
Managing Elasticsearch indices at scale isn’t easy.
Index settings were part of our core application monolith logic. Making the slightest change to them meant that the whole application had to be redeployed, lots of unrelated tests had to run. Also, it was built to be only aware of a single language. We needed to be more flexible and have fine-grained control over our Elasticsearch clusters.
At the same time, we were planning to break our single Elasticsearch cluster into multiple ones for better load distribution and the ability to upgrade smaller clusters. Managing all of that from a single application was difficult. See how we managed to manage search traffic across multiple Elasticsearch clusters in second chapter of these series.
We’ve decided to decouple search setup and ingestion logic into a separate application, very obviously called Elasticsearch Index Management, or EIM for short. It would turn out to be a set of CLI utilities, automated jobs, and webhook listeners to automate our routine work. I’ll share how we solved these problems and what we learned.
Goals
There were no well-defined and clear goals when we started this project. All we really wanted was to solve our pain points:
- Manage indices and their changes with ease
- Control the data indexing pipeline
- Detect Elasticsearch version inconsistencies
- Automation of the search infrastructure
Index management
Vinted operates in 13 countries, we support the search for our feed, promotions, forums, FAQ search, and more. Naturally, we need to support multiple languages.
Elasticsearch templates are well suited for this use case. They’re composable, have great flexibility, allow dynamic field detection and mapping.
We identified that language-agnostic analyzers, language analyzers, index settings, index mappings, and ingestion pipelines are the key elements to construct a template. Indices we create based on templates are consistent and guaranteed to be as per spec. To keep templates correct and up to date, we test them during each CI build and refresh them on clusters during every release.
The way we construct templates also reflects on our code structure. Analysis, indices, pipelines, and other potential parts are grouped together and later merged into a single template.
elasticsearch/
├── analysis/
│ ├── common.rb
│ ├── english.rb
│ ├── french.rb
│ ├── lithuanian.rb
├── indices/
│ ├── faq.rb
│ ├── feed.rb
│ ├── forum.rb
│ └── promotions.rb
└── pipelines/
└── brands.rb
To prevent human errors and catch issues before deployment, we heavily test all of the template pieces:
- Field index and search time analyzers
- Field settings, such as its
type,norms,doc_fieldsorcopy_tovalues. - Index settings, such as number of shards and replicas, refresh intervals
- We test ingestion pipelines by simulating them and comparing before and after payloads
We harness Elasticsearch /_analyze and /_ingest/pipeline/_simulate APIs results by creating custom RSpec matchers. They allow us to write our domain-specific tests, which are elegant, short, intention-revealing.
The following matcher extracts tokens produced by /_analyze API and allows comparing them to expectation.
RSpec::Matchers.define :contain_tokens do |expected|
match do |actual|
tokens(actual).sort == expected.sort
end
failure_message do |actual|
"expected: #{expected}\n" \
" got: #{tokens(actual)}\n" \
"\n" \
'(compared using ==)'
end
def tokens(response)
response['tokens'].map { |token| token['token'] }
end
end
And this is an example of how it is being used in specs:
context 'with special letters' do
let(:text) { 'šermukšnis' }
it { is_expected.to contain_tokens ['sermuksnis'] }
end
Data ingestion
From chapter 1, you already know that we leverage Kafka and Kafka Connect for data ingestion, meaning they both are an integral part of Elasticsearch Index Management. We also make heavy use of Elasticsearch Sink Connector and use it to reindex data whenever it is needed.
We built a set of abstractions that help us to achieve that. To reindex data, we'd begin with creating connectors for a specific type of indices. The following code would generate a collection of connectors with automatically generated names and configurations:
eim connector create --indices=Promotion Feed
Once the connector has caught up with indexing, it can be tuned for idle indexing to reduce indexing pressure on the Elasticsearch cluster:
eim connector update cluster-core-feed_20201217140000 --idle-indexing
In case of an emergency, a connector can be paused.
eim connector pause cluster-core-feed_20201217140000
We use Elasticsearch aliases API to atomically switch aliases between indices. After carefully observing metrics and being sure that everything's in place we'd run the following command to assign aliases to new indices and remove them from old ones.
eim alias assign --indices=Promotion Feed
Testing
We have first-hand experience that Elasticsearch upgrades are not always successful and rolling back might not be possible at all. One of the key reasons Elasticsearch Index Management exists is the ability to easily test cluster and indices settings against different Elasticsearch versions.
