
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
Web scraping is a process of automating the extraction of data in an efficient and fast way. With the help of web scraping, you can extract data from any website, no matter how large is the data, on your computer. Moreover, websites may have data that you cannot copy and paste.
All the job is carried out by a piece of code which is called a “scraper”. First, it sends a “GET” query to a specific website. Then, it parses an HTML document based on the received result.
The reason why Python is a preferred language to use for web scraping is that Scrapy and Beautiful Soup are two of the most widely employed frameworks based on Python. Beautiful Soup- well, it is a Python library that is designed for fast and highly efficient data extraction. It's more like an all-rounder and can handle most of the web crawling related processes smoothly.
To extract data using web scraping with python, you need to follow these basic steps:
• Find the URL that you want to scrape.
• Inspecting the Page.
• Find the data you want to extract.
• Write the code.
• Run the code and extract the data.
• Store the data in the required format.
Let’s walk through an example.
“The United States collects and analyzes demographic data from the U.S. population. The U.S. Census Bureau provides annual estimates of the population size of each U.S. state and region. Many important decisions are made using the estimated population dynamics, including the investments in new infrastructure, such as schools and hospitals.The census data and estimates are publicly available on the U.S. census website”.
Steps to extract the weblinks from HTML code:
a. Import all the required libraries as shown
b. Set the url variable to the https://www.census.gov/programs-surveys/popest.html
c. Use request.get to fetch the details from the url
d. Use BeautifulSoup package to parse the html code and get the content from the website
e. Soup.find_all(“a”) gives all the links from the website
f. Link.get(“href”) provides the details of all the reference links in the website.
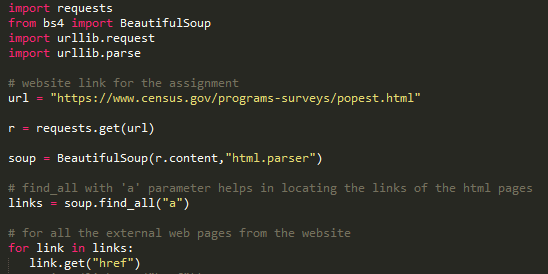
Let’s determine if a link is a locator to another HTML page.
“href” tag in the html code provides the details of the link locator to another HTML page.

Now will see how relative links are saved as absolute URIs in the output file.
• Create function unique_links with parameters of tags and url.
• Loop to all the links with “href” tag
• If there is ‘None’ then continue to execute the code.
• If the link ends with ‘/’ or ‘#’ then remove them from the link.
• Parse the url fetched from steps c and d and join with the actual url with the cleaned url by removing the ‘/’ or ‘#’
• Return the cleaned url.
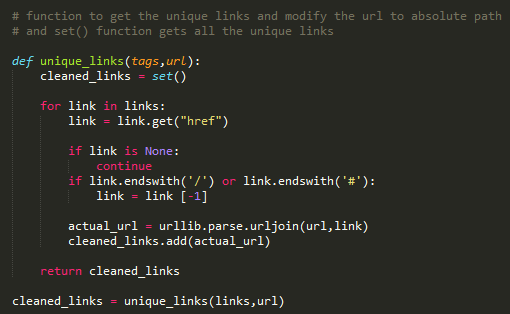
Will make sure there is no duplicate links in the output.
Set() function provides the unique url.

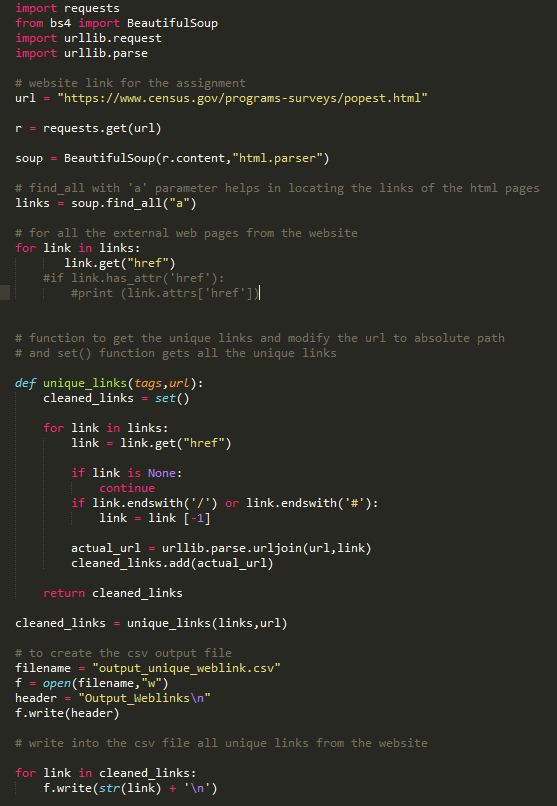
Write to a csv file:
filename = "output_unique_weblink.csv"
f = open(filename,"w")
header = "Output_Weblinks\n"
f.write(header)
write into the csv file all unique links from the website
for link in cleaned_links:
f.write(str(link) + '\n')
To execute the python code:
Go to the command prompt and execute the saved python code.
Python python_code.py
Conclusion:
By using python libraries we are able to scrap the website and extract the links successfully. And removed the duplicate links. Wrote the output to a csv file.

Top comments (4)
One more question, for some reason i am getting the following error in the code
def unique_links(tags,url):
cleaned_links = set()
cleaned_links = unique_links(links,url)
ttributeError Traceback (most recent call last)
in
13 return cleaned_links
14
---> 15 cleaned_links = unique_links(links,url)
in unique_links(tags, url)
7 if link in links is None:
8 continue
----> 9 if link.endswith('/') or link.endswith('#'):
10 link = link[-1]
11 actual_url = urllib.parse.urljoin(url,link)
AttributeError: 'NoneType' object has no attribute 'endswith' any idea why is that..
Can you check line 9, I think it is not recognizing # character and also can you please check if all libraries are loaded. Are any of your links ending with #?
thanks.. i ended up commenting out line number 9
Thanks Sharan, I wanted to know how do you open the csv file if one is using jupyter notebook online