
Photo by Priscilla Du Preez on Unsplash
After version V8.5.9, V8 changed its old pipeline (composed of Full-Codegen and Crankshaft) to a new pipeline which uses two brand new compilers, the Ignition and TurboFan. This new pipeline is mostly why JS runs blazing fast nowadays.
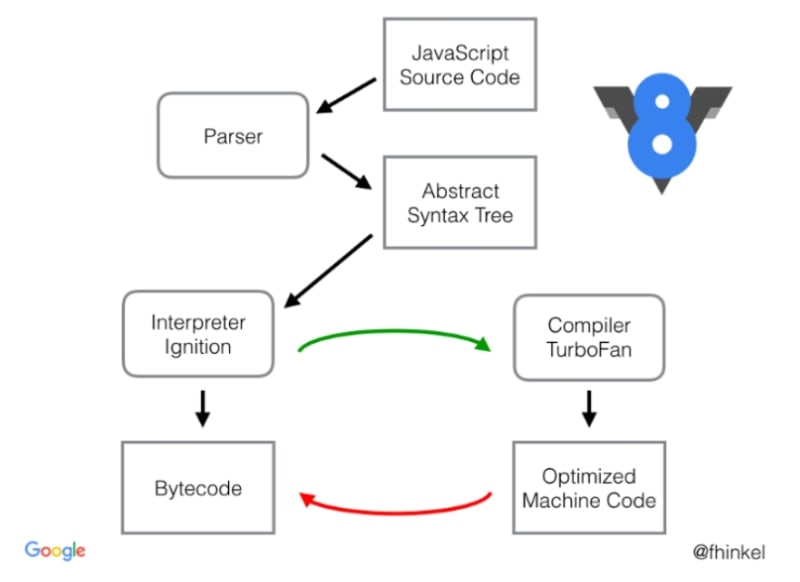
Basically, the initial steps have not changed, we still need to generate an AST and parse all the JS code, however, Full-Codegen has been replaced by Ignition and Crankshaft has been replaced by TurboFan.
Ignition

Ignition is a bytecode interpreter for V8, but why do we need an interpreter? Compilers are much faster than an interpreter. Ignition was mainly created for the purpose of reducing memory usage. Since V8 don't have a parser, most code is parsed and compiled on the fly, so several parts of the code are actually compiled and recompiled more than once. This locks up to 20% of memory in V8's heap and it's specially bad for devices with low memory capabilities.
One thing to notice is that Ignition is not a parser, it is a bytecode interpreter, which means that the code is being read in bytecode and outputted in bytecode, basically, what ignition does is take a bytecode source and optimized it to generate much smaller bytecode and remove unused code as well. This means that, instead of lazy compiling the JS on the fly, like before, Ignition just takes the whole script, parses it and compiles all at once, reducing compiling time and also generating much smaller bytecode footprints.
So in short. This old compiling pipeline:

Note that this is the step in between the old compiling pipeline we just saw, and this new compiling pipeline that V8 uses now.
Has become this:

