I recently read a great blog article by Coding Unicorn over on dev.to titled “Flexible code considered harmful”. Forgiving the over-used “considered harmful” title, the article was extremely thought-provoking. It’s fairly short and I recommend you give it a read.
She makes an interesting point about how creating flexible code means that the code could be easily extended in the future, but those extension points have a cost in increased complexity. This means that the code is actually harder to understand and harder to change.
She also mentions the “Use/Reuse Paradox” (another good read, if a bit abstract) which indicates that things that are easy to use are difficult to reuse.
Her summary point is “flexible and abstract code is hard to use and also hard to understand”. This point is certainly worth consideration. As we make code more flexible and abstract, does it become harder to use and understand?
Let’s analyze this with some sample code.
Let’s use an application that organizes and displays articles. Here is the structure for a sample article (highly simplified):

As indicated, each article can be tagged with one or more tags. In our interface, if we select one tag, we want to filter a list of articles by that tag. But we want to be able to drill down as well. For example, after selecting all javascript articles, we may want to drill down to just those related to Express. So once we select a tag and filter the articles to just those with that tag, we need to create a list of tags that all of those articles contain. We will need to make sure this list is de-duplicated, and we also need to remove the selected tag from the list.
Be sure you understand what the requirements of our task are before you try to read the code. Now let’s create an algorithm to do this given a list of articles and a selected tag:

To understand anything unfamiliar in the above code, see the notes for the algorithm here.
I wrote this algorithm very straightforwardly. I tried to make it simply do the work. I added no abstractions. I would consider this the quickest way to get it working. It does the job, and the code is perhaps “simple” since it uses little to no abstractions. Does that make it easy to use? Certainly calling the function is easy to do.
But what if we applied some typical coding refactorings and introduced some abstractions?
Exercise: For a fun exercise, try taking this algorithm and “fixing” it before you look at my adjusted solution. Just make it better and more readable according to your own judgments. You can click this link and make your changes. Then compare to what I did with my fix shown below and see if you arrived at a similar solution.
And now here’s the refactored algorithm, adding what I considered to be appropriate abstractions:
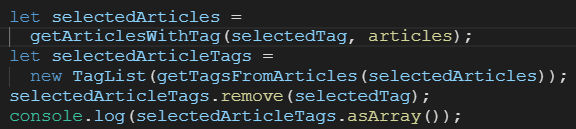
Look at what has happened. I’ve created some sub-functions and a single class TagList, and now I’ve got all these reusable pieces that could be composed to do other jobs. Most of these functions can easily be reused. The TagList could be used in a lot of other places doing other jobs with tags in an application like this.
I’ve added abstractions. I’ve arguably made the code more extensible and reusable. Have I made it more difficult to use or understand? You’d have a very hard time convincing me that the original solution was better in any way.
Would you say that this code is more readable than the original algorithm? Although readability can be subjective, I would guess that most people would say the new algorithm is more readable.
One important point about abstractions that is critical to understand is that an abstraction is basically a way to handle several smaller pieces together with a simpler, single “handle.” A good example of an abstraction is a steering wheel in a car. It’s a simple tool that actually controls a very complex mechanism of rods and gears and various pieces. When we abstract away some of our code we give ourselves a simpler way to work with and reason about that code. That reduces our cognitive load. In this fantastic article on programming and cognitive load, you can read about how cognitive load is essentially our hard limit as programmers. Abstractions allow us to work better and faster.
Of course, like all things, this can be taken to an extreme. We generally call this over-engineering or the YAGNI principle.
So, by adding these abstractions, did I over-engineer the solution? Was adding a “TagList” class too much? I tried implementing the algorithm without that class and I honestly felt like it made the code simpler. Another fun exercise: take my final algorithm and try to refactor it and remove the TagList. After you do ask yourself if you think the code is now easier to use?
One final point to explore is that we have used a rather simple code here. In a production system, the complexity is often multiplied by a factor of 10 or more. So does this hold up in a more complex system? We would have to spend hours (or perhaps weeks or months) together working on a system to really answer that question fully, but for reference, I actually based this example on a more complex algorithm that did the same thing in a production application I built. In that application, I implemented the full algorithm and even with abstractions I had a very difficult time keeping the cognitive load light enough to arrive at a correct solution. Without the abstractions, I would never have been able to create a working solution.
So yes, we can over-engineer things, but avoiding abstractions is unlikely to make our code easier to write or read or extend.
Agree? Disagree? Signup for my newsletter at here.
Visit Us: thinkster.io | Facebook: @gothinkster | Twitter: @gothinkster

Top comments (1)
I kind of feel like it's got to be on a case-by-case basis.
If I'm working at the method level, I'll usually move blocks of code to private methods if it makes it easier to read (being able to label the code via the method name is a huge plus in my view).
I usually do the opposite with classes, though. I find they proliferate so quickly, and things turn into a rats' nest so fast. I might just not be very good at OOP though.