Also published on Medium and Boostlog.
This is we failed at web scraping and how we conquered it - Building Link Statuserizerer
Idea
Last week we held an intra-office hackathon as part of our monthly Team Day at GAPLabs. We were to build something that can help the company or its employees. Most of the ideas my team came up with were either too difficult to complete on half a day of coding or the idea already existed. After much brainstorming, we settled on an app that would be a directory for all the internal projects created for the company, so that they may never get lost again.
But I was not satisfied. Not by a long shot. It just didn’t have enough impact for me. I knew we could do better but there was no more time to think of another idea. I was about to give up.
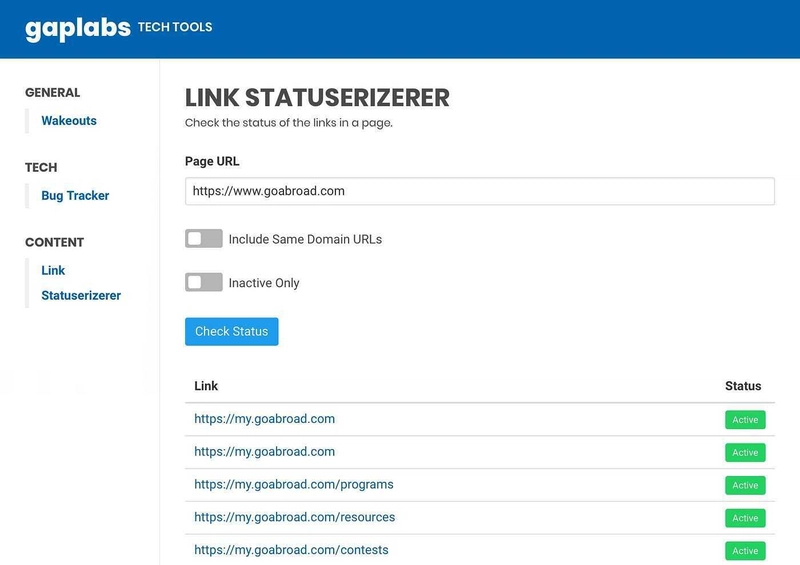
But it occurred to me that if I can’t think of anything, maybe other people can. So I decided to ask around the office to figure out what tools they needed and got an idea — apparently the content team needed a tool for checking the status of links in a webpage because the license for the tool they were using was going to expire soon. I thought that this was a great idea and it was easy enough so we set out to work. We just have to do some elementary scraping it right?
We only had to make an HTTP request from the browser to the given URL to get its HTML content and the rest is history, right?
Failing
Alas, fate is not so kind so as to let us complete our task that easily.
It wouldn’t be much of a story either.
I usually do web scraping in Python. I guess I was naïve and got spoiled by how easy it was. Just combo the requests and BeautifulSoup libs and you’re good to go.
Apparently, you can’t just “make an HTTP request from the browser to the given URL its HTML content” with JavaScript. Using the fetch API or plain AJAX throws a non-descriptive error and upon further research, we found out that you can’t make requests like that because that would be a security issue. You know, those cross-origin/domain request issues.
That threw a wrench to our plans. So, what now?
Solution
Instead of using a browser, I checked if a server could make the request successfully. I built an Express server and used Axios to make the requests. It worked! The client web app would now make a request to the Express server with the URL as a query parameter. The Express server also needed an Access-Control-Allow-Origin header in order to allow the client web app to send requests to it. You know, those cross-origin/domain request issues.
Making the requests gets the HTML content from the URL. Next step is to get all the links from the the HTML. This is the scraping part. Before jumping into building a regular expression for this, I searched for a library that could do this for me. I found Cheerio to be somewhat suitable for the task. Cheerio is like jQuery but for servers. It kinda creeps me out that I’m using something similar to jQuery but I did not have much choice given the circumstances. A quick $(‘a’) did the trick. After getting all the links, I made asynchronous requests to all of them, checking if their response codes are 400 and above, which are error codes.
The resulting information is then sent to the client web app and then displayed. Aaaand we’re done!
Architecture

Improvements
The processing takes a while because it checks all the links at once. Even though it is done asynchronously, that is still a lot. A better approach would be to return all the links to the client web app and send each of the links asynchronously to the Express server so that the user can see all of the links immediately and then web client is updated each time a link status check is completed. This way the user does not keep watching a blank white screen while the links are being checked.
Hackathons are all about ideas and hacking around when things go wrong — which is bound to happen all the time.
I hope you learned something from this! We most certainly did! ☺️

Top comments (5)
Yep, CORS is a b*tch, but it has good reason for it: imagine an API, that has
Access-Control-Allow-Origin: *header and doesn't have any rate limiting. I think you should consider this as a factor also, limit your request speed if needed.More importantly, always respect
robots.txt! Including what urls not allowed to scan and what is the minimum time between requests (Crawl-delay). For example IMDB use this settings in theirrobots.txt:An API/Website with
*wildcard in their CORS header and without rate limiting is a free fountain for everybody to mirror their entire database and use for their site (and their resources) in a client side application. Imagine the plus load on the servers that the lots of new users generating on those copycat sites.That's why some services offer database dumps. You have to deal with the database hosting and parsing/updating the fields in your own stack. They allowing to GET the images, videos from the origin servers, but nothing much more.
That makes sense.
Please have a look at my npm package mu.js.
HAHAHA well, we did fail at first but we did succeed in the end. :)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.