
In our last post, we built a synchronous API that validates and analyzes a chess position. We noted that performing a CPU intensive task synchronously in the web server seems like a bad idea.
In this post, we'll turn that synchronous API into an asynchronous one using Postgres.
Analyzing the requests asynchronously
We cannot have our webserver waiting on an analysis. We also, ideally, want to be resilient to a large number of analyses requested at the same time overloading us. This looks like a good time to use a queue.
What is a queue?
The basic idea behind a queue is that instead of analyzing the request immediately, we store it somewhere to be analyzed later, alongside an ID.

The user can use the ID to check if the analysis is ready.

Separately, some other service is running. It will read a chess position from the queue, analyze the position, and store the result somewhere. Services that read from queues and process them are typically called workers.
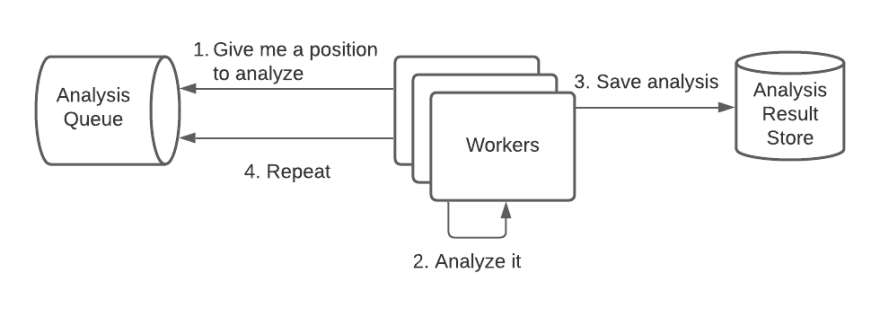
One of the many nice things about this approach is that you can scale up or down the number of workers depending on demand.
How do we make a queue?
There are a lot of ways to actually implement queues. There are products like Kafka or RabbitMQ. There are managed services like AWS SQS or AWS Kinesis. There are libraries like Celery which can be used with Redis or RabbitMQ. For the workers, you can use serverless functions like AWS Lambda or you can have a pool of servers waiting for work.
In our case, we are going to use Postgres as a queue for two main reasons:
- We're going to need a database anyway, so using Postgres as both a queue and a DB means less stuff to manage.
- I personally like debugging queues via SQL. We can get a ton of insight into what's going on in a familiar language.
Using Postgres as a queue
To make a simple queue, we ultimately only need three functions:
-
add_request_to_queue(request)- adds the request the queue, so it can be processed later -
claim_unprocessed_request()- returns any request that hasn't been processed yet. No one else should be able to claim this request until we are done. -
finish_processing_request(request, result)- saves the result of processing a request.
It's important that when a worker claims a request, no other worker can also claim it. Otherwise, we are just wasting time having multiple workers doing the same task.
Imagine we have a table named queue. add_request_to_queue for Postgres can be a simple SQL query:
INSERT INTO queue (id, request, status, created_at)
VALUES (gen_random_uuid(), :request, 'unprocessed', now())
where :request is whatever information the worker needs to process the request. In our case, that's the chess position that we want to analyze and any arguments.
A first pass at claim_unprocessed_request could be a simple select statement:
SELECT id, request FROM queue
WHERE status = 'unprocessed'
ORDER BY created_at
LIMIT 1
However, this doesn't stop anyone else from claiming the same request.
Luckily for us, Postgres has two clauses that can help us out.
SELECT id, request FROM queue
WHERE status = 'unprocessed'
ORDER BY created_at
FOR UPDATE SKIP LOCKED
LIMIT 1
FOR UPDATE locks the row because we are planning to update it. SKIP LOCKED will skip over any rows that are currently locked. With this, no two workers will ever grab the same row.
finish_processing_request can be as simple as updating the row with the result of the analysis. We need to do this in the same transaction as our select statement (that is why we are using FOR UPDATE), so the overall flow becomes:
- Begin a transaction
- Select a request with
FOR UPDATE SKIP LOCKED - Process the request
- Save the result and make the status no longer 'unprocessed'
- Commit the transaction
SQLAlchemy
Now that we know what we need to do, let's translate it to python. We'll use the ORM SQLAlchemy to interact with our database and psycopg2 as our Postgres adapter.
# this is a library which adds some flask-specific features to sqlalchemy
(venv) $ pip install flask-sqlalchemy
(venv) $ pip install psycopg2-binary
You'll want to set up and install Postgres, which you can do either with Docker or with their installers.
Afterwards, we can set up our database table. In the earlier example, we had a status column. In this example, we are going to just use a nullable analysis_result column. This is a little less general since it doesn't allow for error statues, but should be easy to extend.
We'll put our models in a new file models.py.
from datetime import datetime
import sqlalchemy
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.dialects.postgresql import UUID, JSON
db = SQLAlchemy()
class Analysis(db.Model):
# Let the DB generate a UUID for us
id = db.Column(UUID(as_uuid=True), primary_key=True, server_default=sqlalchemy.text("gen_random_uuid()"), )
# The 4 parameters to our request
fen = db.Column(db.String(), nullable=False)
num_moves_to_return = db.Column(db.INT, nullable=False)
time_limit = db.Column(db.FLOAT, nullable=False)
depth_limit = db.Column(db.INT)
# The result of an analysis. Null means we haven't processed it yet
analysis_result = db.Column(JSON())
created_at = db.Column(db.TIMESTAMP, default=datetime.utcnow, nullable=False)
updated_at = db.Column(db.TIMESTAMP, default=datetime.utcnow, onupdate=datetime.utcnow, nullable=False)
# A conditional index on created_at, whenever analysis_result is null
__table_args__ = (
db.Index('ordered_by_created_at', created_at, postgresql_where=(analysis_result.is_(None))),
)
We can then create this table from the python console.
