
Since Power Automate and other RPA technology took hold I believe that one of the top integration tools is now Outlook/email. Yes I know it's not a integration tool, but it to Power Automate, it just another API, with almost universal access (so many systems now allow reports to be scheduled and sent by email).
A common issue I see is how to get the data from the email, ideally it will be a .xlsx file, or maybe a csv (please not a .xls, thats been deprecated for 22 years and counting, all those software provides still sending .xls need to sort themselves out!), and quite often a simple html table. So how do you get the data from a html table into json so you can use it, luckily there are a few ways.
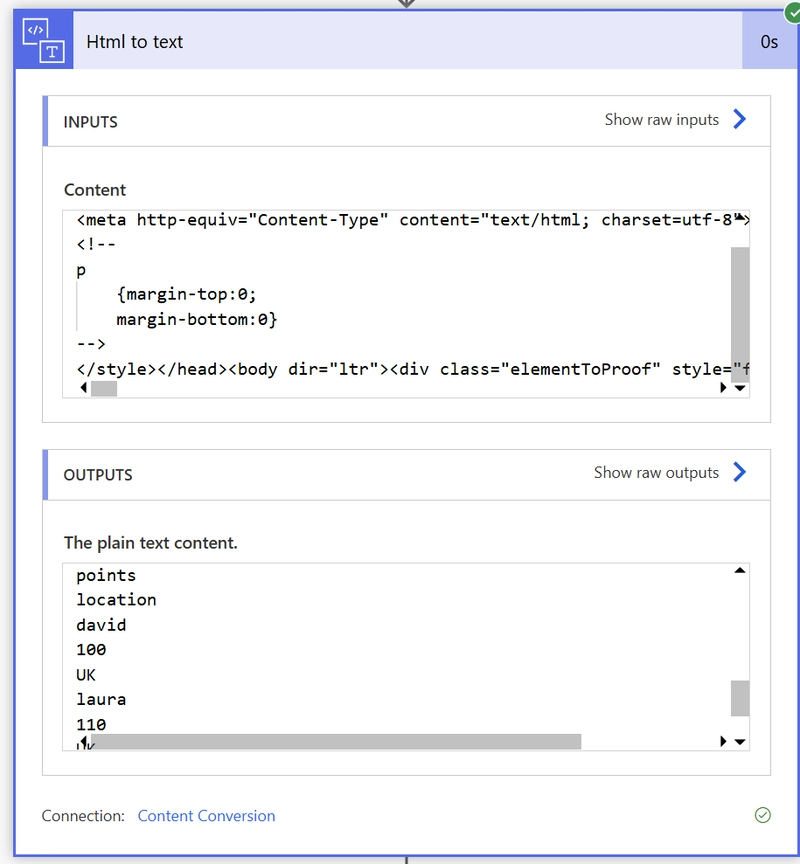
Sadly the out of the box html conversion only converts to plain text, not tabular data, but there are 3 ways I know of 😎
- The Easy But...
- Probably The Best Way
- The Cool Way
So let's dive in.
1. The Easy But...
The simplest way is our old friend string manipulation.
String manipulation is when you convert it to a string, then use functions like split() and replace() to extract the data you need before converting back
So in this way we are going to:
- Split the email body at
</tbody>or</table>so that we know the last row and cell is the end. We then use an array position to get the first of our split ([0]). - Next we replace all the end tags with nothing to remove them (
</tr>, </td>) - Finally we split by row (
<tr>) the create an array of rows (as we start at the row we don't have to worry about everything before)
split(
replace(
replace(
split(triggerOutputs()?['body/body'],'</tbody>')[0]
,
'</tr>'
,
''
)
,
'</td>'
,
''
)
,
'<tr>'
)
Next we need to remove the first row as it will be the headers, we use a filter to only return rows that start with <td> instead of <th>.
We then loop over every row and split by <td> to get an array of the cells. Once split we know that our array of cells will be:
0 - blank/null
1 - first column
2 - second column
3 - third column
and so on.
So the first column would be:
split(items('Apply_to_each_row'),'<td>')[1]
Finally we build the json object and add in the above for each key/value pair.
The final flow looks like this:

