This series is about sharing some of the challenges and lessons I learned during the development of Prism and how some functional concepts taken from Haskell lead to a better product.
Note: As of January 2021, I no longer work at Stoplight and I have no control over the current status of the code. There is a fork on my GitHub account that represents the state of the project when I left the company.
In the previous post we saw how I discovered a set of abstractions that apparently were a perfect fit for Prism's use cases. In this post we'll instead cover how we got the concepts applied for the first time in Prism.
Finding an introduction point
At this point, I was convinced that adopting fp-ts in Prism would make a lot of sense; the problem was to find a way to introduce it in a reasonable way.
Prism was already at a late development stage. Although we didn't have a fixed timeline we were already releasing beta versions a couple of times per week and we also had a decent amount of users trying it out.
For these reasons, I decided there were a couple of points that I was not willing to compromise while trying out fp-ts.
- Although we did not have a precise deadline, I knew that Prism's stable release was close. For this reason, no matter what was the state of fp-ts in Prism, I set myself the goal that the
masterbranch should always be ready to be released as the new major version. - Because we already had a good number of users, I set the hard rule that we would never break the user space
- Because I knew that this was new stuff even for me and nobody in the team was really into functional programming, I set the aim of introducing this into a relatively low-risk part of the software so that:
- It would be relatively easy to revert the changes in case we'd realise that fp-ts wouldn't really fit the use case or in any case not play well together with the rest of the code base
- In case we would have misunderstood some parts of the library or screwed up something, it should not alter the software in any way. Preferably, the main features of Prism should still be functioning correctly
These are very strong constraints, narrowing down the possible choices a lot. I guess that's the fun of the software modelling.
Eventually the occasion I was waiting for came up.
Logging in Prism
Logging is probably one of the most appreciated features of Prism because it provides a clear introspection on the decision process and tells you exactly why Prism has decided to respond to you in such a way.

Moreover, the logger brought a lot of value to us as well. If for some reason Prism would respond incorrectly, because of the logger being so verbose we've always been able to quickly identify what component was misbehaving (negotiator, validator, the http server)
Thinking about the logging in Prism I realised that:
- There would be no way the logging would break the user space, since there was no impact nor in the CLI, nor the Prism HTTP Client API nor the Http Server
- The worst that would happen in case the logging would be wrong (because of a misusage/misunderstanding of fp-ts) would have been wrong log lines; the mocking functionality wouldn't have been affected per-se
- At the time of the introduction logging was planned only for the Negotiator, making possible an ideal "revert PR" and return back to where we were.
For these reasons I thought the logging was a good introduction point and I took the risk of trying it out fp-ts.
Getting the PR merged
I decided to go with pino as a logging solution. The decision was NOT based on the low overhead/high performance claims that are on the website/project documentation, but more because Pino does not include any way to process/alert/react to logs; it simply outputs the log statements as JSON on the stdout (or any stream you provide to it). It means that, by design, there's no way somebody can make messes with logs and do any action that's logging dependent. You can't break what's not even included.
Now the compromises start to come. In the complete pureness of the functional world, writing messages on the standard output through console.log is deterministic (since it always returns undefined) but it has a side effect (printing on the screen).
Haskell indeed considers it as an action that can only be ran in the main program
putStrLn :: String -> IO ()
Similarly, fp-ts provides the same mechanism:
export function log(s: unknown): IO<void> {
return () => console.log(s)
}
Moreover, printing on the screen is not considered something that it might fail – so the Either abstraction (which is the one I really valued in Prism and wanted to adopt) would not be useful in this specific case.
We'll talk more about the compromises in a next article; however I decided, at least to start that:
- I would not consider the
console.logas a side effect; therefore the actions would have been considered pure at the time. I was perfectly aware that it's wrong, but to respect the rules that I gave myself (and listed above) I had to go with a minimal codebase invasion - Since logging is not considered to be a failing action and I would not consider it to have a side effect, I decided instead to get started with the Reader monad.
The idea was to use the Reader monad to inject the logger to the Prism Http Package without having to pass it explicitly as a parameter everywhere.
This made a lot of sense, since we wanted to have different loggers according to the context (CLI, Hosted Prism).
I had a very brief conversation about my intentions with one of my coworkers (who essentially nodded) and I made it happen:
 Logging Prism's decisions.
#323
Logging Prism's decisions.
#323
All right, be prepared.
TL; DR
- Prism can now log stuff from the negotiation.
- The negotiation and logging process can't make Prism crash anymore for any reason.
Long version
The following PR, in theory, implements logging for the negotiator. Practically, though, this PR is laying down the foundation for the logging for the future hosted version as well and hopefully start moving Prism's code in a different direction.
