
I currently work for a great company called Xero doing all sorts of fun data things. When you're reading my articles I need you to understand that my words are my own, I'm not speaking on behalf of my employer and If i'm talking about something negative in the field that may not be indicative of Xero, I've worked many interesting roles and I read a lot about my field.
First of all what is a linter?
For those who don't know a Linter is a tool that analyses code to flag errors, bugs, and stylistic errors
It's a great way to ensure that people are coding in a similar and consistent manner and not like a psychopath......

These sadly tend not to exist for SQL.
The highly contextual, and wildly variable nature of data stores means that while we all use the same keywords, but the devil is in the details.
For example it's quite common to champion the KISS principle in SQL code, just because you can join 15 tables together in one super query doesn't mean you should, it makes it difficult to test and maintain, and a clear sign you're a psychopath......
And while we could potentially build a coding framework or a linter to enforce that, there are just times where you have no choice but to join 15 tables together as its all down to how the data works together. Can you see the dilemma? You really can't tell people off if they have no choice.
In practice this generally means a data team may agree on a set of coding standards, which will differ in their level of comprehensiveness, and are left enforcing it based on how vigilant the peer reviews are.
They don't exist but you have one now?
Enter stage left!
Assistant by Tomasz Smykowski

A generic linter VSCODE extension that allows you to program in your own custom rules using regex.
I was genuinely very excited when I first saw this. I was in a bar at 2am and had seen the article and sent it to my work email right there right then. My friends where quite rightly judging my commitment to sparkle motion.
But I digress!
How did it go?
Well at first, not well!
I gave it a whirl and found that it wasn't working for the sorts of things I wanted it to catch. I quickly discovered that it didn't evaluate rules across multiple lines, which is important in SQL because we are forever writing:
Select column_name,
column_name,
From table_name;
And then running it, and then it errors, and then we change it, and then we do it again.
So I emailed Tomasz just to confirm whether that was intended functionality. That was on the 10th of July.
On the 13th of July Tomasz responded confirming that the linter does not work across multiple lines and that he had created an issue to get that changed as a feature request.
I thought, that's nice of him, but I was realistic. We all groom backlogs for a living and we all know that some backlogs last multiple presidencies.
Then Friday July 17th, 5:45pm, I'm drunk, work drinks, great time, email from Tomasz.
He did it!
Houston we have multi line support.
And yes I couldn't wait until Monday to try it out.
So how did it go? (The sequel)
Amazing....
We've loaded in fifteen rules in the past month and they're working well.
How to add rules
Well first you need to download the extension in VSCODE.
Then you need to go to your settings.json file, either in your global or workspace area, depending on how you work.
Add the following code to start loading in rules in regex:
"assistant": {
"rules":
[
load rules here :)
]
}
}
Note:
- You will need to double escape regex syntax i.e \b should be
\\b
- You may need to change the modifiers however, i = case insensitive, s = multiline, and g = global so I would only remove them if you 100% know what you're doing.
Some Examples
Comma on the last column
As mentioned earlier this is the the number one mistake we commonly make.

To add this rule to your linter:
{
"regex": "(,)(\\s*\\W*)(from)",
"message": "Reminder: you don't need a comma on the last column",
"modifiers": "sig"
},
Don't forget the ON after a join
Sometimes I go straight into adding 'and' conditions after my join and forget the on. (I've also been guilty of having more than one ON clause but that's not covered here.)

To add this rule to your linter:
{
"regex": "(join)(\\s*\\w*)(\\s*\\w*\\s*)(and)",
"message": "An ON keyword must follow a join condition",
"modifiers": "sig"
},
Ban people from using CTE's
In our environments CTE's aren't great for performance. However I still stand by never using them in production code even if they perform well. Something I'm not alone on:


{
"regex": "(with\\s)(\\w*\\s*)(as)",
"message": "Please refrain from using CTE's in production code. They are bad for redshift.",
"modifiers": "sig"
},
Don't use USING in joins
Other than trying to avoid an accidental bad join, we ban the use of USING as ON is just what we decided is best practice.
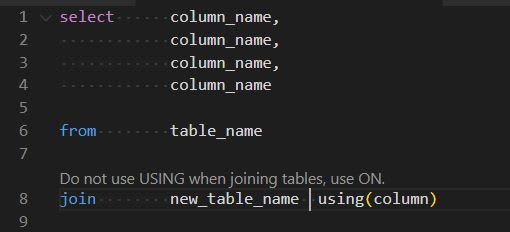
"regex": "(join\\s)(\\w*\\s*\\w*\\s*)(using)",
"message": "Do not use USING when joining tables, use ON.",
"modifiers": "sig"
},
Don't get your keywords out of order
How many times have you gotten your order and limit the wrong way around? Or Group / Having / order?

