
Ok, here's the Regex you wanted for Day 2 of Advent of Code 2020
Things mentioned in this post: regex, operator chaining, named groups, XOR
Regex me up
In the previous part, I looked at a state-machine based solution to the challenge. State machines are fun. I use them a lot in robotics and in game development. But the much better solution to this particular problem is Regex. In this part, I will pursue a very compact regex solution.
A reminder of the format:
- number (low range)
- a dash
- number (high range)
- space
- a letter (the letter in question)
- colon
- space
- a string to validate
Regex has a ...possibly deserved reputation for being impenetrable for those studying it, but I think a lot has to do with how compact its notation is. I think regex is a lot easier to write than to read, so hopefully if I were to explain the process, it would be a bit easier.
Let me break down the pattern one step at a time:
number
So we need to match one or more digits in a row. In most regex flavours, we have a character class \d which matches any digit from 0 to 9. We can modify this \d with a quantity. There's a shorthand quantifier character + which means "one or more". So simply, \d+ means "one or more digits in a row". If we didn't use this shorthand character, we could also specify the exact number of characters we expect, so \d{1} would mean "exactly one digit", while \d{1,2} would mean "between one or two digits". We'll stick with \d+ for now.
a dash
Regex are basically a bunch of groups and literals. If we want to match a dash, we just write a dash -. As long as it's not inside anything else, it'll be treated as a literal character -.
another number
Same as before, we can use \d+ here. So far our regex looks like this: \d+-\d+ which would match things like 23-99 or 1-15.
a space
As with before, you can match spaces. It's a literal space character .
a letter
We need to match exactly one letter. In regex, we can make character groups. something like [abc] will match one character that is either a, b, or c. You can also make ranges. so [a-z] would match any lowercase letter between a and z. You can combine ranges too, so [a-zA-Z] means any lower or uppercase letter. But, there's shorthand too, and just like \d above is shorthand for [0-9] there is the shorthand \w which matches any letter or underscore (easy way to remember is that it's often the characters allowable for variable names in programming languages). Since we only need one of these, no quantifiers are needed.
a colon and a space
Again, we can use literal : here.
many letters*
We can use that old + quantifier with our \w class to match multiple letters. Our regex now looks like this:
\d+-\d+ \w: \w+
Proof that it works, we can use regex101 to check.

However, matching isn't the only thing we're doing. We need to also pull out these groups that are being matched, so that we can actually use them for validation. So the regex needs some braces to tell it what values should be extracted as groups:
(\d+)-(\d+) (\w): (\w+)
Hopefully for those unfamiliar with regex, this doesn't look too intimidating. If you're relieved, then let me make you less comfortable by showing you why regex has the bad reputation that it does.
Recall that I said \d was a shorthand for the [0-9] class; and + was a shorthand quantifier? Well let's say I didn't use any shorthand and rewrote the above longhand:
([0-9]{1,})-([0-9]{1,}) ([a-zA-Z_]): ([a-zA-Z_]{1,})
Suddenly less easy to read. Still not bad though, it gets a lot worse than this. Proof that it still works:
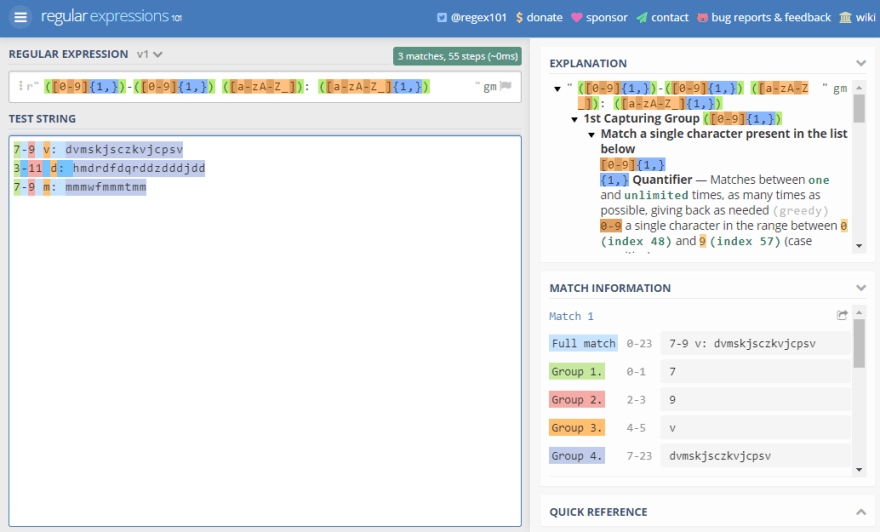
Implementing it
Python's regex library is just called re, and assuming we have on hand our entry value from before, using it works like this:
match = re.match('(\d+)-(\d+) (\w): (\w+)', entry)
print(match.groups())
Output
('9', '12', 't', 'ttfjvvtgxtctrntnhtt')
As you can see, where it took us numerous lines of code to implement a state-machine to parse the text, regex achieved it in a couple of lines.
