
Once upon a time, building AI applications required deep experience with traditional technologies and some Machine Learning expertise. While that was the norm, developers had to configure models to their needs, provide GPUs, and manually optimize performance, which required a lot of effort and costs.
While that approach seemed difficult, the AWS team built Amazon Bedrock, a tool that allows developers to easily create their AI applications through an API or the AWS Management Console using its embedded foundation models. Amazon Bedrock enables developers to build generative AI applications without the stress of directly managing the underlying stack.

In this article, you’ll learn everything about Amazon Bedrock, the prerequisites of using Amazon Bedrock, how to get started with Amazon Bedrock, best practices for working with Amazon Bedrock, and even the core concepts of Amazon Bedrock. Other than that, you’ll also see some code samples of how you can work with AWS’s Bedrock API. So, this article will serve as an A-Z guide for people who are interested in using Bedrock to build their generative AI applications.
Please, support Microtica 😅 🙏
Before moving on, I’d love it if you could support our work at Microtica joining our community! ⭐️
⭐️ Join Microtica’s Discord Community ⭐️

What is Amazon Bedrock?
Amazon Bedrock is a service that lets DevOps engineers and teams build gen AI applications. Instead of building or fine-tuning models manually, Amazon Bedrock uses foundational models from AI infrastructure providers to provide a ready-made API for developers to use easily. This approach removes the complexity that comes with building generative applications and working with underlying stacks.
Benefits of Amazon Bedrock
Before getting in hands with Amazon Bedrock, I just thought it would be nice to share some benefits of Amazon Bedrock and include examples of how these benefits have a positive impact on your development workflow.
-
Quicker Development: Compared to working manually, where you always have to work with models and fine-tune them, AWS lets you work with a single API. With this approach, you don’t have much to focus on. This approach saves a lot of time as it requires less effort than directly working with models.
- Example: My colleague made an AI Assistant using Amazon Bedrock's text generation models without having to handle any ML models directly, which saved him time. He found this method quicker because he could add AI features in just a few days with an API call instead of spending months or weeks.
-
Scalability: Amazon Bedrock is built on AWS’s Cloud Infrastructure and uses models from various companies, including AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, and Stability AI. This enables teams to scale their applications easily and under heavy workloads, Bedrock ensures excellent application performance without requiring manual intervention.
- Example: An e-commerce service using Amazon Bedrock for product recommendations can easily scale resources during shopping seasons without compromising performance or experiencing downtime.
-
Integration with AWS Ecosystem: As Amazon Bedrock is an AWS product, it seamlessly integrates with Amazon SageMaker, Lambda, and S3 for building, deploying, and managing applications.
- Example: A bank using Amazon Bedrock for fraud detection can create automated workflows. For instance, AWS Lambda can identify suspicious transactions, save the reports in S3, and use SageMaker to check patterns.
-
Cost-Effectiveness: Amazon Bedrock has flexible pricing, so you only pay for what you use. Instead of spending a lot on expensive servers and models, you can use any of Bedrock’s models that you think will help save costs while still getting powerful AI features. You can take a look at this page for Amazon Bedrock's pricing models.
- Example: One of my colleagues automated blog posts with Amazon Bedrock and only paid for the API requests she used, saving money on monitoring and fine-tuning AI models.
Getting Started with Amazon Bedrock 🚀
Now, it’s time to prepare to get our hands dirty. In this section, we will look into doing the real work and the things you should have before getting started. Even though Amazon Bedrock can be used to accomplish many tasks, this article is focused only on building generative AI applications easily with the AWS Management Console.
Prerequisites For Using Amazon Bedrock
Before getting started with Amazon Bedrock, here are some things you need to have ready:
- Basic Python Knowledge.
- An AWS Account: This is primary: to get started, you need to create an AWS account.
-
AWS Management Console: You need the console to interact with models if you don’t want to write code. Alternatively, you can use:
- AWS CLI: You can use the CLI to create AWS CLI profiles using the API. For instructions on how to use this option, refer to this documentation. This option requires some basic Python knowledge.
