
The Problem
This problem involves two tables, Users and Rides.
Table: Users
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
In this table, id is the primary key. Each row contains the id and the name of a user.
Table: Rides
| Column Name | Type |
|---|---|
| id | int |
| user_id | int |
| distance | int |
In this table, id is the primary key. Each row contains the id, the id of the user who traveled the distance, and the actual distance traveled.
The task is to write an SQL query to report the distance traveled by each user. The result should be returned in descending order by distance traveled. If two or more users traveled the same distance, they should be ordered by their name in ascending order.
Explanation
Consider the following input data:
Users table:
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Alex |
| 4 | Donald |
| 7 | Lee |
| 13 | Jonathan |
| 19 | Elvis |
Rides table:
| id | user_id | distance |
|---|---|---|
| 1 | 1 | 120 |
| 2 | 2 | 317 |
| 3 | 3 | 222 |
| 4 | 7 | 100 |
| 5 | 13 | 312 |
| 6 | 19 | 50 |
| 7 | 7 | 120 |
| 8 | 19 | 400 |
| 9 | 7 | 230 |
Based on this data, the expected output is:
| name | travelled_distance |
|---|---|
| Elvis | 450 |
| Lee | 450 |
| Bob | 317 |
| Jonathan | 312 |
| Alex | 222 |
| Alice | 120 |
| Donald | 0 |
The Solution
We'll discuss four different SQL approaches that use various types of JOIN operations and handle NULL values. Each approach has its strengths and weaknesses in terms of readability, scalability, and execution speed.
Source Code 1
This method uses a LEFT JOIN operation from Users to a subquery on Rides that groups rides by user_id and sums up the distances. The ISNULL function replaces missing sum_distance (for users without rides) with 0.
SELECT
u.name,
ISNULL(r.sum_distance, 0) [travelled_distance]
FROM Users u LEFT JOIN (
SELECT
user_id,
SUM(distance) [sum_distance]
FROM Rides
GROUP BY user_id
) r ON u.id = r.user_id
ORDER BY
r.sum_distance DESC,
u.name
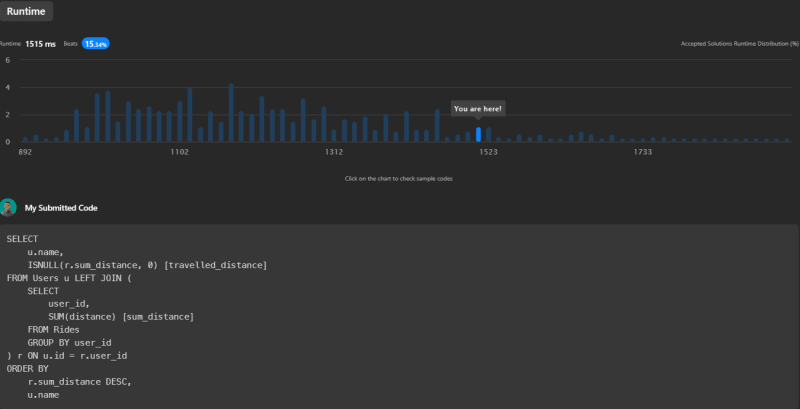
This solution's runtime is 1515ms, beating 15.34% of submissions on LeetCode.
Source Code 2
The second approach is similar to the first, but with a RIGHT JOIN operation instead. The right join can provide slightly better performance when the rides data is larger than the users data.
SELECT
u.name,
ISNULL(r.sum_distance, 0) [travelled_distance]
FROM (
SELECT
user_id,
SUM(distance) [sum_distance]
FROM Rides
GROUP BY user_id
) r RIGHT JOIN Users u ON u.id = r.user_id
ORDER BY
r.sum_distance DESC,
u.name
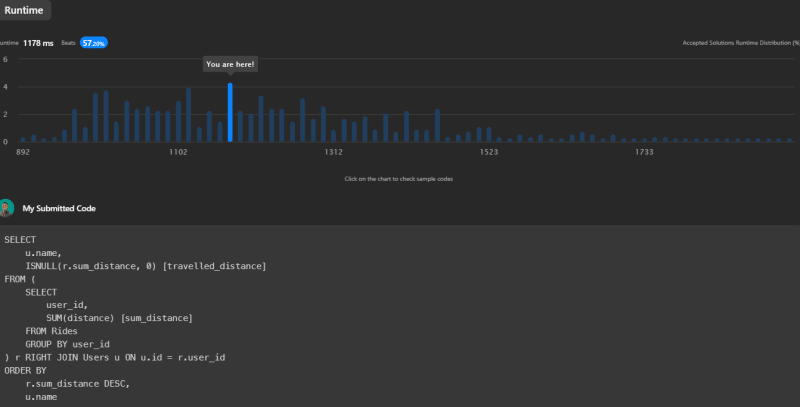
This solution's runtime is 1178ms, beating 57.20% of submissions on LeetCode.