At this point, we can take advantage of python's unpacking assignment, to stick the values that group() returns into variables:
match = re.match('(\d+)-(\d+) (\w): (\w+)', entry)
low_str, high_str, letter, password = match.groups()
Now, we can finally validate the password. The rules say that there is simply some number of letter inside password that is between low and high. Python already has a string method called count() that returns how many instances of a substring are in a string. so password.count(letter) is a number that needs to be between low and high to be valid.
Comparison chaining
Python has comparison chaining, which may surprise some people. It means that we can check if the count is between two values simply by doing:
if low <= password.count(letter) <= high:
In a lot of languages, this doesn't work, or yields weird values. For example if the expression was 4 > 3 > 2, some languages would evaluate 4 > 3 first, which returns "true", and then proceed to evaluate true > 3 which usually returns false.
Python however, does what you tell it to, the above code will indeed check that password.count(letter) is between low and high inclusively.
Which means... if we really wanted to code-golf our solution, we could squeeze everything we saw so far into three lines:
import re
data = [re.match('(\d+)-(\d+) (\w): (\w+)', line).groups() for line in open("input.txt").readlines()]
print("Valid passwords", sum(int(low) <= password.count(letter) <= int(high) for low, high, letter, password in data))
Nigh-on unreadable, but it's very compact.
While this is fine for simple exercises like this, this is far from acceptable in the real world.
No, like REALLY implement it
There's several things we should do to improve the readability, and importantly the maintainability of this code, and maybe a little bit of optimization.
The first thing I'm going to do is, since we need to re-use that regex a lot, is to "compile" it (a small optimization that Python can do)
pattern = re.compile("(\d+)-(\d+) (\w): (\w+)")
This means later I can just do:
match = pattern.match(entry)
The second thing I'm going to do is use "named groups", a unique feature of Python's regex, where we can give names to the group, and Python will output a dictionary instead of a tuple. This in theory makes it harder to make a mistake because you mixed up the order of the tuple.
pattern = re.compile('(?P<low>\d+)-(?P<high>\d+) (?P<letter>\w): (?P<password>\w+)', entry)
print(pattern.match(entry).groupdict())
Output
{'low': '9', 'high': '12', 'letter': 't', 'password': 'ttfjvvtgxtctrntnhtt'}
It makes the regex longer and less readable, but makes the return value handling a bit more robust.
The third thing is I'm going to put everything relating to this password in its own class so that it's nice and self-contained, and unit tests can be written against it, to make sure it can handle all the edge-cases and do the expected error handling.
class Password:
pattern = re.compile("(?P<low>\d+)-(?P<high>\d+) (?P<letter>\w): (?P<password>\w+)", entry)
def __init__(self, string: str):
extracted = Password.pattern.match(string)
groups = extracted.groupsdict()
self.low = int(groups["low"])
self.high = int(groups["high"])
self.letter = groups["letter"]
self.password = groups["password"]
def is_valid(self) -> bool:
return self.low <= self.password.count(self.letter) <= self.high
Note the use of the class variable for the pattern. There are some pros and cons of this that I won't go into right now.
