
Há um tempo, contamos a história de como estamos migrando para o React.js e uma arquitetura orientada a serviços com a ajuda do GraphQL. Agora, queremos contar a história de como a estrutura do nosso servidor GraphQL ajudou a tornar nossa migração muito mais suave.
Tínhamos três coisas em mente quando começamos a projetar nosso servidor GraphQL:
Deve ser fácil alterar a forma dos dados
Atualmente, usamos protocol buffers como um esquema para dados do nosso back-end. No entanto, a maneira como usamos nossos dados mudou ao longo do tempo, mas nossos protobufs não evoluiram. Isso significa que nossos dados nem sempre têm a forma que os clientes precisam.
Deveria ficar claro quais dados são para o cliente
No nosso servidor GraphQL, os dados estão sendo transmitidos e existem em diferentes estágios de "prontidão" para o cliente. Ao invés de misturar os estágios, queríamos tornar explícito os estágios de prontidão, para sabermos exatamente o que os dados significam para o cliente.
Deveria ser fácil adicionar novas fontes de dados
Como estamos migrando para uma arquitetura orientada a serviços, queríamos garantir que fosse fácil adicionar novas fontes de dados ao nosso servidor GraphQL e deixar explícito de onde vêm os dados.
Com isso em mente, criamos uma estrutura de servidor com três funções distintas.
Fetchers (Buscadores), Repositories (Repositórios) e o Schema(Esquema) do GraphQL.

como as camadas de bolo de responsabilidades
Cada camada tem suas próprias responsabilidades e somente interage com a camada acima dela. Vamos falar sobre o que cada camada faz especificamente.
Fetchers

buscar os dados de qualquer número de fontes
Os Fetchers buscam dados em fontes de dados. Os dados que são buscados pelo servidor GraphQL já devem ter passado por quaisquer adições ou alterações na lógica de negócios.
Os Fetchers devem corresponder a um endpoint REST ou preferencialmente a um gRPC. Fetchers requerem um protobuf. Isso significa que todos os dados que estão sendo buscados por um Fetcher devem seguir o esquema definido pelo protobuf.
Repositories
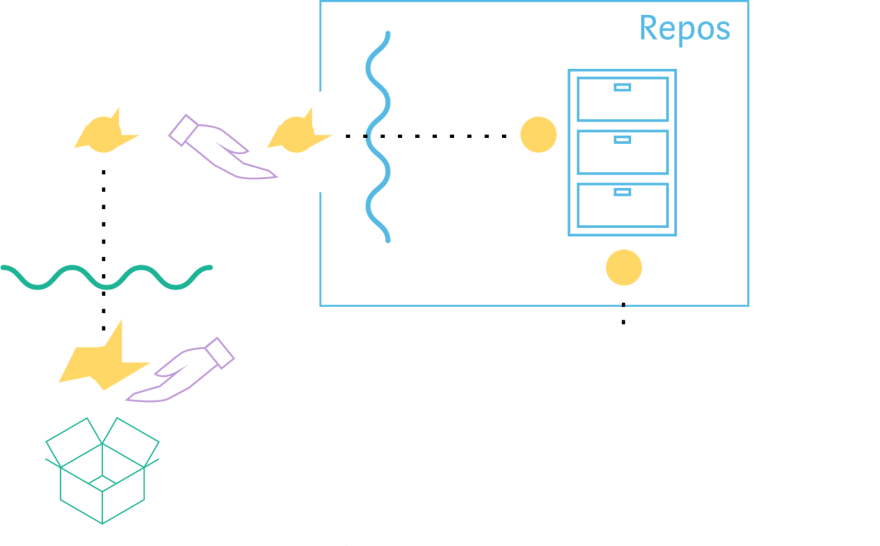
moldar os dados para o que o cliente precisa
Os repositórios são o que os esquemas do GraphQL usarão como representação de dados. O repositório "armazena" os dados limpos e originais de nossas fontes de dados.
Nesta etapa, elevamos (hoist up) e nivelamos (flatten) campos e objetos, movemos dados, etc. Alterando a forma dos dados para ser da forma que o cliente realmente precisa.
Essa etapa é necessária para a mudança de um sistema legado, pois nos dá a liberdade de atualizar o formato dos dados para o cliente sem precisar atualizar ou adicionar endpoints ou seus protobufs correspondentes.
Os repositórios acessam apenas os dados recuperados dos Fetchers e nunca realmente os buscam. Em outras palavras, os repositórios apenas criam a forma dos dados que queremos, mas eles não "sabem" de onde obtemos os dados.
Esquema GraphQL

derivar o esquema para o cliente baseado nos nossos objetos do repositório
O esquema do GraphQL é o formato que nossos dados terão quando forem enviados aos clientes.
O esquema do GraphQL usa apenas dados dos repositórios e nunca acessará os Fetchers diretamente. Isso mantém clara a nossa separação de preocupações.
Além disso, nosso esquema GraphQL é completamente derivado de nossos objetos nos repositórios. O esquema não altera os dados, nem precisa: o repositório já mudou a forma dos dados para ser o que precisamos, portanto, o esquema precisa apenas usá-los e é isso. Dessa forma, não há confusão sobre qual é a forma dos dados ou onde devemos manipular/transformar os dados.
Fluxo de Dados do Servidor GraphQL

como os dados fluem através do nosso servidor GraphQL
A forma dos dados se torna mais parecida com o que o cliente precisa ao passar por cada uma das camadas distintas. É claro de onde vêm os dados em cada etapa e sabemos pelo que cada parte do servidor é responsável.
Esses limites de abstração significam que podemos migrar incrementalmente nosso sistema legado, substituindo diferentes fontes de dados, mas sem reescrever todo o sistema. Isso tornou nosso caminho de migração claro e fácil de seguir e facilita o trabalho em direção à nossa arquitetura orientada a serviços sem alterar tudo de uma vez.
Créditos
- GraphQL Server Design @ Medium, escrito originalmente por Sasha Solomon.

Oldest comments (0)