- IAM Permissions: You also need to assign the required IAM roles needed for Bedrock.

In this article, we will be using the AWS Management Console option for operations. You can use the CLI option to go a bit hands-on.
Basic AI/ML Concepts
Even though Amazon Bedrock helps with removing the complexities that come with building AI applications, a basic understanding of AI and ML is helpful because, even when using Amazon Bedrock, there are things you might encounter, such as:
- Foundational Models (FMs): These are the pre-built AI models that Amazon Bedrock provides for operations in generative applications. You might wonder if AWS owns the entire model, but some are from different companies.
- Prompt Engineering: This is the process of creating and improving input prompts to help AI models produce accurate and great responses. Good prompt engineering improves the model's understanding and ensures it aligns with the output.
- Model fine-tuning: With Amazon Bedrock, it’s possible to fine-tune models to your needs. You can always configure models to fit what you want; the approach for doing this is different from the manual approach.
Core Concepts of Amazon Bedrock
Now, let’s take a look at some key concepts of Amazon Bedrock - by having a glance at them, you’ll have a deeper understanding of how Amazon Bedrock works and how to get the best out of it
Understanding Foundation Models
Let’s take a look at some foundation models that Amazon Bedrock uses and things to consider before using them.
To find the list of models you could work with, their capabilities, and their availability in your region, refer to this guide. In that guide, you’ll see everything about the models and the types of outputs they generate—for example, image, text, or code.
Here are some things you should consider before using any of the models:
- Use Case: You should know if the model aligns with your application’s needs. For example, if you’re building a chatbot that generates text for responses, you need to work with one of the models that support text for their outputs.
- Performance vs. Cost: Now, this is where the saying "quality over quantity" really matters. You need to think about two things: performance and cost. Some models work quickly but are usually expensive. If you want a model that fits your budget, you might have to find a balance between how well it performs and how much it costs.
- Customization: Amazon Bedrock lets you adjust models for some uses. Depending on your needs, you might want a model that can be customized to fit your project.
Amazon Bedrock API
Now, let's explore Amazon Bedrock's API and SDK and learn how to use them. First, we'll have a look at the API and learn how to work with the foundational models.
Overview
Apart from interacting with the service, Amazon Bedrock API allows you to do the following:
- Work with the foundation models to generate text, create images, generate code
- Adjust the model’s behaviour with settings you can change.
- Get information about the model, including its ARN and ID.
Amazon Bedrock APIs use AWS's normal authentication and authorization methods, and that requires IAM roles and permissions for security.
Authentication & Access Control
To use the Bedrock API, you need to install the latest version of AWS CLI and log in with AWS IAM credentials. Make sure your IAM user or role has the required permissions, too.:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MarketplaceBedrock",
"Effect": "Allow",
"Action": [
"aws-marketplace:ViewSubscriptions",
"aws-marketplace:Unsubscribe",
"aws-marketplace:Subscribe"
],
"Resource": "*"
}
]
}
This policy allows you to use the API to run models. To follow up with working with Amazon Bedrock’s APIs, you can refer to and read these guides:
- Amazon Bedrock API Reference: In this documentation, you’ll find the service endpoints you’ll likely work with.
- Getting Started With Amazon Bedrock API: This documentation will walk you through everything you need to know about Amazon Bedrock’s API—from its installation requirements to the How-tos; it’s a more detailed guide for setup.
AWS SDK Integration
AWS provides SDKs to integrate with your favourite programming languages, such as Python, Java, Go, JavaScript, Rust, etc. Now, let’s have a look at some examples of how they work with different languages.
