
When creating Devsnap I was pretty naive. I used create-react-app for my frontend and Go with GraphQL for my backend. A classic SPA with client side rendering.
I knew for that kind of site I would have Google to index a lot of pages, but I wasn't worried, since I knew Google Bot is rendering JavaScript by now and would index it just fine
Oh boy, was I wrong.
At first, everything was fine. Google was indexing the pages bit by bit and I got the first organic traffic.

But somehow indexing was really slow. Google was only indexing ~2 pages per minute. I thought it would speed up after some time, but it wasn't, so I needed to do something, since my website relies on Google to index a lot of pages fast.
1. Enter SSR
I started by implementing SSR, because I stumbled across some quote from a Googler, stating that client side rendered websites have to get indexed twice. The Google Bot first looks at the initial HTML and immediately follows all the links it can find. The second time, after it has sent everything to the renderer, which returns the final HTML. That is not only very costly for Google, but also slow. That's why I decided I wanted Google Bot to have all the links in the initial HTML. You can find more in-depth information about that topic in this great article.

I was doing that, by following this fantastic guide. I thought it would take me days to implement SSR, but it actually only took a few hours and the result was very nice.
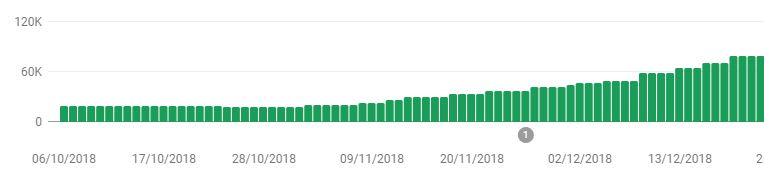
Without SSR I was stuck at around 20k pages indexed, but now it was steadily growing to >100k.
But it was still not fast enough
Google was not indexing more pages, but it was still too slow. If I ever wanted to get those 250k pages indexed and new job postings discovered fast, I needed to do more.
2. Enter dynamic Sitemap
With a site of that size, I figured I'd have to guide Google somehow. I couldn't just rely on Google to crawl everything bit by bit. That's why I created a small service in Go that would create a new Sitemap two times a day and upload it to my CDN.
Since sitemaps are limited to 50k pages, I had to split it up and focused on only the pages that had relevant content.
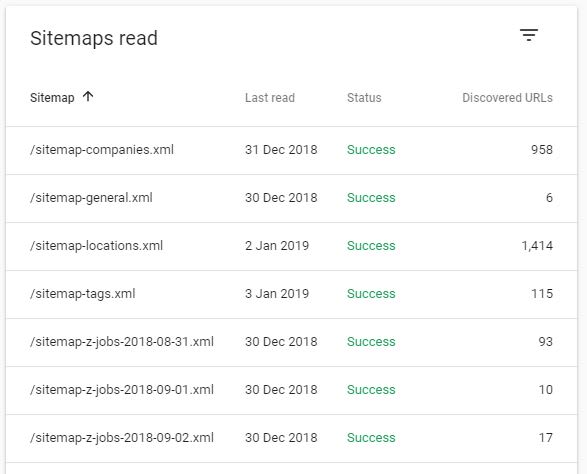
After submitting it, Google instantly started to crawl faster.
But it was still not fast enough
I noticed the Google Bot was hitting my site faster, but it was still only 5-10 times per minute. I don't really have an indexing comparison to #1 here, since I started implementing #3 just a day later.
3. Enter removing JavaScript
I was thinking why it was still so slow. I mean, there are other websites out there with a lot of pages as well and they somehow managed too.
That's when I thought about the statement of #1. It is reasonable that Google only allocates a specific amount of resources to each website for indexing and my website was still very costly, because even though Google was seeing all the links in the initial HTML, it still had to send it to the renderer to make sure there wasn't anything to index left. It simply doesn't know everything was already in the initial HTML when there is still JavaScript left.
So all I did was removing the JavaScript for Bots. Don't use this snipped as is without knowing what it does. See JSON-LD further below.
if(isBot(req)) {
completeHtml = completeHtml.replace(/<script[^>]*>(?:(?!<\/script>)[^])*<\/script>/g, "")
}
Immediately after deploying that change the Google Bot went crazy. It was now crawling 5-10 pages - not per minute - per second.
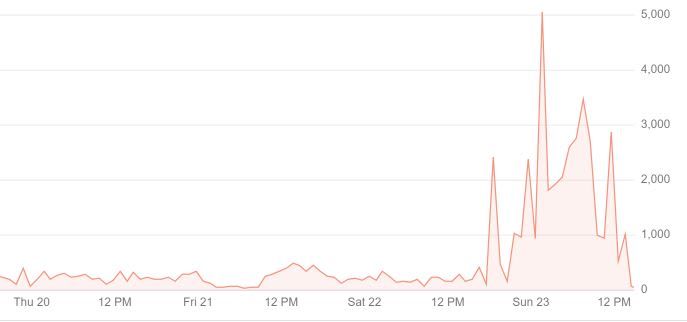


And this is the current result. Since I implemented the changes just recently, there are still a lot of pages that have been crawled, but haven't been indexed yet (grey bars). Nevertheless I'm more than happy with the result.
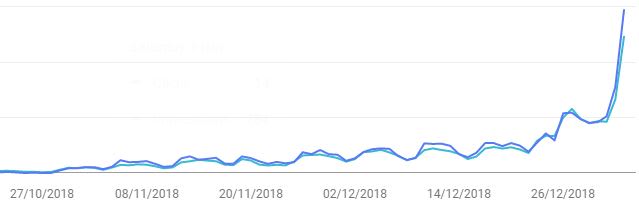
After having Google index all the pages, the performance went up a lot as well.
JSON-LD
Don't remove that! In my case JSON-LD is added after the snippet above. So be extra careful to not remove it.
Conclusion
If you want to have Google index a big website, only feed it the final HTML and remove all the JavaScript (except for JSON-LD of course).

