At Sliplane.io, we’ve put together a tech stack that gets the job done — fast, reliable, and most importantly, easy to maintain and operate.
Here’s a quick rundown of what we’re working with, from frontend to backend and everything in between.
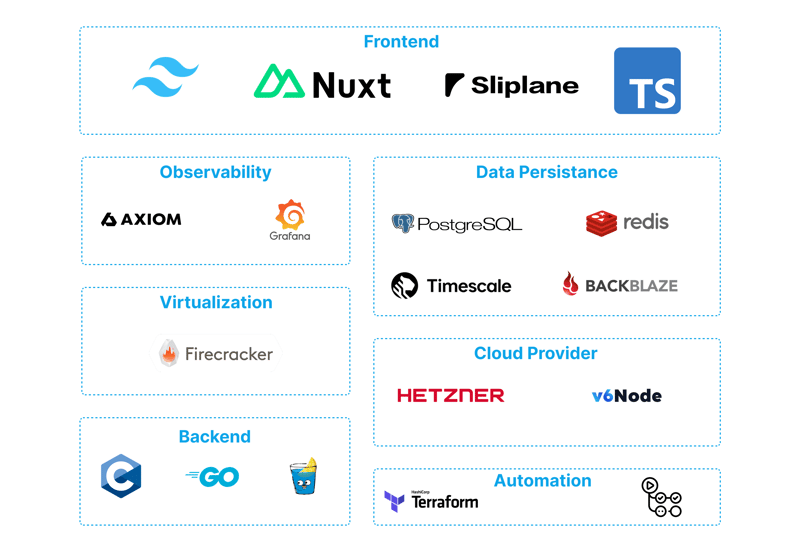
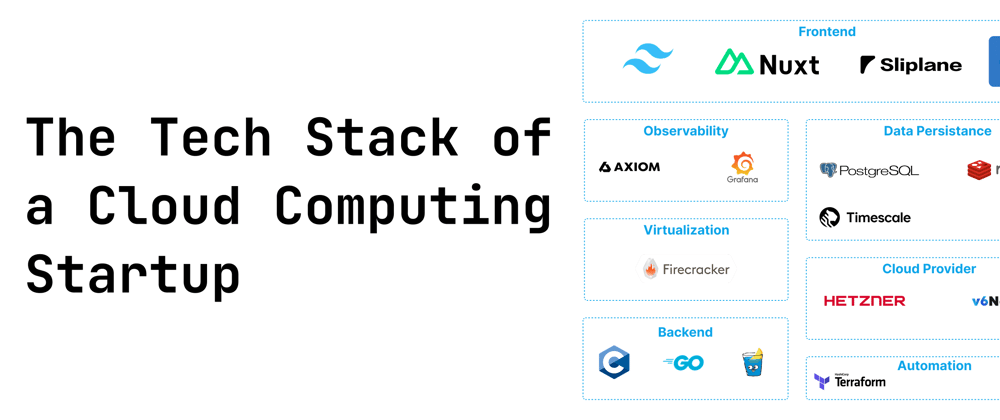
Frontend
For the frontend we're going a bit against the grain of current webdev trends and bet on Nuxt (of course with Typescript and Tailwind) as our framework of choice. This is mostly because Lukas (the co-founder) is a long-term Nuxt.js fan and sponsor! Of course, the frontend is completely hosted on Sliplane.io for proper dogfooding, with Cloudflare as a CDN in front because script kiddies like to test their DDOS scripts on us :).
Observability
To keep tabs on what’s happening, we use Axiom for logs and Grafana for dashboards and alerts. We pipe all of our logs from most services straight into Axiom and have some pre-defined filters there that help us understand whats going on. With Grafana we have a bunch of custom dashboards that help us triage issues, and more importantly, alert us if some metrics are looking off. Without Grafana, Sliplane.io could not exist!
Data Persistence
I (Jonas) am not the biggest fan of data management and database operations, so we try to keep this simple. Our main database is Postgres, with the Timescale extension for analytics stuff. Postgres and Timescale has been absolutely amazing so far. We've scaled far beyond what I thought would be possible and had to do basically 0 optimizations, even though our entire analytics stack with hundreds of millions of rows is all in Postgres! Oh and of course, Postgres is also hosted at Hetzner.
Redis handles caching to keep things quick, and we stash blobs like Backups (encrypted at rest of course) in Backblaze for cheap, dependable object storage.
Fun fact: At backblaze we pay more for S3 transactions (so API requests) than the storage. There is probably some optimization potential there 🫠
Backend
I've been writing Go for over 6 years, so picking Go as our main backend language was a no brainer, especially considering the great integrations into the general infra space. Most infra code is go, so that helps a lot. As a framework we use Go-Gin, but honestly we could also just use the native http lib. We also have a tiny part of code in C for some cheeky eBPF stuff we got running. YES, we could write that in Rust, but with eBPF the benefits are negligible and C was the first language I learned as a kid:)
Automation
We manage infrastructure with Terraform and lean heavily on GitHub Actions for CI/CD. Very simple but it works! Oh and a lot of bash scripts of course.
Cloud Providers
We run most of our stuff on Hetzner—cloud, bare-metal, even the DNS. It’s solid, doesn’t break the bank and we have a good relationship with them. For dev work, we’ve got some things on v6node to play around with.
