“ Anxiety arises from not being able to see the whole picture. If you feel anxious but you are not sure why, try putting your things in order.” — Marie Kondo
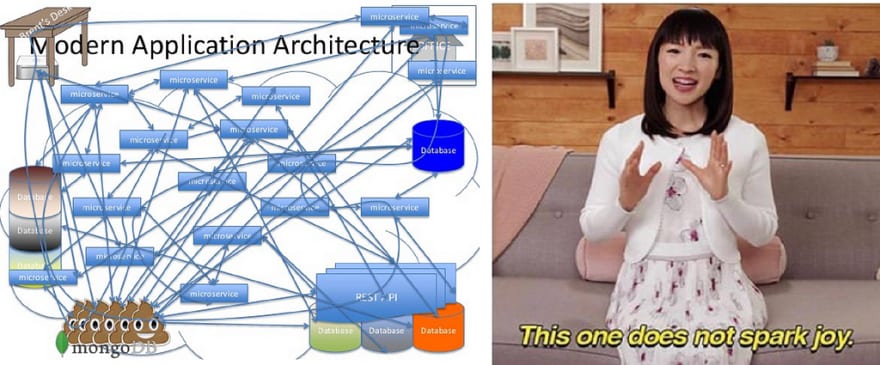
The Clean Architecture 🧹
We have seen what Hexagonal and Onion Architectures are , so the next step is to review what Clean Architecture means.
You can check the first two articles about Hexagonal and Onion architectures here:
What is Clean Architecture?
Architecture pattern promoted by Robert C. Martin (Uncle Bob) in 2012 trying to do one more step in architecture patterns when thinking about isolated, maintainable, testable, scalable, evolutive and well-written code. Following similar principles to Hexagonal and Onion, Uncle Bob presented his architecture together with this diagram:
The main goal of this architecture is the separation of concerns. Uncle Bob mentioned that he didn’t want to create another new and totally different architecture from Hexagonal and Onion. In fact, he did want to integrate all of these great architectures into a single actionable idea.
The key principles of this architecture are:
- It’s really about the Separation of Concerns
- Should be independent of frameworks
- They should be testable
- They should be independent of a UI
- They should be independent of a database
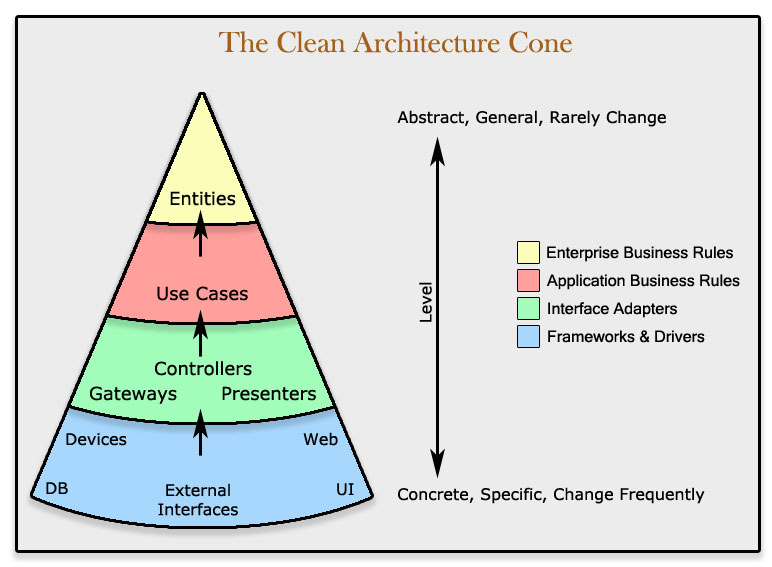
- The Clean Architecture Diagram — Innermost : “Enterprise / Critical Business Rules” ( Entities ) — Next out : “Application business rules” ( Use Cases ) — Next out : “Interface adapters” ( Gateways, Controllers, Presenters ) — Outer : “Frameworks and drivers” ( Devices, Web, UI, External Interfaces, DB )
- The innermost circle is the most general/ highest level
- Inner circles are policies
- Outer circles are mechanisms
- Inner circles cannot depend on outer circles
- Outer circles cannot influence inner circles
So yes, these principles are coming from Hexagonal and Onion architectures as you must be wondering right now.
Also, all of these principles are following the same rule, which is…
The Dependency Rule
The concentric circles represent different areas of software. In general, the further in you go, the higher level the software becomes. The outer circles are mechanisms. The inner circles are policies.
What does that mean?
Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes functions, classes. variables, or any other named software entity.