Which means that the AST, which was the source of truth for the compilers, is now fed into Ignition which walks all nodes and generates bytecodes that is the new source for all compilers.
Essentially, what Ignition does is turn code into bytecodes, so it does things like this:
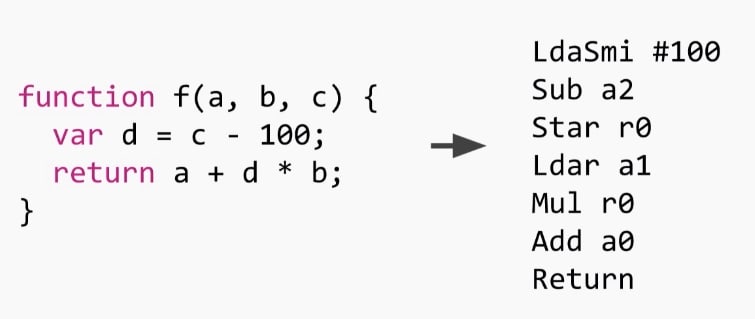
As you can see, this is a register-based interpreter, so you can see the registers being manipulated around function calls. r0 is the representation of a local variable or a temporary expression which needs to be stored on the stack. The baseline to imagine is that you have an infinite register file, since those are not machine registers, they get allocated onto the stack frame when we start. In this specific function there's only one register that's used. Once the function starts, r0 is allocated onto the stack as undefined. The other registers (a0 to a2) are the arguments for that function (a, b and c) which are passed by the calee, so they're on the stack as well, this means we can operate them as registers.
There's also another implicit register called accumulator, which is stored in the machine's registers, where all the input or output should go, this means the results of operations and variable loadings
Reading that bytecode we have these set of instructions:
LdaSmi #100 -> Load constant 100 into the accumulator (Smi is Small Integer)
Sub a2 -> Subtract the constant we loaded from the a2 parameter (which is c) and store in the accumulator
Star r0 -> Store the value in the accumulator into r0
Ldar a1 -> Read the value of the a1 parameter (b) and store into the accumulator
Mul r0 -> Multiply r0 by the accumulator and store the result also in the accumulator
Add a0 -> Adds the first parameter a0 (a) into the accumulator and stores the result in the accumulator
Return -> Return
We'll talk about bytecodes in depth in our next article
After walking the AST, the generated bytecode is fed one at a time to an optimisation pipeline. So before Ignition can interpret anything, some optimisation techniques like register optimisation, peephole optimisations and dead code removal are applied by the parser.

The optimisation pipeline is sequential, which makes possible for Ignition to read smaller bytecode and interpret more optimized code.
So this is the full pipeline before from the parser to Ignition:

The bytecode generator happens to be another compiler which compiles to bytecode instead of machine code, which can be executed by the interpreter.
Ignition is not written in C++ since it'd need trampolines between interpreted and JITed functions, since the call conventions are different.
It's also not written in hand-crafted assembly, like a lot of things in V8, because it'd need to be ported to 9 different architectures, which is not practical.
Rather than doing that stuff, Ignition is basically written using the backend of the TurboFan compiler, a write-once macro assembler and compiles to all architectures. And also, we can have the low level optimisations that TurboFan generates for free.
Turbofan

TurboFan is the JS optimizing compiler which, now, replaced Crankshaft as official JIT compiler. But it wasn't always like that. TurboFan was initially designed to be a very good webasm compiler. the initial version of TurboFan was actually pretty smart, with a lot of type and code optimisations that would perform very well in general JavaScript.
TurboFan uses what is called a Sea-of-Nodes representation (We'll talk about it in the next chapter, but there are reference links in the bottom) that alone increased the overall compiling performance of JavaScript code by a lot. The whole idea of TurboFan is to implement everything that Crankshaft already had, but also make possible for V8 to compile faster ES6 code, which Crankshaft did not know how to deal with. So TurboFan started as a secondary compiler only for ES6 code:
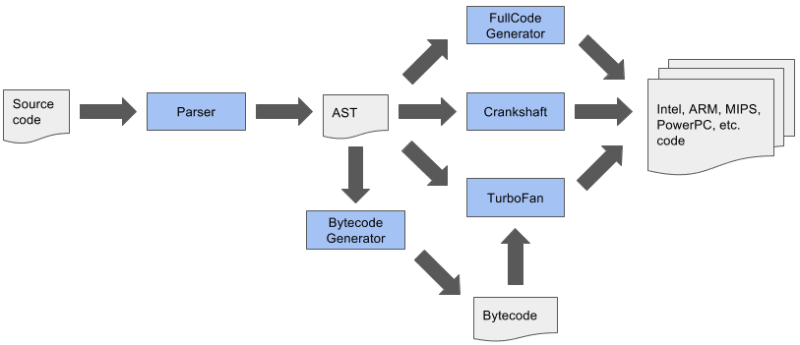
The whole problem with this, besides the technical complexity, is that the language features should be implemented in different parts of the pipeline and all those pipelines should be compatible with each other, including the code optimisations they all generated. V8 used this compiling pipeline for a while, when TurboFan couldn't actually handle all the use cases, but, eventually, this pipeline was replaced by this other one:

