
Developing with docker containers is great! And we at uilicious run our entire backend on top of docker.
It would have been impossible to have launch uilicious at our current cost and scale without docker.
However as with all technologies, there are hidden, not so obvious, gotcha’s reaching there, especially when running Docker at scale across multiple hosts. Especially for those migrating from physical servers, or virtualized machines workload.
To be clear, this article is not about system optimizations. But about common wrongly configured settings which can bring demise to you and your company (YMMV); Where your production systems can suffer from a long down time, or worse, data leakage to hackers.
This article also assumes you have slight basic docker knowledge on localhost.
Hence, here are 5 fatal gotcha's that I have unfortunately experienced and survived from using Docker across the past 4 years as well as a quick summary at each point. And how you can avoid them.
Note that when I refer to situations involving multiple hosts, this only applies for docker setups larger than a single host such as rancher 1.6 (which we use internally), Docker swarm, or Kubernetes, etc.

1) Docker does not play nicely with firewall
Docker host port binding, bypasses typical iptables INPUT rules
Regrettably, many would instinctively start to use Docker by binding container ports to the host, either mirroing their usual setups in traditional linux (thinking their usual iptables firewall rules on the host would work without verifying them). Or by following many online beginner guides, which tends to bind ports to "host" for ease of development, on a local machine (without any advisory on this issue).
However, Docker port binding uses iptables PREROUTING level by default. Which takes precedence over most iptables INPUT firewall rules that many commonly use to protect their systems.
The end result : public exposure of privileged ports, such as MySql, to the Internet. Worse still, NoSql ports commonly comes deployed without authentication, leading to the exposure of all the private customer data as a gift to hackers.
Mitigation guidelines
- Mitigate by using container to container communication
- Mitigate using network based rules
- VPC/Firewall rules for AWS, Azure, DO or Google Cloud
- On-premise router rules
- Does not apply for Linode
- Alternative last resorts
- Scrutinize, manaage and secure all host binded ports with authentication
- Use custom docker iptables
Fortunately, most of these scenarios can be easily mitigated by applying network based firewall rules inside Virtual Private Cloud (VPC) from providers such as Google or AWS. Or, applying similar rules their on-premise router that exposes the servers to the public securely.
Yet for some cloud providers, this solution is not an option, most notably Linode where the private network plainly refers to having public access for all customers within their respective local data center.
In such cases, alternatively; you can scrutinize the ports that are bound openly and ensure that they are properly secured with a complex random generated password, and that all non public communication occurs between container-to-container networking or even implementing Two-Way SSL authentication. Or learn up the rather complex process of setting up docker iptables rules.
Additional details

2) Not understanding docker data persistence
Docker does not persist any container data by default!
First of all, this is an extremely complex topic, and I am just going to oversimplify it.
So here is a quick crash course in how data is persistently handled in container. Especially when containers are either restarted (stop-and-start), or redeployed to another host.
- Container, without volumes, store changes locally and temporarily. Data is destroyed if container is redeployed.
- Default volumes, are persistent only on host, and does not transfer across host machines
- On container shutdown, or health check failure, either of the following occurs.
- Restart, container data, and volumes persist
- Redeployed on the same host, volumes persist, container data is destroyed
- Redeployed on a different host, no data persists !!!
- This can occur in non-obvious ways such as host temporary failure
- Infrastructure tool just decides to do so on a friday
- Orphaned volume may get deleted by cleanup functions
- Host storage can be mount directly as a volume, however...
- this will be harder to monitor via docker
- still suffer most of the same drawbacks to host volumes
- atleast data does not disapear into a blackhole, and can be recovered using traditial SSH
- in some critical cases this is preferred (we use this method for elasticsearch)
- If auto rebuild onto other hosts is allowed, plan it extremely carefully.
So what do these mean? Here are some failure scenarios that truly happened, and salvaged via backups.
Single container with a volume, without host restriction
You have deployed a MySql container with a volume, on failure it restarted by default. One day as the host that is running mysql was disconnected from the docker cluster. Its cluster manager redeployed the container onto another host, attaching to a new volume.
Even worse there was a cleanup script for removing dangling volumes & containers. Making the data unrecoverable by the time you wake up.
Host restricted container, without volume mount
You have designated a Jenkins container to deploy specifically on one host, and ensure its failure condition is to do nothing. This will mitigate the "rebuilt on a different host" scenario, yay!
However, on one sunny sunday, you notice that there is a security update required for Jenkins. You decided to click the upgrade button. Poof all your data is gone, as your container is being redeployed.
Distributed redundent systems, without host restriction
You have deployed ElasticSearch on multiple hosts, with their respective volume container; Trusting that even if they were to fail individually, the magic inside ElasticSearch will rebalance and recover the data from its other replicas. One day you decided to do an upgrade, however you did not realise that you were running many more hosts in the cluster than the required containers.
During the upgrade, all the new version was deployed to previously unused hosts, and the old containers were terminated. Without having sufficient replicas, nor time to transfer the data over, as container start and stop actions are immediate.
All the data is lost. This can silently occur if you are using an autoscaling group.
Mitigation guidelines
To mitigate the scenarios mentioned above, the following should be applied.
- Have backups, and learn how to restore them
- Ideally throw your persistent data outside your docker infrastructure
- Use cloud managed SQL, or the various cloud managed Object / No-SQL services that are available
- Or use the equivalent of google persistent disk / aws EBS directly in your docker container (if supported)
- Containers should as much as possible, hold zero data that requires persistency
- Examples (zero persistency) : Frontend servers, Application servers
- Counter-examples (requires persistency) : SQL servers, file servers
- For containers that hold persistent data
- Be aware and cautious on what is the configured on healthchecks and its failure behaviour
- Plan your upgrades carefully, upgrade one container at a time if needed
- Healthcheck can be configured to "do-nothing" in response (perform manual intevention when needed)
Additional details
- Docker official documentation here, and here
- Managing persistence for docker