For example:
Elements located in the Entities circle (the enterprise business rules) should not refer to any elements outside of it (such as application business rules, interface adapters, frameworks, and drivers).
Data formats used in an outer circle should never be used by an inner circle , especially if they are generated by a framework in an outer circle. The Clean Architecture prevents anything in an outer circle to impact the inner circles as shown in the following diagram:

With that in mind already, let’s take a look at the defined circles in the diagram
Circles of the Clean Architecture

Entities
- Entities encapsulate Enterprise-wide business rules.
- An entity can be an object with methods, or it can be a set of data structures and functions. It doesn’t matter so long as the entities could be used by many different applications in the enterprise.
- If you don’t have an enterprise and are just writing a single application, then these entities are the business objects of the application. They encapsulate the most general and high-level rules.
Use Cases
- Use cases are application-specific business rules. Changes should not impact the Entities. Changes should not be impacted by infrastructure such as a database
- The use cases orchestrate the flow of data in/out of the Entities and direct the Entities to use their Critical Business Rules to achieve the use case.
Interface Adapters
- Converts data from data layers to use case or entity layers. Presenters, views, and controllers belong here.
- No code further in (use cases, entities) should have any knowledge of the database.
Frameworks and Drivers
- These are the glue that hooks the various layers up.
- The infrastructure details live here.
- You’re not writing much of this code, i.e. we use SQL Server driver, but we don’t write it.
You can add as many circles as you need. These are schematic. As Uncle Bob mentioned, you can have all the circles/layers you need but following always The Dependency Rule.
So the thing is, we have these circles and we follow The Dependency Rule, but how am I supposed to cross these circles boundaries?
How to cross Circle Boundaries?

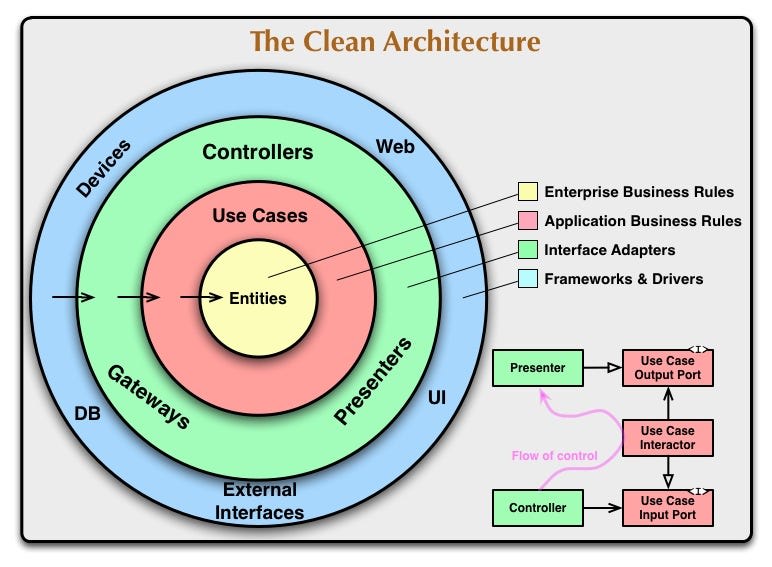
This little screenshot which is part of the original diagram proposed by Uncle Bob shows an example of how the Controllers and Presenters communicate with the Use Case in the next circle/layer.
The flow of control begins at the controller, moves through the use case, and then winds up executing the presenter.
