications on the task, talk to the product owner.
-
A feature branch is created from dev, and the code is written. If the task is large and consists of many subtasks, then the main feature-branch is selected, into which the subtask branches are merged. Tests are written if such a decision was made for this task.
Note: In order to minimize conflicts when merging branches, it is necessary that your application architecture maintains minimal module coupling. Also, you shouldn’t start working on a task, if its implementation falls on the same piece of code that had been changed in another task, but a merge-request for it hasn’t been accepted yet.
A merge-request to the dev-branch is created, a feature-branch is built, tested and deployed.
Other developers review the code, manual testing is performed. If there are any defects, auto-tests are run again, the branch is deployed and re-checked.
The team lead does the final check and takes the finished feature branch to dev.
When it’s the time for the next release, a merge-request is created from the dev-branch with all the latest changes to master and the same actions as in points 5, 6 are performed.
Just like in point 7, the product owner may be engaged.
It is very useful to let users know what changes have been introduced (creating a changelog) and also to update the product help. Update the documentation and accept changes to master.
The changes are deployed to production automatically or manually.
The application is monitored. It’s not covered in this article.
Infrastructure
When selecting tools, the following criteria were used:
- production-ready,
- large community,
- not too steep learning curve to other tools,
- as few of them as possible (each having a large feature set).
Eventually, the following technologies were chosen: Traefik, GitLab and Docker.
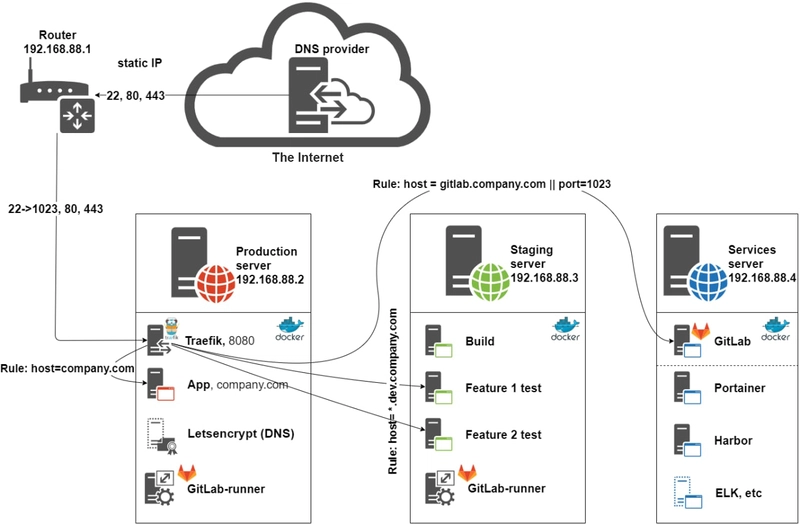
Three servers are used: [Production], [Staging] and [Services]. They can be either physical or virtual machines, their number can be higher or lower, or everything can be stored in the cloud. Here the most efficient configuration is given in terms of reliability/price ratio. The main thing is that [Production] should be separate and the most reliable one. GitLab, as well as minor services (monitoring, docker registry: Portainer, ELK, Harbor, etc.), which we will call Services, are installed on the [Services] server. Their configuration is not covered in this example. All applications run in Docker containers. It is better to install GitLab separately, but it depends on the available capacities.
Traefik collects the information about running environments with unique dynamic DNS for .dev.company.ru by connecting to the *[Staging]** docker over TCP and providing access to them. It also automatically obtains SSL certificates for the application on [Production]. Wildcard (WC) certificate .dev.company.ru is obtained using a separate container *letsencrypt-dns if Traefik does not support your DNS provider. Traefik uses this or a self-obtained certificate, truncates SSL from clients and redirects http requests to the appropriate services by domain names. It runs on [Production] along with the main application App.
GitLab runs commands on [Services] using GitLab-runners, installed on other VMs. By Merge Request (MR) to dev and master branches manages the running docker images on [Staging] and [Production] according to project’s .gitlab-ci.yml files.
Building, testing and staging take place on [Staging].
In this solution, GitLab also acts as a Docker Registry, where the builded application images are stored.
GitLab, Traefik and Gitlab-runners also run in docker containers, which makes it easy to update and migrate the infrastructure.
Here is a link to a github repository with a step-by-step description of the process of creating this infrastructure. Not to make this longread even longer, I ask you to please read it there:
https://github.com/Akkarine/demo_cicd
Warning
- This infrastructure solution is rather a launch pad for understanding the basic principles; load tests has not been performed. A lot depends on the hardware and the application architecture. For heavy loads, increased reliability and work in the cloud, it is recommended to consider the Enterprise versions of Traefik and GitLab and get experts’ advice.
- The repository contains parts of the configuration that you will obviously need to customize. For example, time zone, postal addresses, domains, etc.
- Since the work was carried out a year ago, Traefik and GitLab have significantly developed over the time, and many things can already be optimized. For example, Traefik now supports DNS Yandex (not without my modest contribution) and no longer needs an intermediate service. And GitLab has more flexible configuration options. For example, rules.
- Also pay attention to the section “What can be improved right away”.
Case for web development:
https://github.com/Akkarine/demo_cicd_project
The example is provided for a small web application to give an understanding of the basic principles, as it assumes:
- Application unavailability during updates. To organize the roll-out without downtime, you will need support from the application code (backend API versioning, staged database migrations), more complex load-balancer settings and roll-out algorithm, and ideally, another level of infrastructure — kubernetes. So this is far from the “beginner level”.