- Python (Boto3):
import logging
import json
import boto3
from botocore.exceptions import ClientError
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def list_foundation_models(bedrock_client):
try:
response = bedrock_client.list_foundation_models()
models = response["modelSummaries"]
logger.info("Got %s foundation models.", len(models))
return models
except ClientError:
logger.error("Couldn't list foundation models.")
raise
def main():
bedrock_client = boto3.client(service_name="bedrock")
fm_models = list_foundation_models(bedrock_client)
for model in fm_models:
print(f"Model: {model['modelName']}")
print(json.dumps(model, indent=2))
print("---------------------------\n")
logger.info("Done.")
if __name__ == "__main__":
main()
That’s a clear example of how to list the available Amazon Bedrock models with Python (Boto3). To learn more about how to the Python SDK works, read this guide.
- JavaScript Example (AWS SDK for JavaScript v3):
import { fileURLToPath } from "node:url";
import {
BedrockClient,
ListFoundationModelsCommand,
} from "@aws-sdk/client-bedrock";
const REGION = "us-east-1";
const client = new BedrockClient({ region: REGION });
export const main = async () => {
const command = new ListFoundationModelsCommand({});
const response = await client.send(command);
const models = response.modelSummaries;
console.log("Listing the available Bedrock foundation models:");
for (const model of models) {
console.log("=".repeat(42));
console.log(` Model: ${model.modelId}`);
console.log("-".repeat(42));
console.log(` Name: ${model.modelName}`);
console.log(` Provider: ${model.providerName}`);
console.log(` Model ARN: ${model.modelArn}`);
console.log(` Input modalities: ${model.inputModalities}`);
console.log(` Output modalities: ${model.outputModalities}`);
console.log(` Supported customizations: ${model.customizationsSupported}`);
console.log(` Supported inference types: ${model.inferenceTypesSupported}`);
console.log(` Lifecycle status: ${model.modelLifecycle.status}`);
console.log(`${"=".repeat(42)}\n`);
}
const active = models.filter(
(m) => m.modelLifecycle.status === "ACTIVE",
).length;
const legacy = models.filter(
(m) => m.modelLifecycle.status === "LEGACY",
).length;
console.log(
`There are ${active} active and ${legacy} legacy foundation models in ${REGION}.`,
);
return response;
};
if (process.argv[1] === fileURLToPath(import.meta.url)) {
await main();
}
The code snippet above also shows the listing of the available Bedrock foundation models. To learn more about how to use the JavaScript SDK, read this guide.
There are code samples that showcase how to integrate Bedrock SDKs into your favorite programming languages. You can find them in this guide.
Understanding Amazon Bedrock API Responses
Now, lets have a look at the main API operations that Amazon Bedrock provides for model prediction:
- InvokeModel – Sends one prompt and gets a response.
- Converse – Allows ongoing conversations by including previous messages.
Additionally, Amazon Bedrock supports streaming responses with InvokeModelWithResponseStream and ConverseStream.
To see the type of responses you’ll get when you submit a single prompt with InvokeModel and Converse, check the following guides:
-
Converse API: This guide showcases how to use Amazon Bedrock using the Converse API. It also includes how you can make a request with an Amazon Bedrock runtime endpoint and examples of the response you’ll get with either
ConverseorConverseStream. -
InvokeModel: This guide explains how to use the
InvokeModeloperation in Amazon Bedrock. It also covers how to send requests to foundation models, set parameters for the best results, and manage responses.
Building A Conversational AI Application With Amazon Bedrock
Now, let's start building our first application in Amazon Bedrock using the AWS Management Console. For this first project, we'll create a conversational AI assistant that works only with text.
Step 1: Get started with Amazon Bedrock in the AWS Management Console
Firstly, sign into the AWS Management Console from the main AWS sign-in URL. When, you’re signed in, you’ll be redirected to the Dashboard. In the dashboard, select the Amazon Bedrock option (search for "Bedrock" in the AWS search bar).