Also note the python type hinting. This is useful to have
Exception Handling
Python has some quite good exception handling. While some programming philosophies say that you should not use exceptions (after all, if you're going to add exception handling, you should just deal with it), the reality is that python pushes you quite strongly to use exception handling, and most internal libraries will raise exceptions, so it's usually not an option to not use them.
In our case, there's one big exception to handle, which is if the regex doesn't match. We need to update our code a bit:
class PasswordGeneralError(exception):
def __init__(self, message):
self.message = message
super().__init__(self.message)
class PasswordFormatError(PasswordGeneralError):
pass
class Password:
pattern = re.compile("(?P<low>\d+)-(?P<high>\d+) (?P<letter>\w): (?P<password>\w+)", entry)
def __init__(self, string: str):
extracted = Password.pattern.match(string)
if not extracted:
raise PasswordFormatError("Password line does not match pattern")
groups = extracted.groupsdict()
self.low = int(groups["low"])
self.high = int(groups["high"])
self.letter = groups["letter"]
self.password = groups["password"]
def is_valid(self) -> bool:
return self.low <= self.password.count(self.letter) <= self.high
The code now, in the event of no match (extract() returns nothing), will raise a PasswordFormatError exception, which can be caught elsewhere.
We can now run the password checker on one entry:
Password(entry).is_valid()
This will return True if entry was a valid password, and False otherwise.
File handling
While the Password class can deal with a single password, we need more code to consume a whole input file. For this, we can write anther class, here shown with exception handling as we want to catch when validate raises an exception, and inform the user useful information such as what line of the input file had a problem.
class PasswordFileParseError(PasswordGeneralError):
def __init__(self, message, line):
self.message = f"{message} on line {line}"
super().__init__(self.message)
class PasswordChecker:
def __init__(self, file):
self.file = file
def count_valid(self) -> int:
total = 0
with open(self.file) as file:
for idx, line in enumerate(file):
try:
valid = self.validate(line)
except PasswordFormatError as err:
raise PaswordFileParseError("Could not validate", idx) from err
total += int(valid)
return total
@staticmethod
def validate(line) -> bool:
return Password(line).is_valid()
Now in the case of a malformed line, an error is raised that includes input file line numbers.
Note that I've had both exceptions inherit the PasswordgeneralError exception. This makes it easier to catch both exceptions at once, though does lead to the phenomena of exception bloat, where you end up with too many custom exceptions.
The final usage is now simply:
checker = PasswordChecker("input.txt")
print("Number valid", checker.count_valid()
The Challenge Part 2
In part 2, the password validation rules change. Where before we expect the letter to appear in the password between low and high times; now the numbers are character positions (1-indexed), and the letter is expected to appear in only ONE of the two character positions.
Since we have our classes written, it's only necessary to change the is_valid() function. This could be done in one of several ways, depending on the circumstance, you could just edit the code. You could create a child class of Password and override the is_valid() method. You could monkey-patch a fix in (if in an emergency).
Whichever way that happens, the code that was previously:
def is_valid(self) -> bool:
return self.low <= self.password.count(self.letter) <= self.high
is now:
def is_valid(self) -> bool:
return (self.password[self.low-1] == self.letter) != (self.password[self.high-1] == self.letter)
Here we are using basically a boolean XOR operation to ensure that we have either one of the positions matching, but not both.
Onward!

Top comments (3)
When I read in the Named Groups into Python 3.7, I get an error: TypeError: unsupported operand type(s) for &: 'str' and 'int'
Any guidance with this error?
that doesn't seem like a named groups error, it seems like you've tried to & a string and an int at some point. Check that your types are all correct
I'm not sure where the & is introduced. I even tried your code copy and pasted into the IDE. But what I did notice and change to get the code working is used re.match instead of re.compile. Not sure why, still early in learning Python, but the following worked:
pattern = re.match('(?P\d+)-(?P\d+) (?P\w): (?P\w+)', entry)
print(pattern.groupdict())
Thanks for the help and this series. Even on Day 2 and it's been extremely helpful.