3) Using :latest tag for containers
Unmanaged auto upgrades, can break your systems.
A common pattern is to use a base container image, which you would consolidate for commonly required container modules and extend from for more comprehensive container images.
Alternatively one would use latest official containers images for deployments such as Jenkins, etc.
However, in event of server failure, and its subsequent auto scale replacement, the latest upgrade dependency maybe out of sync with the rest of your cluster.
In addition, there are times that the latest version makes backwards breaking change against your system that will result into major downtime. It only gets worse when certain systems can only be upgraded in one direction and will modify the shared files or resources in the process (eg: Jenkins, GitLab).
This situation can create complications in tracing bugs. Where you may encounter this issue only in one machine but not another. Where it cannot be salvaged until changes are made such as indicating a fixed version to be used instead of the latest tag in the container template thats is used.
On production environment, you will definitely want to take things slow and use fixed versioning, or at the very least, major versions / stable branch. For testing however, feel free to go bleeding edge on :latest if you feel the need for speed.
For more rants see here.
Mitigation guidelines
- Just do not use
:latest, adjust the rest according to your requirements- Alternatively, only use your own container registry, and hand select all images deployed on it - this is the slow and painful way done in banks

4) Containers do not have persistent IP address
Assuming persistent IP address of containers.
Assuming persistency of IP addresses can create perplex problems, commonly on nginx load balancer. Worse still, is to hard code IP addresses in the configuration files. This can create baffling errors, where every container is "online" and appeared fine, but they are not communicating to one another.
For example, if you are using Nginx as a load balancer to multiple containers, the IP addresses of domain names are resolved on startup by default. This means that if any of the containers' IP addresses that the Nginx load balancer is connected to is modified, the load balancing will not update and fail. (unless you are using Nginx Pro)
Mitigation guidelines
- kubernetes : learn to use cluster IP, its a game changer against this problem.
- Configure your stack to use hostnames over fixed ip addresses
- This assumes the application supports dynamic ip on hostnames
- Use alternatives to Nginx like HAProxy, or Traefik for load balancing,
- If not possible, use health checks to automate contatainer restarts to fix hostname routing
Additional details