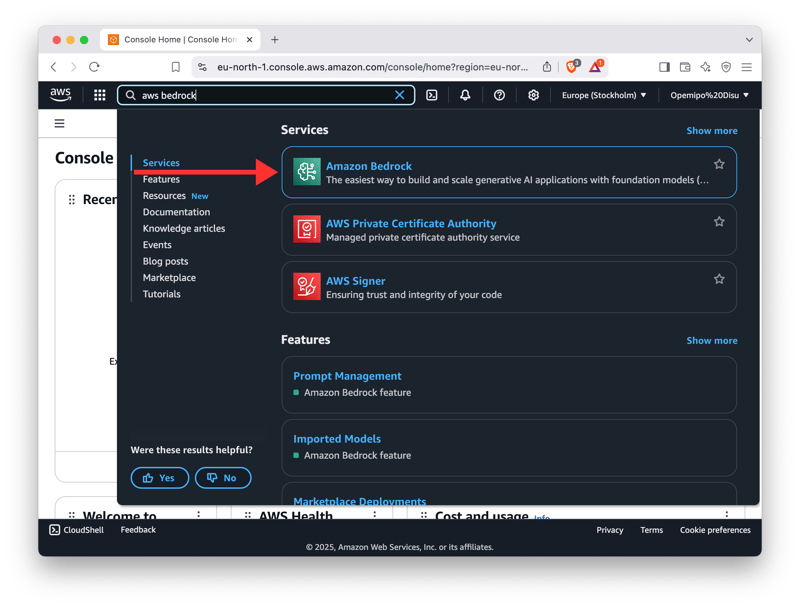
After selecting Amazon Bedrock, head over to the Model Access tab and ensure you have access to any Amazon Titan text generation models by requesting access.
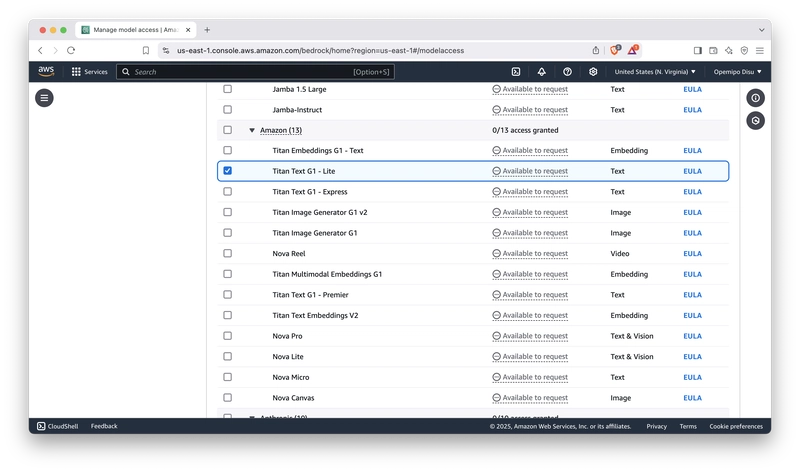
After selecting the model you'd like to work with, hit the Next button. Afterwards, you'll be redirected to a tab where you should submit a request to access the model.
Step 2: Building the Chatbot Using Amazon Titan
Head over to the Playgrounds section in the side navigation and select the Chat / Text section. Enter a prompt in the playground. Click the Run button to generate a response from Titan’s text model.
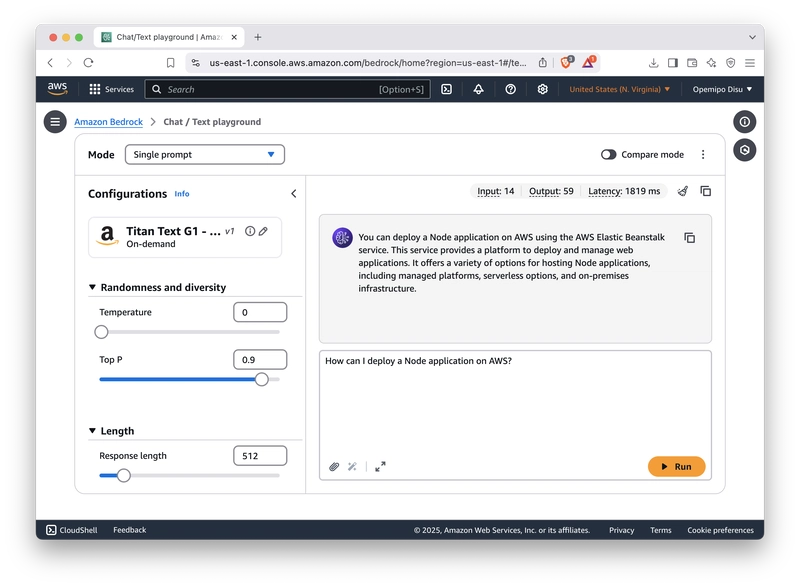
Step 3: Deploy the Chatbot with AWS Lambda
Now, let’s deploy the chatbot with AWS Lambda as a serverless application! First, we need to create an AWS Lambda Function. Here are some steps to follow to create an AWS Lambda Function:
- Navigate to AWS Lambda and Create a Function.