Source Code 3
The third approach uses a window function SUM() OVER (PARTITION BY user_id). This aggregates the distance for each user_id within the subquery before joining to the Users table.
SELECT
u.name,
ISNULL(r.sum_distance, 0) [travelled_distance]
FROM (
SELECT DISTINCT
user_id,
SUM(distance) OVER (PARTITION BY user_id) [sum_distance]
FROM Rides
) r RIGHT JOIN Users u ON u.id = r.user_id
ORDER BY
r.sum_distance DESC,
u.name
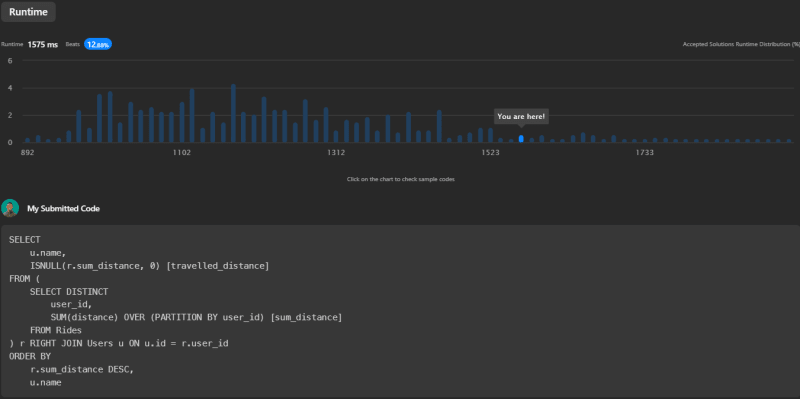
This solution's runtime is 1575ms, beating 12.88% of submissions on LeetCode.
Source Code 4
The fourth solution is similar to the third, but with a LEFT JOIN operation, providing an alternative approach to joining the data.
SELECT
u.name,
ISNULL(r.sum_distance, 0) [travelled_distance]
FROM Users u LEFT JOIN (
SELECT DISTINCT
user_id,
SUM(distance) OVER (PARTITION BY user_id) [sum_distance]
FROM Rides
) r ON u.id = r.user_id
ORDER BY
r.sum_distance DESC,
u.name
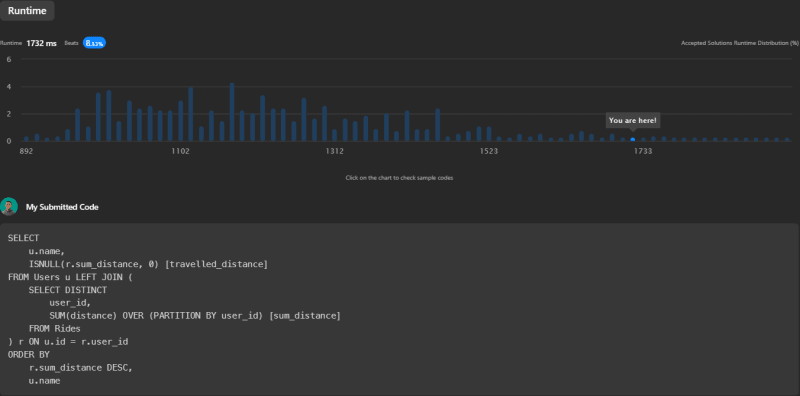
This solution's runtime is 1732ms, beating 8.33% of submissions on LeetCode.
Conclusion
Each solution provides a valid answer to the problem with varying performance metrics on LeetCode.
In terms of LeetCode performance, the best to worst solutions are: Source Code 2, Source Code 1, Source Code 3, and Source Code 4. However, it's worth noting that in real-world scenarios, the performance could vary based on the specific RDBMS, database structure, and data volume.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (0)