So if you remember well, The Dependency Rule says that no name in an outer circle can be mentioned by an inner circle. And following the Flow of Control, the Use Case needs to call the presenter. And how do we solve that without violating The Dependency Rule? Two ways to handle it
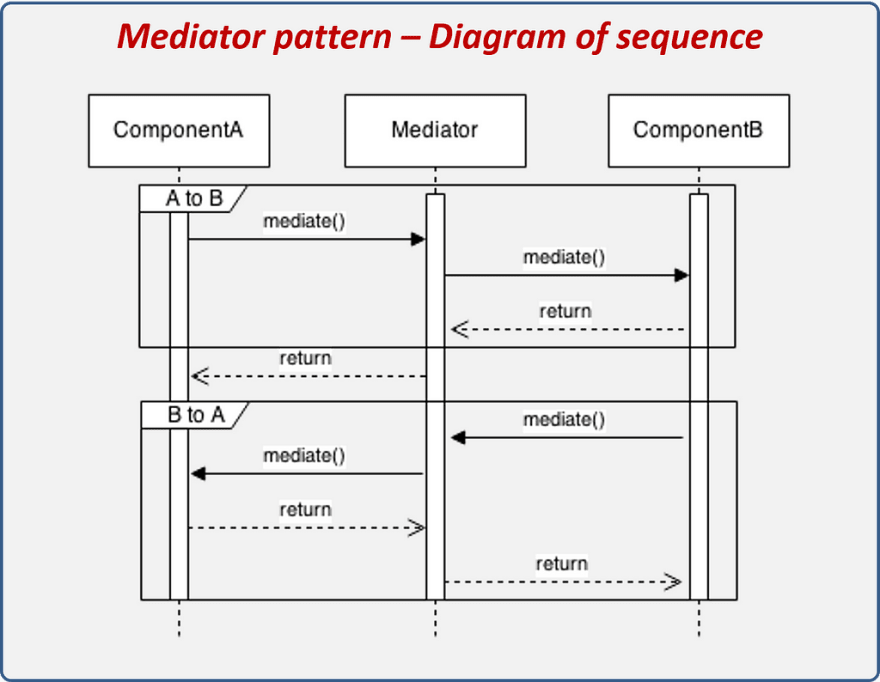
- By using the Dependency Inversion Principle from SOLID principles , where we can define a port (an interface) in the inner circle and implement it in the outer circle.
- By using a great design pattern, Mediator. By using it we can define an object that encapsulates how a set of objects interact.
From my point of view, I prefer to use the Mediator pattern. It has two great benefits that fit really well with the Clean Architecture:
- Objects delegate their interaction to a mediator object instead of interacting with each other directly.
- It should be possible to change the interaction between a set of objects independently.
Presenters
This is another concept we can see in the Flow of Control diagram. The purpose of the presenter is to decouple the use cases from the format of the UI.
They were created to decouple the interactor and the view, so if we use them we can follow the Dependency Rule. If we were returning the response model for the API from the interactor we would be coupling an inner layer to the outer one and we wouldn’t be following the Dependency Rule.
Clean + Hexagonal + Onion Architecture
In the previous example on how to handle communication between Controllers and Use Cases we have seen how the Clean Architecture uses Ports and Adapters pattern. Also remembering if we bring back the key principles of the Onion Architecture we must remember that it is an architecture driven by use cases. So with these Use Cases we are introducing the usage of Onion Architecture principles.
This is double confirming what I mentioned at the beginning of this article. Clean, Hexagonal and Onion architectures are not competing with each other to see which one is cooler or better. All of them try to find a way to separate concerns , and Clean Architecture is focused on combining principles from previous architectures patterns and more principles (like the Stable Dependencies Principe , Stable Abstractions Principle , SOLID, etc )
So, how should I structure my code following all of this?
First of all, this is not a dogma. Benefits are known and it should be a 100% fit for a lot of enterprise projects where business rules change continuously and also we are adding more and more features. But maybe you don’t need to do this for a simple background process service or serverless function. It’s up to you.
But if you definitely want to try it, go for it. Try to put everything in place understanding all the concepts and why you should put something in that circle/layer. And once you’ve tried it, compare your boilerplate with other clean architectures projects out there on GitHub or wherever.
Next chapter will be focused on building an API following this architecture, but right now I would like to share the boilerplate of that API:
This a simple version of the layers and folders structure for an API, sometimes you need to use more architecture patterns, sometimes less. The important thing about this kind of stuff is understanding the rules and growing every day learning new things.
Conclusion
I think that every day more and more developers try to understand how to create quality code following best practices to add more features, to get good code coverage in the tests, to scale it up easily and to maintain the code free of bugs and bad spaghetti code smells.
I have seen dozens of legacy projects almost impossible to maintain, with a lot of bugs and bad practices generating performance issues, never-ending feature developments, and developers burnouts.

Clean Architecture pattern has become more popular in Android development during the past few years and I do really wish that it become more popular in backend architectures or even in the frontend.
Imagine the satisfaction of building something great each day, creating well-engineered solutions for complex business scenarios and making sure that you can add new features without losing huge amounts of time and mental health.
Of course, some developers won’t like this thinking of creating clean code/architectures or they will say something like “meh this looks over-engineered”.
I don’t like to reply to that kind of comment. But Marie Kondo does:
There are two reasons we can’t let go: an attachment to the past or a fear for the future.

Remember to tidy up your code, she is watching you.
The next article in the series will be more practical, building a simple API with .NET Core and accessing real data.
Also, if you enjoyed this article, feel free to share it and to give some love!