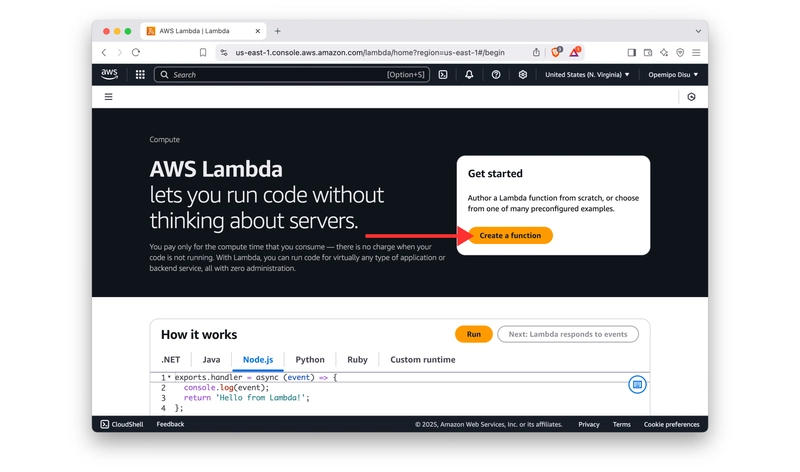
- Select the Author from Scratch tab and make deployment configurations. Note that the runtime should be Python 3.10.
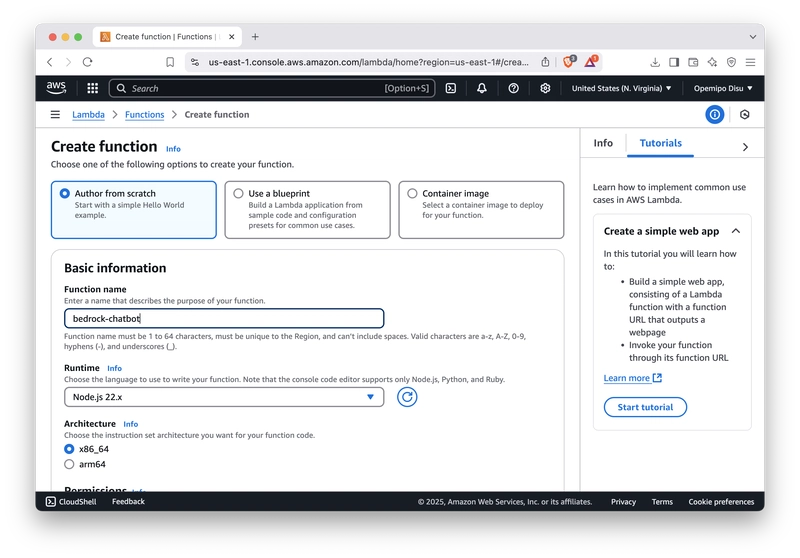
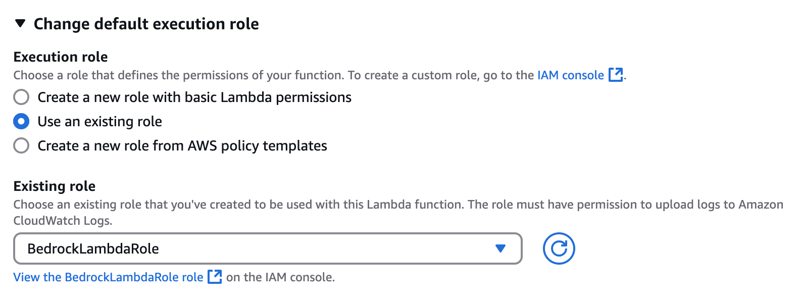
- Create a role with full access to the Bedrock and CloudWatch permissions.