5) Lack of CPU, RAM, disk - in planning and monitoring
Docker is just an abstraction layer, fundamentals are unchanged
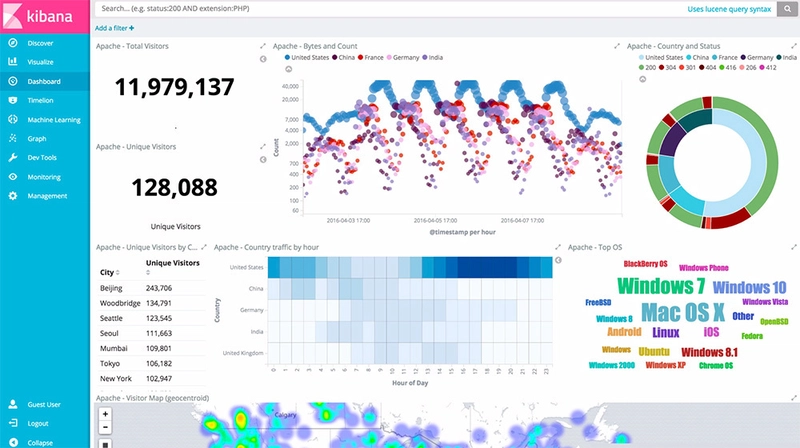
This is particularly annoying, as by default on most cloud providers, Random Access Memory (RAM) and disk storage usage is not shown on the instance dashboards.
With poor planning, a single host failure can cause a chain reaction of "out-of-resource" errors, by forcing the cluster to relocate the affected container into other hosts. Which in turn, will trigger more "out-of-resource" errors.
A common example of this occurrence is during the deployment of multiple containers such as SQL, NoSql or file servers. Which by default would simply attempt to consume as much ram as possible for performance, as usage increases.
Another thing that is commonly forgotten : entropy, and log rotation
Without doing so, if you are using an authentication system or SSL, entropy will slow things down to the halt at some point. Alternatively, log rotation is favorable to ensure that your server does not run out of file space due to logs.
Finally, backups, backups, and backups.
Mitigation guidelines
- Plan your RAM and disk usage requirements properly, keeping in mind to having additional buffer space if case of any overheads that may occur.
- Place limits on RAM for individual containers.
- Use this to limit damage for "out of control" errors, from a container, to others on the same host.
- Monitor your usage requirements either via dashboards, or manually every now and then
- Elasticsearch your metrics (free, but troublesome to setup)
- Datadog your metrics (not-free, but many things are out of the box inbuilt)
- Clean up dangling containers / images / volumes, which will free up unused space.
- Deploy server essentials (according to your requirements)
(Just in case): To restore clusters from perpetual failure state
Note that when such cascading "out-of-resource" error occurs, the safest solution is to
- Stop / shutdown the whole cluster
- Stop all scheduled containers
- Reactive containers group by group
In this manner, the cluster does not get overwhelmed at any given point in time.
One more thing : Monitoring is not only about http code 200
Monitoring applies to functionalities as well. After all, it is possible for static files server to be successfully up and running. While a corrupted JS files, which will cause all browser functionality to break silently.
While you can achieve this with complicated healthcheck commands built into your api or textual based health check for static websites.
You can simply use uilicious to do the job monitoring for you. Where you can rapidly build up simple test cases to do full end-to-end testing of websites, and schedule test runs in the background. Where we notify you in the event of test case's failures automatically.
// Test scripts can be as simple as the following
I.goTo('https://google.com')
I.fill("Search", "uilicious")
I.pressEnter()
I.click("Smart User Journey Testing")
I.amAt("https://uilicious.com")
- You can give the above test snippet a try on our public test platform (no login required)
- or signup for a free trial.
Ending notes
Hopefully the above will help you to avoid what could be otherwise painful experience. However as with all new fast moving technologies, take everything with a pinch of salt. (PS: this was updated Nov 2018)
- Docker scene and tools are changing rapidly, continue to learn and read around.
- Nothing is magic, it is all tools, learn it.
- Don't blindly trust defaults, and tutorial guides, learn what they do.
- Learn how would your system fail in various possible scenarios, and plan around them.
Most importantly - have a testing environment, and perform experiments there, where you can fail safely in the process.

Top comments (5)
Ahh yes, I probably should add this in when I revise the article for 2019.
Yup secrets built into containers : especially in particular public containers are a big one.
Mitigation beyond "not placing them in dockerfile" however is much more complicated.
Beyond that : only solutions like vault, or for every docker management system - be it kubernetes or swarm, text file based secrets management. Are currently the only main options.
For compose, and environment variables however : the practise is to simply not use it publicly but internally.
For heavily regulated industries, as far as I know. They would instead isolate the docker management system, and container repository from the developers. Where only a sysadmin (who has the keys anyway) could then perform the deployment, after building the containers from the source code into repository.
Not ideal as its not full CI/CD, and can sometimes be somewhat manual in the process
Great article! Although I use docker only on my system, I have nice(🤨) memory of 2nd point you mentioned about data persistence. I was using docker for very first time. Wrote some code with really great efforts(😎), and closed the system normally. Next time opened to show to a friend, and 💥...NOTHING WAS THERE...it's feels nice when someone explains mistakes you learned from...
I feel you there - I still make this mistake every now and then till this day...
It always start with : hmm lets make a small minor 1 liner tweak to see if this will make the container better
....
1 page of bash script later : poof 😱
Thanks for the article!
For the 1st point there is a good practice to bind port to the localhost if you only need to use service locally:
-p 127.0.0.1:8080:8080Unrelated to anything of substance; just something that I chuckled at... if you are reading a Docker article but don't know what RAM stands for -- you are in trouble!