As we saw in the previous chapter, Ignition came to interpret the parsed JS code into bytecode, which became the new source of truth for all compilers in the pipeline, the AST was no longer the single source of truth which all compilers relied on while compiling code. This simple change made possible a number of different optimisation techniques such as the faster removal of dead code and also a lot smaller memory and startup footprint.
Aside of that, TurboFan is clearly divided into 3 separate layers: the frontend, the optimizing layer and the backend.
The frontend layer is responsible for the generation of bytecode which is run by the Ignition interpreter, the optimizing layer is responsible solely for optimizing code using the TurboFan optimizing compiler. All other lower level tasks, such as low level optimisations, scheduling and generation of machine code for supported architectures is handled by the backend layer - Ignition also relies on TurboFan's backend layer to generate its bytecode. The separation of the layers alone led to 29% less machine-specific code than before.

Deoptimisation cliffs
All in all, TurboFan was solely designed and created to handle a constantly evolving language like JavaScript, something that Crankshaft wasn't build to handle.
This is due to the fact that, in the past, V8 team was focused on writing optimized code and neglected the bytecode that came with it. This generated a few performance cliffs, which made runtime execution pretty unpredictable. Sometimes, a fast running code would fall into a case Crankshaft couldn't handle and then this could would be deoptimized and could run up to a 100 times slower than the former. This is an optimisation cliff. And the worst part is that, due to the unpredictable execution of the runtime code, it was not possible to isolate, neither solve this sorts of problems. So it fell onto developers' shoulders to write "CrankScript", which was JavaScript code that was written to make Crankshaft happy.
Early optimisation
Early optimisations are the source of all evil. This is true even to compilers. In benchmarks, it was proven that optimizer compilers were not as important as the interpreter. Since JavaScript code needs to execute fast and quickly, there's no time to compile, recompile, analyse and optimize the code before the execution.
the solution to this was out of TurboFan or Crankshaft scope, this was solved by creating Ignition. Optimizing the bytecode generated by the parser led to a much smaller AST, which led to a smaller bytecode which finally led to a much smaller memory footprint, since further optimisations could be deferred to a later time. And executing code a while longer led to more type-feedback to the optimizing compiler and finally this led to less deoptimisations due to wrong type-feedback information.

Top comments (7)
Thanks for this. I was about to ask how does V8 supports different CPU architecture if it generates byte code directly, and then I read the turbofan. This is the coolest part of v8 after reading.
also I have a question.
these assembly is not architecture specific right? Its generated from ignition and will be read again by v8? I was just wondering because I thought the syntax is lacking, I was used to
instruction source source/destinationanyway thanks for this. hope theres a next one.This is actually not assembly code. This is a mid-level code representation in bytecodes (there'll be an article just about this in the future), but this is generated by ignition to be read by turbofan and the rest of the pipeline
ahhh. thank you thank you. nice article. thank you for your hardwork
Great article sir but this led me to another question.
Do node.js and chrome literally uses same piece of software?
If so does that mean I can't run node.js without installing chrome?
I would really appreciate you answering. Have a great day.
Thanks for the comment!
Node.js does not use Chrome, Chrome is the whole browser with rendering engine, JavaScript engine and a lot of other moving parts. Node uses only V8, the same JavaScript engine as Chrome or Edge.
Vai sair na versão em português? Meu inglês ainda é fraco.
Vai sim! Me desculpe pela demora, os artigos são escritos originalmente em ingles, então eu demoro um tempinho para poder traduzir eles todos para o português, geralmente temos uma defasagem de 1 artigo.