But as you may have guessed, there is a big but. This only works on simple HTML tables, anything within inline css or additional attributes it wont work. So if you table has an id, name, or was made in Outlook (look at that mess) it wont work, fortunately we have 2 more better ways.
2. Probably The Best Way
What's cool about HTML is its XML, so we can use the xml functions to manipulate and extract the HTML table.
In this approach we split the table straight to an array of cells, and then build the json object like above.
Before we start we have a small problem, when I say HTML is XML it is and it isn't. XML requires for any tag (<tag>) to have a open and close (<tag></tag>), and some cheeky HTML doesn't, the examples I deal with are:
- New Line
<br> - Horizontal Rule
<hr> - Images
<img src=""/> - MetaData
<Meta>
It also doesn't like for some reason.
So we remove them all, convert it to xml and then use xpath() to return an array of the cells.
xpath(
xml(
replace(
replace(
replace(
replace(
replace(
triggerOutputs()?['body/body']
,
'<meta '
,
''
)
,
'<br>'
,
''
)
,
' '
,
''
)
,
'<hr>'
,
''
)
,
'<img'
,
''
)
)
,
'//table/tbody/tr/td'
)
If you want to know more about XML functions in Power Automate check out this previous blog of mine: Power Automate - Handling XML
So we have an array of cells, how do we convert them back into rows to create the json object? Well.... with a Do Until loop 😎. What's cool about Do Untils is you can do any step (so not stuck to incrementing in ones, but in any amount). So now each loop we jump the number of columns. In my example there are 3 columns, so we increment in 3, and this is done by having a counter variable (iCounter).
We then user the HTML conversion action to remove HTML text (<td> </td>), and then create the object from them. This means for every column we need a conversion action, not the best but the only way.
Each conversion has the below expression, just with incrementing + 1.
base64ToString(outputs('Td_Array')[variables('iCounter')]?['$content'])

We base64ToString() because xpath returns the array in base64.
The whole flow looks like below:

There is one major drawback to this (not including the non-closing tags), and thats you have to hard code the columns again, and you could also add in it is very API heavy with big tables.
3. The Cool Way
If you read my blogs you know if I do something complex there will always be a Office Script in the mix, and here it is.
We can use the power of TypeScript do create the perfect converter, as this one has the benefits of being able to use Regex's, so it handles all of the above issues (inline attributes, non-closing tags, dynamic columns).
First we create a bunch of regexs to find the key tags but accept inline attributes.
const reTable = RegExp("<table[^>]*>","g");
const reTbody = RegExp("<tBody[^>]*>","g");
const reHeader = RegExp("<th[^>]*>", "g");
const reRow = RegExp("<tr[^>]*>","g");
const reCell = RegExp("<td[^>]*>", "g");
Next we do some string manipulation to get just the table and remove unnecessary tags like <tBody>, <thead>.
After we split it into our rows like before, we shift() the array to remove the first item which is always blank/white spaces/other HTML.
let aRows: string[] = sTable.split(reRow);
aRows.shift();
We now deal with the headers, first checking to see if the table is using header cells (<th>), and if not grabbing the first line.
let aHeaders=[]= aRows[0].split(reHeader)
if (aHeaders.length<2){
aHeaders = aRows[0].split(reCell)
}
aHeaders.shift();
Finally we loop over the rows and then loop over the headers, building the json object as a string. We pass the string back to the flow and get it to convert it with the json() function.
aRows.forEach( row =>{
if(row.trim().length>4 && !row.includes("<th>")){
let sRow="{"
aHeaders.forEach((header,index) =>{
sRow +=removeHTML(header) + ":'" +
removeHTML(row.trim().split(reCell)[index + 1])+"',"
})
sReturn += sRow.substring(0, sRow.length - 1) + "},"
}
})
The substring removes the last comma to make it a compliment json. There is also a reusable function called removeHTML(), this removes all of the tags in the HTML and trims any white spaces.
The whole Office Script is below.
function main(workbook: ExcelScript.Workbook, sHTML: string) {
const reTable = RegExp("<table[^>]*>","g");
const reTbody = RegExp("<tBody[^>]*>","g");
const reHeader = RegExp("<th[^>]*>", "g");
const reRow = RegExp("<tr[^>]*>","g");
const reCell = RegExp("<td[^>]*>", "g");
let sReturn="[" as string;
let sTable: string = sHTML.split(reTable)[1].split("</table>")[0];
sTable=sTable
.replace(reTbody,"")
.replace("<tbody>", "")
.replace("</tbody>","")
.replace("</thead>", "");
let aRows: string[] = sTable.split(reRow);
aRows.shift();
let aHeaders=[]= aRows[0].split(reHeader)
if (aHeaders.length<2){
aHeaders = aRows[0].split(reCell)
}
aHeaders.shift();
aRows.forEach( row =>{
if(row.trim().length>4 && !row.includes("<th>")){
let sRow="{"
aHeaders.forEach((header,index) =>{
sRow +=removeHTML(header) + ":'" +
removeHTML(row.trim().split(reCell)[index + 1])+"',"
})
sReturn += sRow.substring(0, sRow.length - 1) + "},"
}
})
return sReturn.substring(0, sReturn.length - 1)+"]" ;
}
function removeHTML(sHTML: string){
const reDiv = RegExp("<div[^>]*>", "g");
return sHTML.replace("</th>", "")
.replace("</tr>", "")
.replace("</td>", "")
.replace("</div>", "")
.replace(reDiv, "")
.trim()
}
The flow is super simple, pass the body and then convert the response from a string back to a json (you could also use a parseJson).

As you can see, no matter the problem there is always a way in Power Automate, and often more than 1 😎
The 3 working flows can be found in my GitHub repo here, and the script is also there but in this folder.
If you would like to get notified every new blog (I also do a few in the Power Platform Community), subscribe below

Top comments (0)