To avoid hassle of setting up multiple Elasticsearch versions locally, testing environments are containerized and consist of shared docker-compose files. This setup allows us to create environments for development, testing, and experiments with very little effort. For instance:
docker-compose \
-p stack-7 \
-f docker/docker-compose.es-7-base.yml \
-f docker/docker-compose.es-7.yml \
-f docker/docker-compose.kafka-base.yml \
-f docker/docker-compose.kafka.yml \
up
At some point, we had to support Elasticsearch 5.x, 6.x, and 7.x. The following diagram showcases how a single environment looks like. CI build would create an isolated environment for every Elasticsearch version we support and run over 600 tests for each environment in parallel.
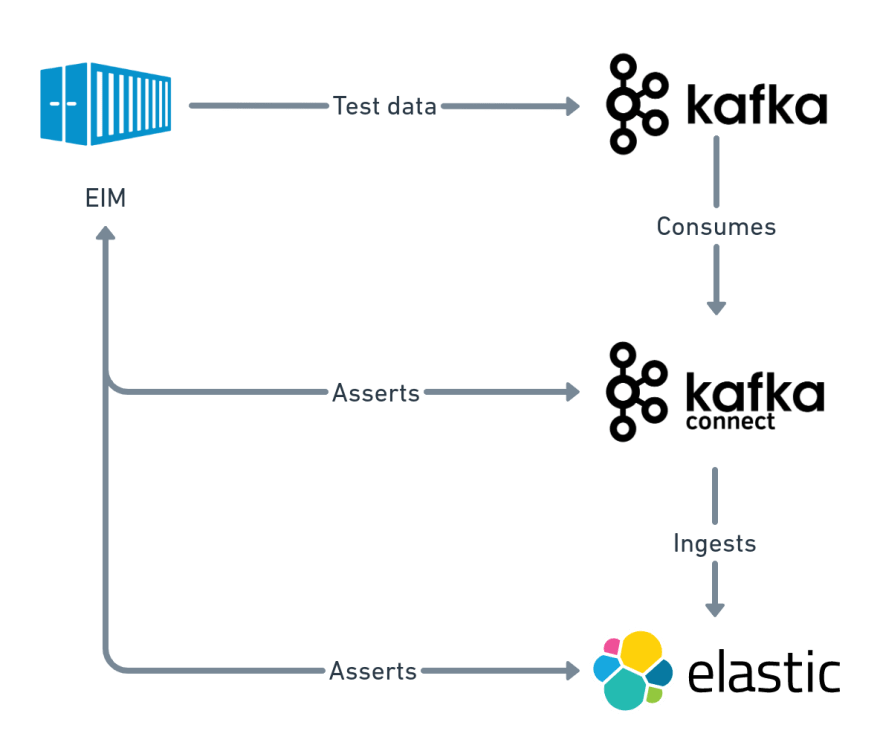
Webhook listeners
Kafka Connect connector tasks occasionally fail for various reasons, such as a network hiccup, out of memory exception. Initially, we would restart them manually, however, that wasn't sustainable and we needed a better solution.
Vinted uses Alertmanager for infrastructure monitoring. Out of the box, it can send alerts to email, Slack, additionally it allows configuring generic webhook receivers.
We built such a receiver on top of Elasticsearch Index Management, deployed, and made it a part of Alertmanager configuration. From now on, when a connector task fails, Alertmanager sends a RESTful request to restart it.
Wrap up
One year later, Elasticsearch Index Management has become a vital part of our job. Before that, everything from cluster upgrades to a simple change of index configuration was an adventure. Now it's predictable, automated, and boring. During one year of development, we caught most of the edge cases, ironed-out most annoying bugs, and built ourselves a companion that lets us stay productive and look after Elasticsearch estate with ease.

Top comments (0)