- Create function! 🚀
Add some code to the Lambda function and hit the Deploy button.
import json
import boto3
bedrock = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
user_input = event['queryStringParameters']['message']
response = bedrock.invoke_model(
body=json.dumps({
"prompt": user_input,
"maxTokens": 200
}),
modelId="amazon.titan-text-lite-v1"
)
model_output = json.loads(response['body'].read().decode('utf-8'))
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"response": model_output["completions"][0]["data"]["text"]})
}
Step 4: Deploy the API with API Gateway
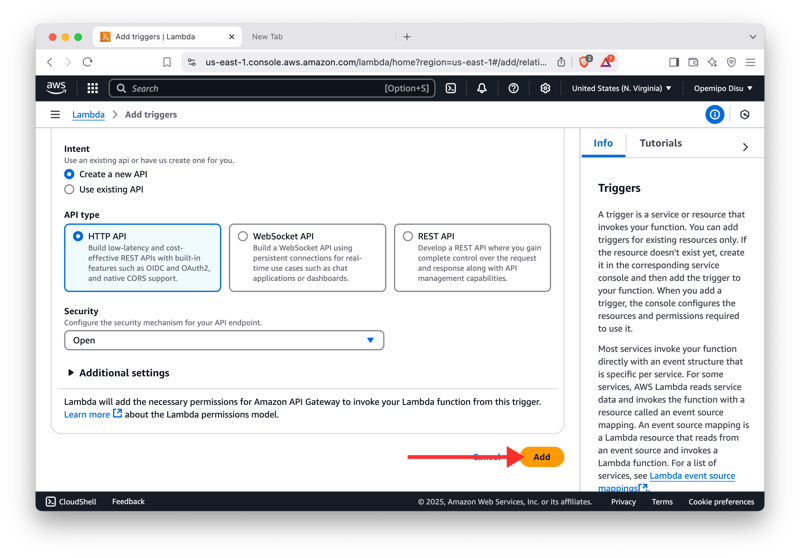
- Under the Function Overview, click the Add Trigger button and select the API gateway option.
- Create HTTP API and configure the security method for your API endpoint.
-
Deploy the API! 🤘
-
Note down your Invoke URL to interact with the chatbot! 🚀
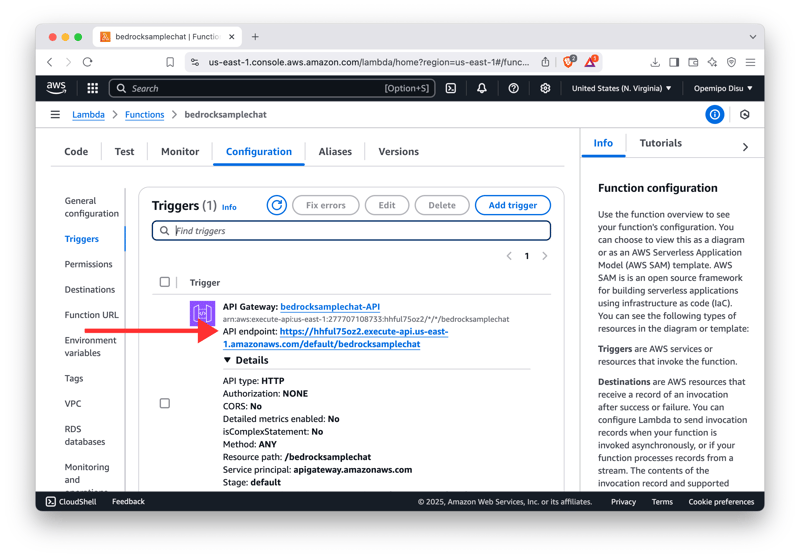
-
Finally, you can interact with your API’s endpoint and build with it. 😎
Building a Code Generation Tool Using Amazon Bedrock and Anthropic Bedrock
Now, let’s build something more fun and technical. In this section, we will be building a code generation tool using Amazon Bedrock and Anthropic Claude’s 2.0 Model (a model that generates code as its form of response). Don’t fret, we’ll still be working with the AWS Management Console but a basic Python knowledge is required for this use case.