- Running database in a docker (affects performance)
- Copying the production database for staging (data confidentiality, problematic with a large database)
- Running commands as root in containers (not the best practice at all)
The most important thing in the repository is the .gitlab-ci.yml file. Let's consider the pipeline stage and tasks within it according to steps in the workflow:
-
base-img-rebuild
- rebuild-base-backend: The building process is divided into two stages to make it faster. On the current — the first one, a base image is built, which will be launched only when the files with the description of dependencies are changed. On the second (build stage), the application is built.
-
rebuild-dev-db
- rebuild-dev-db: In this task, a common database image is prepared for test branches with backup of the database deployed directly inside the image.
-
build
- rebuild-proxy-img: Since the image of the nginx proxy server will be updated extremely rarely, this image can be right away created with a ‘latest’ tag
- build-backend: The application is built with the current changes and for now is tagged with the issue number (unique to the entire GitLab)
-
test
- testing: Running automated tests
-
deploy-review
- deploy_review: A test server is deployed, it is almost identical to production, only with server configurations less aggressive to resources.
skip_review: It is used to skip test server creation if it’s not needed at this stage of development.
-
review
- approve-dev: It is activated manually. When the Merge-request goes to dev (i.e. the current branch is feature), then you don't have to push. This task is just for a green checkmark on the pipeline.
- approve-staging: It is activated manually. When the Merge-request goes to master (i.e. the current branch is hotfix or dev and the release is in progress), then the image that was tested on the build stage is tagged ‘latest’ and replaces the previous version in the repository. To ensure it is not erased by the next latest version, it is also uploaded with the tag ‘the task number’.
- reject: It is activated manually. It just shows the red color on the pipeline. Thus it will be clear from the list of Merge Requests that something is wrong with this branch.
- stop_review: Can be activated both automatically and manually. Stops the raised test server
-
rebuild-approved-db-img
- rebuild-approved-db-img: If the review was successful and the files were updated in the context of creating the database image, then a new image is created with the ‘latest’ tag and uploaded to the repository.
-
deploy-prod
- deploy-production: In production, the database is backed up and the containers are updated to the latest version. If the backup was unsuccessful, the rollout does not happen.
- deploy-production-wo-containers: In case the database is not deployed for backup, this action is skipped.
-
clear: The staging and production servers are cleared of trash
- clean-staging
- clean-prod
-
restore-db
- restore-db: For the first deployment or an extremely unsuccessful update, it restores the database from the backup.
Materials
Traefik
Alternative reverse proxy + SSL on nginx
- https://github.com/jwilder/nginx-proxy
- https://github.com/JrCs/docker-letsencrypt-nginx-proxy-companion
GitLab
GitLab SSL config
- https://docs.gitlab.com/omnibus/settings/ssl.html
- Configuration behind reverse proxy https://docs.gitlab.com/omnibus/settings/nginx.html#supporting-proxied-ssl
GitLab Registry
- https://docs.gitlab.com/ce/administration/container_registry.html#configure-container-registry-under-its-own-domain
- Deleting images: https://docs.gitlab.com/omnibus/maintenance/#container-registry-garbage-collection
Gitlab-runner
- Installation using a docker image: https://docs.gitlab.com/runner/install/docker.html
- Using Docker Executor https://docs.gitlab.com/runner/executors/docker.html
- Using SSH Executor https://docs.gitlab.com/runner/executors/ssh.html
- Runner registration https://docs.gitlab.com/runner/register/index.html#docker
- Creating Docker images with GitLab CI/CD https://docs.gitlab.com/ce/ci/docker/using_docker_build.html
- Creating Docker images inside the Docker without using privileged mode and cashing to registry (useful for working in the cloud) https://docs.gitlab.com/ce/ci/docker/using_kaniko.html
- Will come in handy for creating a configuration file https://docs.gitlab.com/runner/configuration/advanced-configuration.html
- CLI https://docs.gitlab.com/runner/commands/README.html
Docker
- Post-installation steps https://docs.docker.com/install/linux/linux-postinstall/
- docker-compose file https://docs.docker.com/compose/reference/overview/
- Useful for debugging https://docs.docker.com/compose/reference/config/
- Connecting to a remote Docker with certificates (TCP + TLS): https://docs.docker.com/engine/security/https/
Other useful links
- Analyzing docker images: https://github.com/wagoodman/dive
Command for analyzing docker images (the utility runs in docker)
sudo docker run --rm -it -v /var/run/docker.sock:/var/run/docker.sock wagoodman/dive:latest gitlab/gitlab-runner:latest
- Server configuration generator for working with SSL: https://ssl-config.mozilla.org/#server=traefik&server-version=2.1&config=intermediate

Top comments (10)
Now this is what I call quality content.
"#pleasestoprecommendinggitflow"
georgestocker.com/2020/03/04/pleas...
Hello! I'm an author of original article. Thanks for your comment.
As I said I've seen many theories. You provided interesting link but it also only theory:
But I want to give some basic launch pad for newbies. Hope after this they will be able to build their own workflow.
That's a basic launchpad for newbies: guides.github.com/introduction/flow/
Newbies in my context are new IT companies or who thinks about organizing a teamwork on their project first time.
Your link for people, who don't even know about git.
What a sad state of affairs. More fancy looking doc should be praised.
githubflow.github.io/ here is a more serious looking doc. Same thing though but maybe that will convince you or whoever read that far in the comments.
Now that's a different story and a good source. And at the very beginning of it:
And:
Before newbies will have to resolve issues with git-flow I expect, they will have enough experience.
It is all about to see a whole process before you can do something with it.
So, for beginners case, you have not convinced me, sorry.
Oh gosh don't be sorry please, no harm.
We haven't convince each other, it's all fine.
Nice one
Great job! This is a very useful article for startups. I wish I had come across such information some time ago, when I started projects with a team of enthusiasts.