
The Problem
We have three tables: SalesPerson, Company, and Orders. Each table contains different types of information related to a salesperson's sales. The challenge is to find out the names of all the salespersons who did not have any orders related to the company named "RED".
Let's take a look at an example to better understand the problem:
Example 1:
Input:
SalesPerson table:
+----------+------+--------+-----------------+------------+
| sales_id | name | salary | commission_rate | hire_date |
+----------+------+--------+-----------------+------------+
| 1 | John | 100000 | 6 | 4/1/2006 |
| 2 | Amy | 12000 | 5 | 5/1/2010 |
| 3 | Mark | 65000 | 12 | 12/25/2008 |
| 4 | Pam | 25000 | 25 | 1/1/2005 |
| 5 | Alex | 5000 | 10 | 2/3/2007 |
+----------+------+--------+-----------------+------------+
Company table:
+--------+--------+----------+
| com_id | name | city |
+--------+--------+----------+
| 1 | RED | Boston |
| 2 | ORANGE | New York |
| 3 | YELLOW | Boston |
| 4 | GREEN | Austin |
+--------+--------+----------+
Orders table:
+----------+------------+--------+----------+--------+
| order_id | order_date | com_id | sales_id | amount |
+----------+------------+--------+----------+--------+
| 1 | 1/1/2014 | 3 | 4 | 10000 |
| 2 | 2/1/2014 | 4 | 5 | 5000 |
| 3 | 3/1/2014 | 1 | 1 | 50000 |
| 4 | 4/1/2014 | 1 | 4 | 25000 |
+----------+------------+--------+----------+--------+
Output:
+------+
| name |
+------+
| Amy |
| Mark |
| Alex |
+------+
Explanation:
According to orders 3 and 4 in the Orders table, it is clear that only salespersons John and Pam have sales to the company named "RED". Therefore, we report all the other names in the SalesPerson table.
The Solution
To solve this problem, we can utilize SQL's JOIN operations and the DISTINCT keyword. The DISTINCT keyword allows us to eliminate duplicates and retrieve only unique salesperson IDs who made sales to the "RED" company. We use JOIN operations to combine rows from two or more tables based on a related column between them. Let's explore three different approaches and discuss their performance.
Source Code 1
This solution uses a Common Table Expression (CTE) to select distinct names of salespersons who have made sales to the "RED" company. Then, it selects names from the SalesPerson table that are not in the CTE.
WITH red_sales AS (
SELECT DISTINCT s.name
FROM SalesPerson s JOIN Orders o ON s.sales_id = o.sales_id JOIN Company c ON c.com_id = o.com_id
WHERE c.name = 'RED')
SELECT name
FROM SalesPerson
WHERE name NOT IN (SELECT name FROM red_sales)
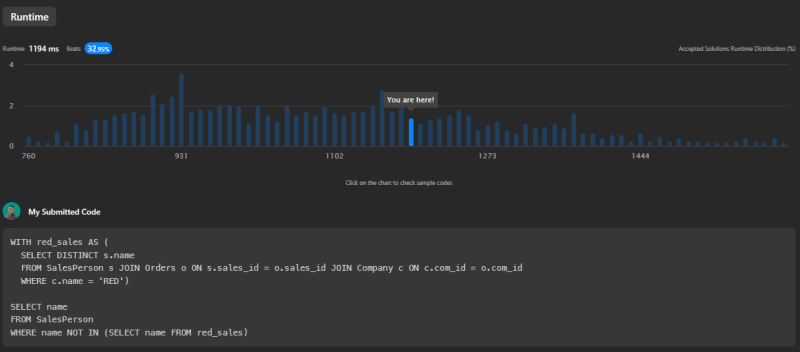
The first source code has a runtime of 1194ms and beats 32.95% of submissions.
Source Code 2
This solution uses a subquery with LEFT JOIN to combine information from the Orders and Company tables. It then filters out salespersons with sales to the "RED" company using the NULL check.
SELECT s.name
FROM SalesPerson s
LEFT JOIN (
SELECT o.sales_id
FROM Orders o
JOIN Company c ON c.com_id = o.com_id
WHERE c.name = 'RED'
) red_orders ON s.sales_id = red_orders.sales_id
WHERE red_orders.sales_id IS NULL;
The second source code has a runtime of 1691ms and beats 5.3% of submissions.

Source Code 3
This solution also uses a Common Table Expression (CTE) but selects distinct salesperson IDs instead of names. It then performs a LEFT JOIN between the SalesPerson table and the CTE, and filters out salespersons with sales to the "RED" company using the NULL check.
WITH red_sales AS (
SELECT DISTINCT s.sales_id
FROM SalesPerson s JOIN Orders o ON s.sales_id = o.sales_id JOIN Company c ON c.com_id = o.com_id
WHERE c.name = 'RED')
SELECT name
FROM SalesPerson s LEFT JOIN red_sales r ON s.sales_id = r.sales_id
WHERE r.sales_id IS NULL
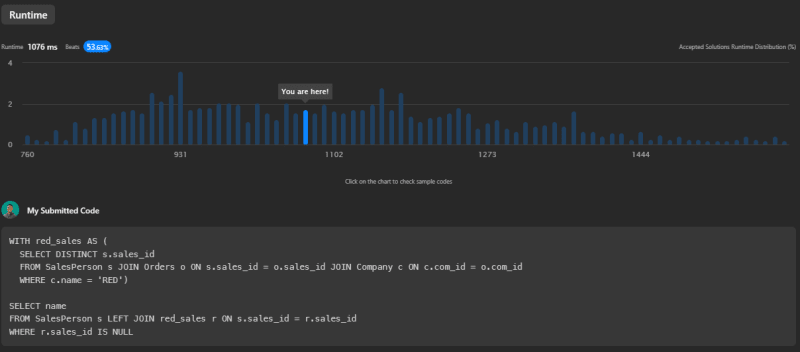
The third source code has a runtime of 1076ms and beats 53.63% of submissions.
Conclusion
While all three solutions solve the problem, the first and third solutions are more efficient than the second one. The third solution is the most efficient of all, as it beats over 50% of other submissions in terms of runtime. However, all three solutions highlight the power of SQL joins and subqueries/CTEs when working with multiple tables.
The choice between these solutions depends on your specific requirements and the SQL engine's optimization. In general, it's a good idea to understand and try different approaches to find the most effective solution for your specific scenario.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (2)
CTE works well in this task. I also used it here.
I work with CTEs because I really hate subqueries 😁
They look similar but CTEs offer more reusability, improved readability, and potential performance benefits, while subqueries are self-contained and generally used for one-time operations within a query.