Step 1: Navigate to Bedrock and Select the Anthropic Claude 2.0 Model
Just like we did in the chatbot use case, access Amazon Bedrock in the AWS Management Console. Go to the Chat/Text section under the Playground section.
Under the Select Model dropdown, select the Anthropic Claude 2.0 Model. Once done, you can now enter a code-related prompt in the chat.
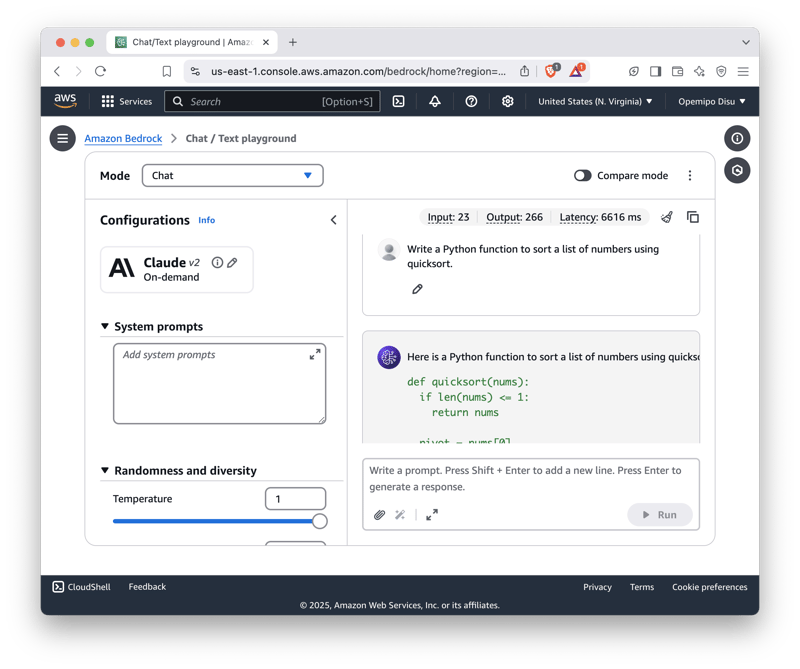
It’s a super great model to work with as it doesn’t just generate code; it also explains what the code does and how it works. It’s a super fast and effective model to work with!
Deploy the Code Generation Use-Case With AWS Lambda
Also just as we did in the first use-case, we will also deploy code generation using AWS Lambda.
- Create a New Lambda Function
Add some Python code to Lambda Function (Runtime: 3.9):
import json
import boto3
bedrock = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
prompt = event['queryStringParameters']['prompt']
response = bedrock.invoke_model(
body=json.dumps({
"prompt": f"{prompt}",
"max_length": 300,
"temperature": 0.7,
"k": 0,
"p": 0.75,
"frequency_penalty": 0,
"presence_penalty": 0
}),
modelId="arn:aws:bedrock::account:model/claude-v2-20221215"
)
output = json.loads(response['body'].read().decode('utf-8'))
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"code": output[0]["generated_text"]})
}
Step 3: Deploy an API for Code Generation
- Go to API Gateway and select the HTTP API option.
- Integrate it with the code generator.
