
Every week here at Stratiteq we have tech talks called "Brown bag". Idea behind it is to grab your lunch (brown) bag and join a session where we watch presentation about different tech topics, and discuss it afterwards. Last week our session was about Azure Computer Vision.
Computer Vision is an AI service that analyses content in images. In documentation you can find several examples how to use it from different programming languages, in this post you'll also see one example that is not in official documentation and that is: how to analyse a local image with Javascript.
In order to set up Computer Vision you should log in to the Azure Portal, click "Create a resource", select "AI + Machine learning" and "Computer Vision".

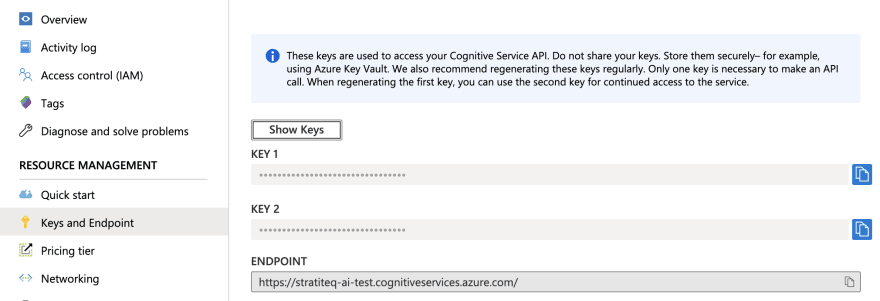
Define resource name, select subscription, location, pricing tier and resource group, and create the resource. In resource overview click on "Keys and Endpoint" in order to see keys and endpoint needed to access the Cognitive Service API. This values you'll need later in code we'll write.
Sketch of HTML page we will create is visible on the image below. We'll use camera and show feed on the page, take screenshot of camera every 5 seconds, analyse that screenshot with Computer Vision and display description under it.

For setup of our page we'll use following HTML code, please note JQuery is included in page head.
<!DOCTYPE html>
<html>
<head>
<title>Brown Bag - Computer Vision</title>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.9.0/jquery.min.js"></script>
</head>
<body>
<h2>What does AI see?</h2>
<table class="mainTable">
<tr>
<td>
<video id="video" width="640" height="480" autoplay></video>
</td>
<td>
<canvas id="canvas" width="640" height="480"></canvas>
<br />
<h3 id="AIresponse"></h3>
</td>
</tr>
</table>
</body>
</html>
We'll use simple CSS style to align content on top of our table cells and set colour of result heading.
table td, table td * {
vertical-align: top;
}
h3 {
color: #990000;
}
Inside of document.ready function we'll define our elements, check for camera availability and start camera feed.
$(document).ready(function () {
var video = document.getElementById("video");
var canvas = document.getElementById("canvas");
var context = canvas.getContext("2d");
if(navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
navigator.mediaDevices.getUserMedia({ video: true }).then(function(stream) {
video.srcObject = stream;
video.play();
});
}
});
You can check compatibility of mediaDevices on following link: https://developer.mozilla.org/en-US/docs/Web/API/Navigator/mediaDevices
Every 5 second we'll take a screenshot of our camera feed and we'll send blob of it to the Computer Vision API.
window.setInterval(function() {
context.drawImage(video, 0, 0, 640, 480);
fetch(canvas.toDataURL("image/png"))
.then(res => res.blob())
.then(blob => processImage(blob));
}, 5000);
Result processing is done in processImage function where you need to enter your subscription key and endpoint in order to make it work. Those values are available in the Azure Computer Vision overview as mentioned earlier.
function processImage(blobImage) {
var subscriptionKey = "COMPUTER_VISION_SUBSCRIPTION_KEY";
var endpoint = "COMPUTER_VISION_ENDPOINT";
var uriBase = endpoint + "vision/v3.0/analyze";
var params = {
"visualFeatures": "Categories,Description,Color",
"details": "",
"language": "en",
};
$.ajax({
url: uriBase + "?" + $.param(params),
beforeSend: function(xhrObj){
xhrObj.setRequestHeader("Content-Type","application/octet-stream");
xhrObj.setRequestHeader("Ocp-Apim-Subscription-Key", subscriptionKey);
},
type: "POST",
cache: false,
processData: false,
data: blobImage
})
.done(function(data) {
});
}
Result we receive from the Computer Vision API is JSON, we'll take description from it and add it to the header 3 element named "AIresponse".
document.getElementById('AIresponse').innerHTML = data.description.captions[0].text;
We did few tests with it, Computer Vision describes images really well, if you mess around with you could also get few funny results as we did:

Thanks for reading, you can find full code on the GitHub: https://github.com/gvuksic/BrownBagComputerVision

Top comments (0)