There were some main principles I've been keeping in mind while writing the code for this stuff:
- Prism should not process/format/react to the logs. Somebody else should do it; doing stuff on logs is usually slow and Prism should instead answer all the requests as fast as possible.
- The negotiation process in Prism is currently composed by numerous and nested function calls and last thing I wanted to do is to carry over this
loggerparameter in all the function and having to deal with it everywhere - The logging cannot be a singleton defined somewhere — because the logging instance will be provided externally (Prism Http Server, in this case)
- The logging process and the negotiation process should never make Prism crash. In any circumstance. I repeat, in ANY circumstances.
Let's now see how I've tamed them down.
- Use Pino. If you go on their website the write that "it's the fastest logger on the world" but you can ignore that, that was not the reason why I went with it. The main points were:
- It's included with fastify — and so we're not introducing a new dependency. We've been shipping it since forever.
- Pino does not include any way to process/alert/react to logs; it simply outputs the log statements as JSON on the stdout (or any stream you provide to it). It means that all the processing must be off process and I think this is great. It means that, by design, there's no way somebody can make messes with logs and do any action that's logging dependant. You can't break what's not even included.
So where's the log processing happening in our case? In the CLI. You can see from the code that, whenever the production environment is detected (or the -m flag is passed) the CLI will effectively use the cluster module to fork the process, run Prism Server and funnel its stdout logs back to the CLI, where Signale will pretty print them. When Prism will be hosted somewhere, we'll likely do the same.
In case you're running the things locally to write code and test the stuff, you'll see that the fork is avoided and all is done in process. This is done fundamentally because it's going to be way easier to debug stuff in a single process. This is exactly the same that Jest does with the --runInBand flag.
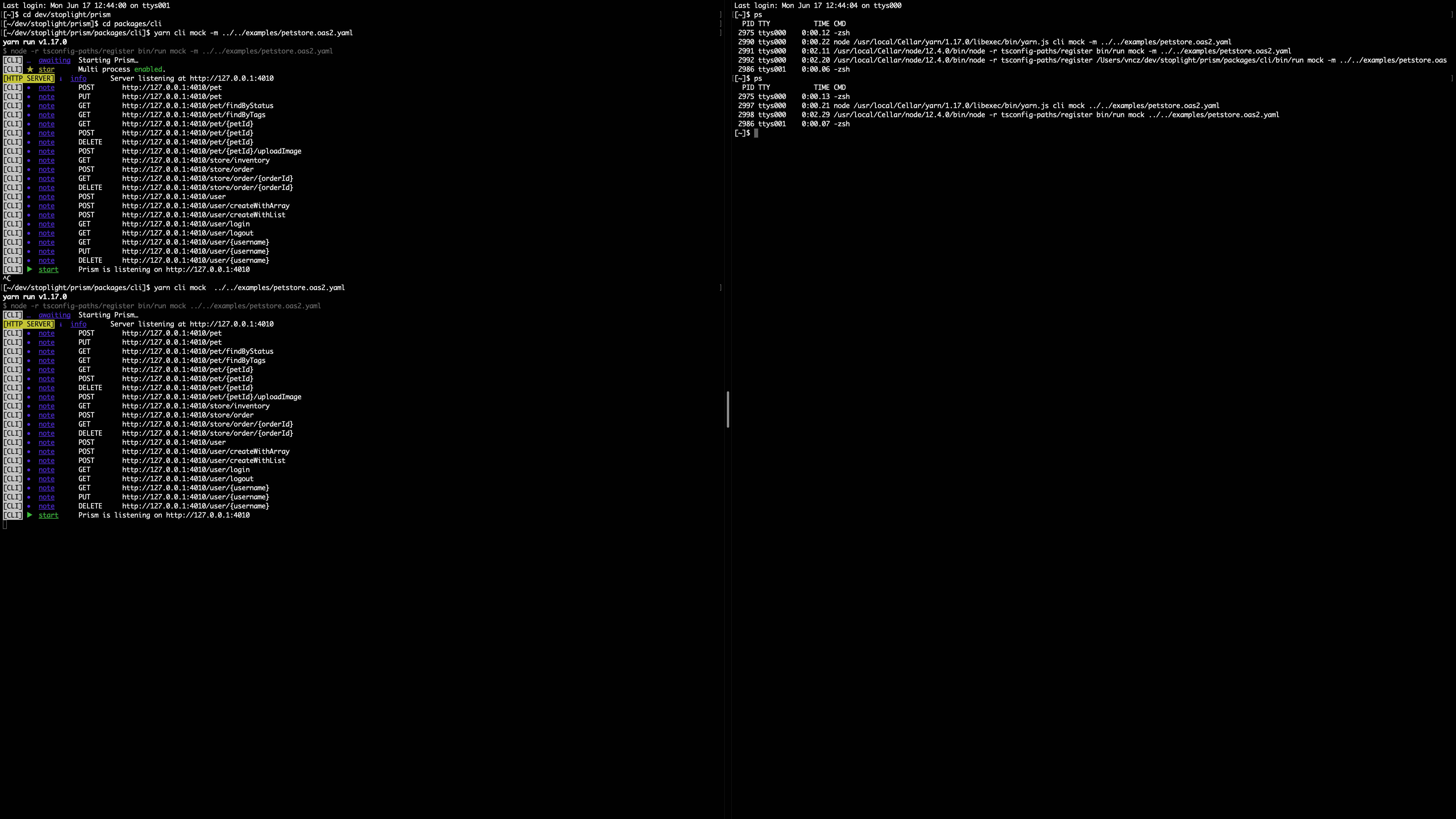
You can see from the image what when the -m flag is specified, you'll find an additional process with node running — this is exactly the forking happening.