Top comments (21)
Nice! It makes sense to bypass Web Rendering Service if HTML source has everything Google needs to understand your pages. Curious, have you seen positive impact on Google search traffic to your site after this?
Yeah, a huge one even. You see that last image? That's the traffic change. Today it's even more.
I used an alternative to SSR, I used prerender hub.docker.com/r/bgadrian/docker-p... as a hosted service (in a container).
At the first visit it caches the result and serves the HTML only to bots.
To speed things up (and have the cache ready when google bots arrive) I created this tool that visits all the pages of an website github.com/bgadrian/warmcache
As for the sitemap, you can create a lot of them and have a master Sitemap that links to the other ones: sitemap index file.
Thanks for sharing your experience!
There is a lot of misunderstanding about how Googlebot deals with JS, and even though they improved a lot in the last years, for big and/or fast changing websites depending on JS to display content and/or links is a very risky thing to do if SEO is a priority.
I noticed you used my image to illustrate Google's 2 waves of indexing, it would be nice if you link to the original article where you found it :) (christianoliveira.com/blog/en/seo-... )
Hey.. Of course! I loved the article an got a lot of information there. Will add a reference as soon as I'm home again.
Hey David, little help in this code..
if(isBot(req)) {
completeHtml = completeHtml.replace(/]<em>>(?:(?!<\/script>)[<sup>])</sup></em><\/script>/g, "")<br> } </p> <p>The function isBot , How are you detecting the bots with that? Can you please share the code of that function? </p> <p>I'm going to apply it for the static site and going to see how it works or non JS based website. </p> <p>Thanks in advance.</p>
Wow, I’ve never heard of turning off JS for bots. Can you think of any possible downside to this (assuming the site still works appropriately), like Google won’t penalize you or anything?
From what I understand, that's even how Google wants it. Here is an article from google itself about it.
I don't think Google wants to waste a lot of resources to render the JavaScript of a website if the HTML has already completely been rendered by the server.
Be extra careful with JSON-LD tho. You should not remove that:
"Make sure JSON-LD script tags are included in the dynamically rendered HTML of your content. Consult the documentation of your rendering solution for more information."
Great article, out of curiosity any reason why you didnt use a library like next.js as they offer full support for SSR?
Got quite a bit of experience with technical SEO and we used to avoid handing Google bot a different version as that could be seen as you are trying to manipulate the bot.
Obviously Google bot and its metrics are a black box so sometimes things are not as clear as one would like. Thanks 🙂
Since React's
renderToStringmethod already offers 95% of what I need to create SSR for my website, I felt like using some new library like next.js was just way too overkill.It would probably even have cost me more time, since I'd have to learn next.js first. This way it only took me a few hours to get SSR done and it's just a tiny and fast codebase doing all that.
As for the manipulation, as Google mentions in this article, it even promotes exactly that different handling of the Googlebot. I mean it's a really logical thing to do. They save tons of resources if you cut out anything unnecessary for the bot.
After playing around with the bot for some time I think Google just wants you to make it Google as easy as possible to crawl your site and rewards it greatly.
David, Can we able to use the same code for any type of website CMS? I mainly work on the Wordpress. The code has to be placed on the top of the head?
Thanks.
This snippet is something I implement server side, but you have to be very careful to not remove the JSON-LD when using it. Since I have no experience with Wordpress unfortunately I can't help you much. :-/
Not a problem, David. I'm planning to convert my whole site into HTML based on the static site generators.
Then that code you mentioned most likely to work :)
And also thanks for pointing out the JSON-LD part, I will paste the code below that.
Thank you, David.
where do i implement this code i own a wordpress website
if(isBot(req)) {
completeHtml = completeHtml.replace(/]<em>>(?:(?!<\/script>)[^])</em><\/script>/g, "")<br> } </p>
This snippet is something I implement server side, but you have to be very careful to not remove the JSON-LD when using it. Since I have no experience with Wordpress unfortunately I can't help you much. :-/
After the final tag /article if not using json in widgets.
As an experiment, I added this code to the first sidebar widget.
HI good morning,
Just curious about the code part. Does this code work as expected on wordpress? :)
I'm also implementing the same on the WordPress.
Thanks
Hey David, thank you for your post.
Could you please explain where did you get your 5th image from ? I can't find in in Google Search Console, is it somewhere else, like a Kibana or something ?
Of course. Those are custom statistics I generated from my Google Logs (Stackdriver). It displays the amount of time Googlebot hit my website within 30 Minutes of time.
Super awesome, thanks for sharing.
I'm going to try all of these. Thanks!
Awesome post! thank you!
I was wondering tho, one year later, do you still recommend doing it?