I’ve recently been working on a personal project where I’ve decided to use and learn more about DynamoDB. While I’ve used Dynamo a bit for small things in the past, the majority of my past experience has been with relational databases, and it’s taken me some time to get my head around working with NoSQL.
What is DynamoDB?
DynamoDB is Amazon Web Services’ fully managed NoSQL database.
Unlike relational databases, which store their data in structured rows and columns, Dynamo data is stored in key-value pairs. This means that the data you store in Dynamo is unstructured compared to what you’d usually see in a relational database. The only schema that you have to define is your table keys: the partition key and the sort key. Beyond that, your data can be schemaless (although your application still has to know how to handle it).
My Mistake
In my project, I’m using Python and accessing Dynamo via the boto3 library. This is running on AWS Lambda. In my code, I have a data model, collection, which I needed to do basic CRUD (Create, Read, Update, Delete) operations on.
My code looked something like this:
Do you see my mistake?
With every database operation I was doing, I was re-initializing the
boto3resource and the Dynamo Table.
It was easy to do (especially with GitHub Copilot basically writing these functions for me), and I didn’t really think about it at the time. However, while reviewing some code, my fiancé, Myles Loffler, pointed out to me that this is actually an anti-pattern when working with boto3 clients, particularly on Lambda.
Note: While I hit this anti-pattern while working with Dynamo, due to the nature of the CRUD operations — you can run into it any time you’re re-initializing the same boto3 resource over and over!
How I Fixed It
Luckily, this was both easy to fix, and fixing it made my code better overall!
I created a new utilities file to handle my database connections and added the following functions:
Then, I refactored my CRUD functions to just use get_dynamo_table instead of using boto3 directly.
You may have noticed the use of global variables in my database utility. While this is often considered a bad practice, I used them based on the Lambda best practice that suggests taking advantage of execution environment reuse.
What Kind of Difference Did It Make?
This made four major differences to my code:
Performance
This is obviously the big one!
To test, I deployed two versions of the application, one with the old code and one with the new, and ran through some of the workflows that resulted in CRUD operations.
Here are some examples of traces through my application without this change applied to it. This action included deleting an item and a query:
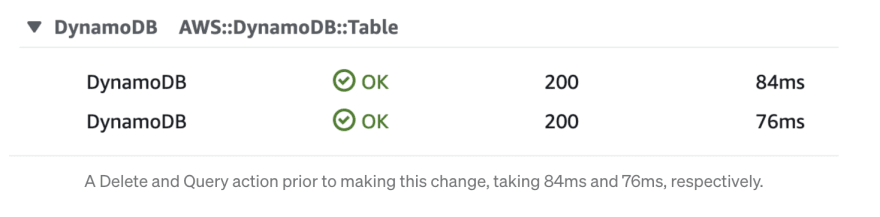
And here are traces of the same two actions (delete and query) through the application with this change applied:
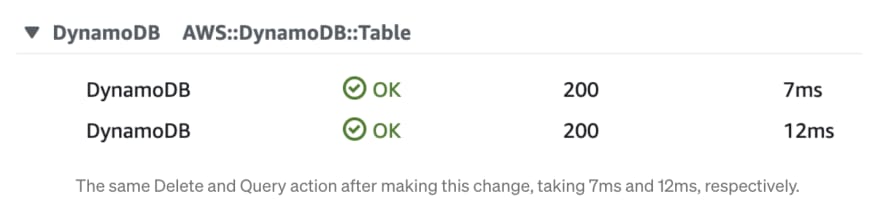
Although we’re only talking about fractions of a second, these delays add up over time! The application feels notably faster and more responsive after this change was applied.
Cleanliness
This approach is both easier to read and, in the long term, will definitely be less code in my project. I don’t have to import boto3 and access the environment variables whenever I need to access the database. There is a single function to access Dynamo now, so if I need to change something, I’ll only have to change it in one place.
Testability
The tests are cleaner too. Before, I had to mock boto3 in every location, which was also fairly complicated, as I was mocking the return value of a return value. Now I can just mock get_dynamo_table , which is a lot more straightforward and easy to read.
Reusability
The new functions in utils.db don’t care about the table name at all — it’s retrieved by the get_dynamo_table_name function in settings. As my project grows, this code is reuseable across other Lambdas that may use different Dynamo tables.
As I mentioned above, I’m fairly new to using Amazon’s DynamoDB — and I’m still learning!

Top comments (1)
It’s not only dynamodb. It’s with every client you create it makes sense to reuse them in subsequent lambda calls