{
"regex": "(limit\\s*\\d*\\s*)(order|group|where|having)",
"message": "Limit should be the last keyword in the query.",
"modifiers": "sig"
},
To reassure commitment...
In modern environments you don't need to commit your code any more.

{
"regex": "commit;",
"message": "I can ensure you that Redshift does not have commitment issues, you do not need to write commit.",
"modifiers": "sig"
},
Prevent UNION
You should only ever use UNION ALL. A union scans for duplicates which BURNS compute and it will throw out duplicate rows. My advice is that if you want to exclude duplicates there are better ways.

{
"regex": "(union\\s*)(select)",
"message": "I can't think a valid reason to use union. You should always be using union all. ",
"modifiers": "sig"
},
Curb some bad compression
Only compression nerds like me know that a varchar(1) in redshift takes up over 7 bytes of space, when you could just use BOOL for a small 1 byte.

{
"regex": "char\\W1\\W",
"message": "You should be using a boolean if you are building a char with 1 space.",
"modifiers": "sig"
},
More info about Redshift Compression here:
Article No Longer Available
And More
We've made rules to catch out common spelling mistakes like 'selct' or to enforce certain practices like using '!=' over '<>'!
So how do I make my own?
So as mentioned earlier you need to download the extension in VSCODE and then set up your settings.json
Now you need to set up a rule, use this template:
{
"regex": "",
"message": "",
"modifiers": ""
}
Don't forget to add a , after each rule, i.e
{
"regex": "",
"message": "",
"modifiers": ""
},
{
"regex": "",
"message": "",
"modifiers": ""
}
Then figure out what you want to catch out.
Beware: You are limited to what you can detect using a REGEX pattern. So you'll need to think about how you will do that and just accept that some rules you won't be able to catch.
For example not closing brackets ( ), it's hard to write a REGEX rule to catch that as what you really want is an exception rule.
To test whether I can do what I want to do I use something like rubular to test my regex.

If I get it working, I load it into the settings file and away we go!
Things to Note:
- It's got its limitations, it won't work for ever rule, primarily due to the limitations of REGEX not the extension.
- It works all over VSCODE (even in the settings file) so if that annoys you, make sure to use the workspace feature, though there is a feature request to be able to lock the rules to specific file types (this will be handy for those of us who switch coding languages)
- If you make your rule too generic you risk crashing VSCODE as the rule will scan as much as the rule allows.
Share your findings!
Tomasz has a github for this extension where he asks that you submit your own rule file to help others! CSS, HTML, Ruby, Python!
I've already added my sql rules as a pull request :)
 tomaszs
/
Hintly
tomaszs
/
Hintly
Boost your development by providing custom tips displayed in the code in Visual Studio Code
Demo
Hinty (formely: Assistant) is language and framework agnostic.
Example workspace configuration for Angular/TypeScript. It informs about a bad boolean Input declaration in Angular component. Normally it does not trigger build or linter errors and is a hard to track problem:
{
...
"settings": {
"assistant": {
"rules": [
{
"regex": "@Input\\\\(\\\\) .*: false;",
"message": "Define property value with =, not with:"
}
]
}
},
...
}
Result:

Hinty - Dynamic Hints For Your Code
Are you annoyed that your notes on hard to fix issues are not available when you need them the most - while coding? Is setting standards for the team code broken even if you have a centralized place for rules because it i hard to keep tabs on them all the time?
Never make the same mistakes again!
At last there is a solution to these problems. Let me present you a groundbreaking Visual…
Reminder: All views expressed here are my own and do not represent my employer, Xero.
Who am I?


 Ron-Resist Racism-Soak 🏳️🌈🇳🇿@ronsoak
Ron-Resist Racism-Soak 🏳️🌈🇳🇿@ronsoak Hi, I'm Ron!
Hi, I'm Ron!
🛰️ I ❤️ space!
☕ Coffee Addict
📊 Data Analysis Team Lead for @Xero
⚠️ My words are my own.
✍️ Writer on @ThePracticalDev (dev.to/ronsoak)
✍️ Writer on @Medium (medium.com/@ronsoak)
|🇳🇿 |🇬🇧 |🏳️🌈11:11 AM - 29 Jun 2020



Top comments (1)
This is soo cool. SQL tools are so sparse. I have found one auto formater that kind of works for me, but no linter.
The tool that I would really like to see for SQL is a transpiler. I would like to work from a more common flavor of SQL and have it transpiled into the various dialects.
Somehow it seems that SAS does this. I have shared code between myself and a SAS user. I will run into errors with dialect and somehow they get by just fine. I have no idea what was is doing under the hood, but it seems amazing.