If you have read all of this, thank you very much. Feel free to connect with me on Linkedin!
Repositories following the Clean Architecture
- https://github.com/android/architecture-samples/tree/todo-mvp-clean
- https://github.com/ivanpaulovich/clean-architecture-manga
- https://github.com/bufferapp/android-clean-architecture-boilerplate
- https://github.com/eduardomoroni/react-clean-architecture
- https://github.com/jasontaylordev/CleanArchitecture
- https://github.com/ardalis/CleanArchitecture
- https://github.com/carlphilipp/clean-architecture-example
References
- https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
- http://xurxodev.com/por-que-utilizo-clean-architecture-en-mis-proyectos/
- http://jmperezramos.net/desarrollo-en-android/visteme-con-clean-architecture-que-tengo-prisas/
- https://github.com/ivanpaulovich/clean-architecture-manga/wiki/Flow-of-Control
- https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/
- https://groups.google.com/forum/#!topic/clean-code-discussion/Ehwo7yIHUPQ
- https://vrgsoft.net/blog/clean-architecture-for-android/

{kind=link}
{kind=link}
{kind=link}
Top comments (14)
Another observation: in real applications there is often are issues caused by leaking abstractions. For example, in theory replacing one type of repository with another (for example, MySQL with NoSQL) should be easy. But implicit knowledge about particular DB type capabilities often leaks into the repository API and then up to outer layers in the form of ordering/pagination/aggregation/etc. As a consequence switching to another DB is possible but only if this is the same type of DB (i.e. relational, for example).
I agree. The main problem with software architecture (abstractions, patterns, even solid principles) is that most of the times some people understand them in a way that is not complete. They understand the main idea, but they don't know how to do it properly and what they get is a bad abstraction system, with huge coupling.
What you mentioned, I have seen a lot of that in .NET/C#. The most used ORM is Entity Framework, and in several cases, I saw like developers were using the database model as Entities in DDD. And you know, that is the beginning of the chaos where the ORM data model is coupled to the domain and also the Application Services are coupled to the Data Model... and the tech debt increases in every task creating a nice spaguetti code.
Thanks for great overview of these architecture patterns. I'd like to add one more thing to the whole picture: there is another architecture design pattern which fits the picture very well: Functional Core, Imperative Shell. It does not affect general picture drawn by you, just clarifies how to implement inner layers of the architecture in more convenient way.
Definitely I will take a look at this. Thanks, Sergiy! :)
Here are my considerations in regard to such a combination of architectures.
Hi, David. Awesome articles.
I didn't understand where Web APIs belongs to. It is infrastructure because it is framework dependent and it should call an regular API (non REST) on presenter layer?
Thank you
Hello, these are great articles. Many thanks. Can't wait for the next part with that API example. Also, you came in the right time because we are wondering with my colleague how to rebuild and restructure our old codebase. (You know all in one, or village design)
Nice article/Serie.
I've seen some other diagrams of Clean Architecture, where the repositories interfaces are located in the Application Layer and not in the Domain, as it is in your boilerplate. Things like IDbContext aren't more applied to a Database interface?
Cheers!
Hi!
Under my understanding, that approach is not correct. At the end, you need one repository by aggregate root, so if you are defining the interfaces of those repositories outside the Domain layer you are breaking the dependency rule because you are using domain concepts outside the layer which is responsible for those things.
Also Application layer should be for everything regarding application logic, like use cases logic and things like Service pattern, strategy pattern to handle lots of different choices for example, etc.
I think there are a lot of not great implementations of Clean Architecture out there when using Entity Framework.
I will try to go on with my next article from a more on hands POV these next weeks :)
Thanks for reading!!
Hello David, on dev.to you can use the series (Front Matter) keyword for easy navigation from part1 to last article :)
Oh that's great! Sure I will give it a try later on today once office job is done! Thanks Jeff :)
Hi David,
Nice article, for Mediator, does your Mediator as an Interface?
Hi!
To use the Mediator pattern in .NET for example, I have used external Nuget packages like Mediatr or FluentMediator so they provide me the needed contracts or interfaces that I need to implement with the different domain commands and event handlers.
Then you need to register them in your IoC container to get the benefits of DI wherever you need them.
Here you can find some samples: github.com/jbogard/MediatR/tree/ma...
github.com/ivanpaulovich/FluentMed...
I was pretty busy these past months, but I think it is a great topic to cover in an article :)
Thanks for reading!
Hi David, Great serie/article, thank you to share knowledge with us, helps a lot full and brings me many ideas to try implement these approaches.
Regards.
Wellington