- Deploy the API and get the Invoke URL for interactions.
Best Practices For Working With Amazon Bedrock
When working with Amazon Bedrock you need pay attention to security, cost, and performance. By following these best practices, you can make sure your AI applications are secure, efficient, and cost-effective.
1. Data Security and Privacy
Ideally, you want to keep your data private because AI models often handle sensitive user data, so security is very important in this case. To protect data when using AWS Bedrock, here some practices to follow:
- Use IAM Roles and Policies: Follow the least privilege principle to limit access to Bedrock APIs and data storage. This means only giving people the permissions they need and nothing more.
- Encrypt Data: You use AWS Key Management Service (KMS) to protect sensitive data both when it's stored and when it's being sent.
- Monitor and Audit Access: Enable CloudWatch and AWS Config to keep track of who accesses AI models, data, and logs; and how they’re being accessed.
- Mask Data: Before sending data to Bedrock, remove any personally identifiable information to reduce the risk.
2. Cost Optimization (Managing Bedrock Usage and Expenses) 💸
AWS Bedrock uses a pay-per-use pricing model, so it's important to manage costs well. You get billed based on what you use. Here's how can optimize cost using AWS Bedrock:
- Choose the Right Foundation Model: Different models cost different amounts; select the one that best fits your needs and budget.
- Optimize API Calls: Cut down on unnecessary API requests by using caching and batching when you can.
- Monitor Usage: Use AWS Cost Explorer and AWS Budgets to track your spending and set up alerts for any unexpected cost increases.
- Use Auto Scaling: When using Bedrock with AWS Lambda, adjust the number of requests to reduce unnecessary API calls.
3. Bias and Fairness
AI models can pick up biases based on the data they are trained on, which can cause problems. To make sure things are fair:
- Check Model Responses: Regularly test the model's outputs with prompts to identify any biases or errors.
- Use Diverse Data for Fine-Tuning: When adjusting models, make sure the data includes various groups and viewpoints.
4. Performance Tuning
To enhance response times and overall performance, follow these practices:
-
Tune API Parameters: Adjust settings like
temperatureandmaxTokensto get the best results. - Use an GPU-Optimized Infrastructure: If you are deploying custom models, use AWS Inferentia to boost performance.
- Load Balance Requests: If you have a lot of traffic, use AWS Application Load Balancer to distribute requests more efficiently.
- Reduce Latency: Place applications closer to users with AWS Global Accelerator or AWS edge services.
Conclusion
AWS Bedrock makes it easier to integrate AI by offering scalable foundation models from Amazon and other infrastructures without the stress of training models and managing infrastructure. To get the best results, developers should focus more on security, cost-effectiveness, and performance improvements without working manually.
To keep exploring AWS Bedrock, developers should try out different models, adjust outputs, and connect with other AWS services. Keeping up with Amazon Bedrock’s guides, blogs and other resources will help make the most of Bedrock and encourage new ideas in AI-powered applications.
Before you go… 🥹
Thank you for taking the time to learn about building AI applications with AWS Bedrock. If you found this article helpful, please consider supporting Microtica by creating an account and joining the community. Your support helps us keep improving and offering valuable resources for the developer community!


Top comments (6)
Great breakdown of Amazon Bedrock @coderoflagos! At Microtica, we’re exploring how AI-powered infrastructure can streamline DevOps, and Bedrock is an exciting piece of the puzzle.
This is just the beginning—stay tuned for the next parts of this series:
🔹 Part 2: Retrieval-Augmented Generation (RAG) – Enhancing responses with real-time data.
🔹 Part 3: Embeddings – Improving search and recommendations.
🔹 Part 4: Multi-Agent Systems – Coordinating AI models for complex workflows.
Looking forward to diving deeper into how these concepts shape the future of DevOps and AI-powered cloud automation!
Really comprehensive guide. great article
Thank you very much, Shivay!
👏
Some comments may only be visible to logged-in visitors. Sign in to view all comments.