Virtualization
For virtualization, we’re using Firecracker. It’s lightweight, secure, and lets us spin up micro-VMs without crazy overhead. It's pretty fun to play around with, so do it if you're interested in that kind of stuff!
Utils
Of course there are a bunch more tools that we use, some great, some not. Two notable ones are Crisp for customer support and AWS SES for sending out emails (we send out quite a lot of transactional emails!).
That’s the gist of our stack at Sliplane.io. It’s practical, it works, and it allows us to have great reliability with a tiny team. More to share down the road as we keep building!
Cheers,
Jonas

Top comments (23)
Sliplane looks very interesting - I'll give it a try. I have no end of sample apps with a Docker image.
As I mention in my profile, I'm Chief Technical Evangelist at Backblaze, and I noticed that you said that you're paying us more for API transactions than for storage, and:
There almost certainly is! There are a few ways that this can happen, often because of poorly written or poorly configured client software. In the Backblaze web UI, you can click into "Reports" and get some insight into what's happening. The culprit is usually one or more of "head object", in class B, or "list file names" or "list objects" in class C.
Many developers working with cloud object storage don't consider the fact that API calls are a limited/costly resource as they are developing their apps, and make repeated calls to head/list rather than caching the results. Also, layers of abstraction can mask what's happening under the covers. Repeated "stat" calls to get the attributes of what looks to the app like a local file can result in many redundant API calls.
Sometimes there's a simple fix - for example, Rclone has a
--fast-listflag (you can set theRCLONE_FAST_LISTenvironment variable so you don't have to use the flag with every call) that lets it work more efficiently with cloud object storage such as B2 and S3, but it isn't the default, since it can result in higher memory use.Earlier today I was on a call with a customer seeing lots of API call usage - their NAS sync software was making 15 head requests and about 1 list request per file each time it ran. Each list call can return up to 1,000 results, so there's no way this should be happening! I advised them to contact the NAS vendor to have them look into it.
Hah that’s cool, thanks for responding! Love backblaze btw, great product. The transactions all come from restic (backup tool, not sure if you’re familiar). Need to check if I can tune something there! But even if I can tune, the costs are still incredible low for now:)
Plus stripe for payments :-)
ohhh right
Amazing setup! Have you thought about the long-term scalability as your user base grows?
Thank you! Yea, a lot :D Had to learn a few "scale" issues the hard way already. There are some things in the stack that we are migrating away from because they broke down at an earlier scale than I imagined (fly.io for example, i could rant about them for days)
I am curious about the virtualization layer with firecracker. Do you integrate firecracker with kubernetes, or have you built your own custom orchestration system on top of firecracker?
0 kubernetes, our own orchestration!
Interesting! Would love to learn more about how you did that, and/or why you didn't go with kubernetes 😄
At my graduation project, we're building simple PaaS, and we decided to integrate firecracker with kubernetes so we get the full power of kubernetes.
This might be interesting to you (the guys sadly stopped working on it though) github.com/valyentdev/ravel/.
Our orchestrator is super lean and specific for what we need. Allows us to move faster (most of the time). Also just not the biggest fan of kubernetes :D
Great, thank you for the insights!
This is solid! One quick question—does Hetzner Cloud operate globally? Specifically, does it offer multiple deployment regions?
Thank you! Hetzner has locations in the US, Germany, Finland and Singapore. Some would call that global :D but were working on extending to more locations!
Would be amazing if you did a barebones abc on how to setup and get all those things working together. Even with something super simple like a posts list.
Something specific youre interested in that I could write about?:)
Yes, initially they didnt exist. Migrating would be relatively easy thanks to S3, but honestly the reliability has been very bad until now + I don't want backups in the same datacenter/location as the servers :)
Not using Kubernetes seems like a very weird & limiting decision. Nowadays even the learning curve isn't an excuse any more with all those ChatGPT & etc. & embedded directly into IDEs.
It’s the other way around actually. Using kubernetes for this kind of thing just doesn’t make a lot of sense. If you don’t believe me, railway and fly.io had the same realisation blog.railway.com/p/railway-v2
Kubernetes is the best automation platform for any workload so I think you just don't know it well enough. It needs to be "cooked just right" but when you do it you can never go back. I have the same impression from the post you link.
Quoting:
We spent almost all of 2022 trying to build “Railway on Kubernetes.” We already had an experience we knew users loved, so we tried to retrofit it onto the existing off-the-shelf technology. The “industry standard.” The stable bet.
The result was disastrous. It was overly complex. It was brittle. It never even made it into production. It burned out the engineer most passionate about the transition and almost killed the company. A total and unequivocal failure.
Migration to Kubernetes or bringing apps into it needs to be done by experienced seasoned Senior DevOps who has that experience. Only then the result is a well working platform with all the aspects & nuances taken care of. Me & me team are doing it on a regular basis with many companies.
“Kubernetes is the best automation platform for any workload so I think you just don't know it well enough.” possible, still a good enough reason:)
To complete, I recommend kiponos.io for realtime config. So you don’t restart any service when config changes
Some comments have been hidden by the post's author - find out more