Note: if NODE_ENV===production the forking is enabled by default, so that if you use the CLI in a Docker Environment you get what the production behaviour.
-
Inject the logger through currying. Thanks to the partial application I can basically write a function that takes the regular arguments which returns a function needing an additional dependency to run.
const negotiate = (arg1, arg2, arg3) => logger => { // real body }. For this, I've employedfp-ts's reader implementation, that allows me to do exactly that: write code that has regular arguments and returns something that will need a logger to be executed. By leveragingchainandmapmethod, intermediate functions can easily introspect and modify the result in the middle without having to worry about the logging presence. It'll be put as last step. Moreover, if one day we will want to make the Router start outputting logs as well — it's really easy. All we need to do is make the router spit up a Reader and chain it with the following one in the mocker. All good, profit. -
See point 2. With Currying I can pretend the inner functions will eventually have a logger, it's resolution is happening in a completely different npm package; this is important to understand why I could not simply have a shared instance to require from somewhere.
-
This happened as an effect of the reader. Since the logger in injected at the end, the traditional try catch in the middle of the code to decorate the errors does not work anymore. I could have workaround this but I decided instead to change the approach and make sure the negotiation and the logging process never throws exceptions. Therefore the code has been modified to use the
Eitherimplementation that's included infp-ts, which is not that hard to understand. If you check out theNegotiatorHelper.tsyou can see there are not that many changes and more importantly nested exceptions are now been flattened — which is good. Clearly there are 1-2 things that aren't that cool but I'm on all of them. In particular:- Jest should support wrapped helpers so I can remove my home made helpers https://github.com/facebook/jest/issues/8540
- A built-in
ReaderEithercould let me remove some nested maps. I'm quite sure @gcanti will make it happen soon
Outstanding points
- [x] Refactor
mock.tsto look a little bit more human - [x] Resolve the null-ness of
loggercomponent - [x] Understand whether we're logging enough or too much
- [x] CLI Readme Update
- [x] Deduplicate the testing helpers
- [x] General review and cleanup
SO-231
The PR is kind of big and although I would encourage you to check it out, I am pretty sure nobody will. Therefore, here's the TL;DR:
- I decided to put my
--verboseflag to 9000 and over-explain my intentions, how I executed them, what were the consequences, limitations and how we would move forward with that. - Some coworkers were confused by the terminology; people unfamiliar with the functor in general will think that
mapis only a thing for arrays and make up their noses when they see it applied somewhere else - A coworker was excited about the work and since he effectively was a little bit more familiar with this stuff, he helped the review and corroborated the benefits that I was trying to bring
- Different libraries and languages have different names for the same "operation". In the specific case, we had people confused by the
chainfunction because somewhere else is usually calledflatMaporbind - We had some people concerned about the general readability of the code (that's a funny thing to me but I was aware that people's brain needed to be rewired) and growing the contribution barrier
I took all the necessary time to address the comments; most of them were actually more questions and clarification rather than requests for changes. Most of them were easily resolvable once I would briefly explain the concept behind that (such as chain, map, fold). I took that as a good sign.
Then the conversation kind of stalled for some days until I decided to take control of the situation and risk it by merging the PR although not everybody approved it. I felt that in some cases it is better to do something and ultimately be wrong rather than not doing anything and then be wrong anyway. Nobody complained about it so it was official, we were starting to get the core of Prism functional.
Somebody was a little bit angry about it, but I also received a great feedback during one of our retrospectives:
The introduction of fp-ts in Prism makes me think we'll finally do something differently here.
In the next article we’ll see how, by continuing to expand fp-ts’s usage in Prism we started to get the first wins and return of the investment we did.

Top comments (1)
Excellent! This is how anyone should introduce any new paradigms or tool into the team’s ecosystem: slow and steady, then wham with the merge, with easy rollbacks and escape routes.