(venv) $ python
# ...
>>> from models import db
>>> db.create_all()
Finishing the API
We're almost done with the API. Let's look at the remaining code in app.py in sections.
First, make sure we set any SQLALCHEMY config values and call db.init_app(app)
# ... same as before
from models import db, Analysis
app = Flask(__name__)
# This is the default URI for postgres
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://postgres:postgres@localhost:5432/postgres'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db.init_app(app)
Next, we'll update our analyze function to no longer analyze synchronously, but instead store the analysis to the database for later processing. The database will return an autogenerated UUID that we will return to the user.
@app.route("/analyze", methods=["POST"])
def analyze():
# Validate the request, same as before
parsed_request = parse_request(request.get_json())
# Save an analysis object to the database
analysis = Analysis(
fen=parsed_request.get("fen"),
num_moves_to_return=parsed_request.get("num_moves_to_return"),
time_limit=parsed_request.get("time_limit"),
depth_limit=parsed_request.get("depth_limit"),
)
db.session.add(analysis)
db.session.commit()
# The id is automatically populated after commiting
return {"id": analysis.id}
Finally, we need some way for our users to get their analysis. We'll create a new endpoint that accepts a UUID, validate that they pass in a UUID, and then fetch that UUID from the database. If the database object has analysis_result set, we know that it has been analyzed. Otherwise, we can say that it's still pending analysis.
# Can move this to our parsers file
# Make sure the UUID we are provided is valid
def parse_uuid(possible_uuid):
try:
return uuid.UUID(possible_uuid)
except ValueError:
return None
@app.route("/analysis", methods=["GET"])
def get_analysis():
# 404 if the ID is invalid or not in our database
id = parse_uuid(request.args.get("id"))
if id is None:
return abort(404)
analysis = Analysis.query.get_or_404(id)
if analysis.analysis_result is None:
return {"status": "pending"}
else:
return {"status": "done", "result": analysis.analysis_result}
And that's it for the API. We can submit chess positions to be analyzed, and we get back an ID. We can then poll the ID which will return pending until the analysis is ready. We can view this in action by running our server and using curl:
$ curl -X POST
-H "Content-Type: application/json"
-d '{"fen": "8/8/6P1/4R3/8/6k1/2r5/6K1 b - - 0 1"}' localhost:5000/analyze
{"id":"c5b0a5d9-2427-438c-bd4a-6e9afe135763"}
$ curl "localhost:5000/analysis?id=c5b0a5d9-2427-438c-bd4a-6e9afe135763"
{"status":"pending"}
The only problem now is that there's no worker to actually analyze the chess position. We're going to get back pending forever. Let's fix that now.
Creating chess analysis workers
In addition to being a webserver, Flask also supports a CLI. We can make a command which loops infinitely reading from the database and processing what it finds. In production, we can use something like systemd to keep the worker alive, and we can control how many processes we spawn to control how many positions can be analyzed in parallel per machine.
Let's start from the top, by making a worker command in app.py.
@app.cli.command("worker")
def worker():
with app.app_context():
run_worker()
Then we'll go implement run_worker in a new file worker.py.
import time
from chessengine import analyze_position
from models import Analysis, db
# Runs forever
def run_worker():
while True:
try:
did_work = fetch_and_analyze()
# If there was nothing to analyze, sleep for a bit
# to not overload the DB
if not did_work:
time.sleep(5)
except Exception as err:
print(f"Unexpected {err=}, {type(err)=}")
def fetch_and_analyze():
# This is the SQL query we saw before
# We are looking for rows with no result yet
# and we order by created_at to take older requests first
to_be_analyzed = Analysis.query.filter(Analysis.analysis_result.is_(None)) \
.order_by(Analysis.created_at) \
.with_for_update(skip_locked=True) \
.limit(1) \
.first()
if to_be_analyzed is not None:
# Use the function we created in our first post in this series
to_be_analyzed.analysis_result = analyze_position(
fen=to_be_analyzed.fen,
num_moves_to_return=to_be_analyzed.num_moves_to_return,
depth_limit=to_be_analyzed.depth_limit,
time_limit=to_be_analyzed.time_limit
)
print("Analyzed {}".format(to_be_analyzed.id))
else:
print("Nothing to analyze")
# Do not forget to commit the transaction!
db.session.commit()
return to_be_analyzed is not None
And that's the full worker. Most of the heavy lifting is done by analyze_position and you can use this
same structure to turn any synchronous API into an asynchronous one.
Let's test it by running our worker in a new terminal:
$ source venv/bin/activate
(venv) $ flask worker
Analyzed c5b0a5d9-2427-438c-bd4a-6e9afe135763
Nothing to analyze
Nothing to analyze
It found the request we made earlier and analyzed it. Let's verify that by hitting our webserver with curl:
$ curl "localhost:5000/analysis?id=c5b0a5d9-2427-438c-bd4a-6e9afe135763"
{"result":[{"centipawn_score":null,"mate_score":-2,"pv":["c2c1","e5e1","c1e1"]}],"status":"done"}
And we see the status is done and our result is analysis that we expect.
Wrapping up
We were able to take a clunky synchronous API and make it asynchronous, using Postgres as a work queue. Our users can now submit bursts of chess positions and our servers won't get overloaded.
In our next post, we'll use NextJS to build a UI for our application. See you then!

Top comments (0)