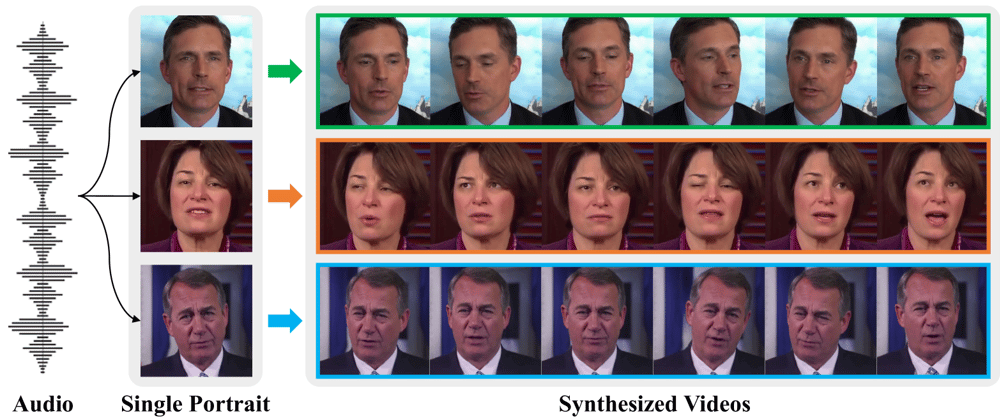
This is a Plain English Papers summary of a research paper called AI Creates Ultra-Realistic Talking Videos from Single Photos with 90% Faster Training. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- New method for creating realistic talking videos from audio using diffusion models
- Introduces implicit keypoint representation for faster, pose-diverse animation
- Achieves state-of-the-art results with 90% training time reduction
- Preserves identity while enabling natural head movement and expressions
- Works with just one reference image of a person
Plain English Explanation
Imagine taking a single photo of someone and making a realistic video of them talking, complete with natural head movements and facial expressions. That's what this research tackles.
Current approaches to [talking video synthesis](https://aimodels.fyi/papers/arxiv/letstalk-lat...?utm_source=devto&utm_medium=referral

Top comments (0)