
Check out the updated version here
Introduction
It took me just three episodes to become inconsistent in my writing schedule. It has to be a record of some sort. To keep me motivated though I decided to spend the season back in Italy, so that I desperately needed to practice some English.
Well it's not entirely true: I am passing the season here because of food. As usual, this leads me to this article's topic: caching.
Readers right now are probably divided into two groups: the one knowing the famous joke about caching and the others. For both of you here's a curated list of tremendously sad variations of it.
Needless to say, I find all of them hilarious.
Either way, this piece is going to be part of a Christmas series about caching techniques. I am about to cover active caching (as in, what I can do to cache without suffer too much) and passive caching (as in, how to stick with browser cache and similarities).
This article is the first in the Active Caching part.
What is this about?
Do you still wonder what has food to do with caching? You'd better do, else I need to seriously improve my cliffhangers skills.
Example: Christmas Dinner
Let's start with a simple out-of-IT problem. It's Christmas eve and you're planning to arrange a mouthwatering dinner for you friends and family. For the sake of the argument we're going to use one traditional Italian Christmas recipe: "il capitone"1.
Let's start cooking. First thing in the list of the ingredients is the eel. You call your favourite fish shop, you get your fish delivered. Second item, extra-virgin olive oil. You call your favourite farm, order a bottle of oil and you get that delivered. Third, lemon...
You can see by yourself how inconvenient this is, don't you? What you start doing then is buying in advance and storing stuff in a more convenient place, closer to where you actually use it, to make the access to these ingredients more efficient. Let's call this place cupboard.
Once you realize you can store things at home, you might be tempted to call the delivery person just once to collect all the ingredients not only for Christmas but also for New Year's Eve's dinner. So when you are at the fish shop, you buy the eel and the king prawns which you are actually planning to prepare a week later.
After a couple of days, the funky smell killing any living being in the area makes you realize that probably prawns are now expired and you should have prepared them fresh.
Well, caching has exactly the same kind of problems and perks: we usually cache items to save some computations, time or to avoid calling uselessly an external data source, but we should be extremely careful about expiration of entries because they can eventually get to an inconsistent (and very smelly) state down the line.
Caching patterns
I am late buying Christmas presents. SHOW ME THE CODE.
As usual, let me introduce some jargon2 which will help us in communication before diving into the patterns (maybe strategies is a better suited word here).
These are the participants:
- Client needs data (either fresh or from the cache);
- Data Access Component is called to get non-cached entries (e.g., HTTP Client, ORM...);
- Cache Layer stores cached entries (e.g., Memory, Local Storage...);
- Resource Manager communicates with the Cache Layer.
In our previous example, these roles are mapped this way:
- Client is you;
- Data Access Component is the delivery person;
- Cache Layer your cupboard;
- Resource Manager someone so kind to administer resources in your cupboard.
Caching involves both reading (using the ingredients) and writing (storing the ingredients), so categorization follows accordingly. In this article we'll speak about reading techniques.
Reading strategies:
- Cache Inline
- Cache Aside
Writing strategies:
- Write Through
- Write Behind
- Write Around
Warning
Unfortunately naming convention for these patterns is not that consolidated, so you can find them under different names.
To get an understanding of how does work and why we should use them, we will analyse the following scenarios for all the aforementioned patterns:
- cached entry is present and valid (Cache Hit);
- cached entry is missing or invalid (Cache Miss).
Disclaimer
As usual, we are tackling these strategies in isolation for sake of simplicity. In real world, those techniques are combined to get the best out of them.
Cache Inline (aka Read Through)
The reason for this name is that in this pattern the Client is never responsible of calling the Data Access Component directly, but instead it delegates the responsibility of knowing whether a cached entry is enough or a fresh entry is required to the Resource Manager.
Resource Manager then sits in line between Client and Data Access Component.
Cache Miss
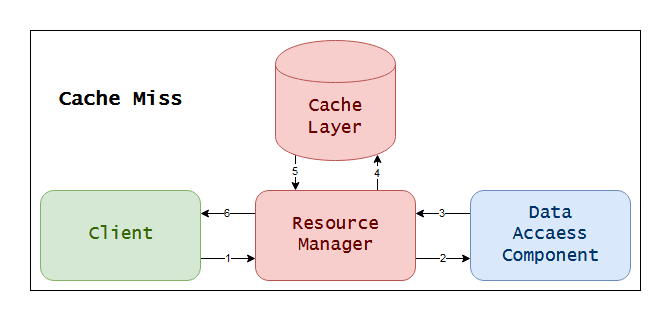
Following the numbers on the arrows, you should easily get a grasp of what's going on here:
1) Client asks Resource Manager for data;
2) Resource Manager gets no cached entries from cache, so it calls Data Access Component;
3) Resource Manager gets data, stores it and then returns it to Client.
Cache Hit
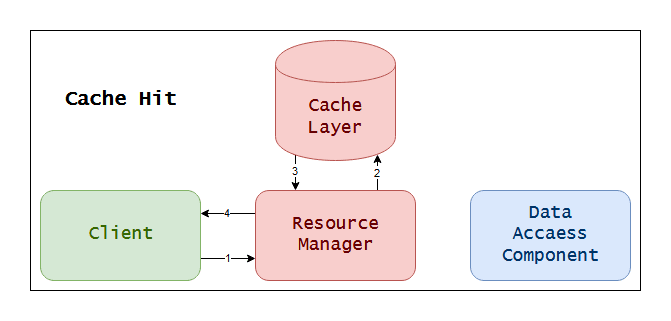
As you can see, using cache here is reducing the number of steps, hence the strategy is actually working!
Rationale
From a caching standpoint, this approach makes sure that we are caching only data we actually use. This is usually called lazy caching. This approach also promotes splitting responsibilities across different components, how can it have drawbacks?!
Well, unfortunately this is the case :(
The first issue is of course that, when you are in a Cache Miss scenario, the request has to do a longer trip before getting to the Client, making the first request actually slower than if we didn't have cache at all.
One way of dealing with this is doing a cache primer: when the system starts we pre-populate the Cache Layer so we'll always be in a Cache Hit case. Obviously this will make our caching mechanism not-so-lazy. As always, what's best depends on the actual scenario.
The second drawback is that, since data is cached only once (on Cache Miss) data can become quickly stale.
Again, this is not the end of the world: as for food, you can set expiration for entries. It is usually called TTL (namely Time To Live). When entries are expired, Resource Manager can call again the Data Access Component and refresh the cache3.
Cache Aside
As opposed to Cache Inline, Cache Aside will make the Client responsible of communicating with Cache Layer to understand if a Cache Entry is needed or not.
The pseudo code for this behaviour can be as easy as:
class Client {
CacheLayerManager cacheLayerManager;
DataAccessComponent dataAccessComponent;
getResource() : Resource {
const resource = this.cacheLayerManager.getResource()
return !resource
? this.dataAccessComponent.getResource()
: resource
}
}
Cache Miss

You can follow what's going on here by looking at the pseudo code above. As you can see, responsibility of calling Data Access Component is now in the Client and the Cache is actually... aside.
Cache Hit
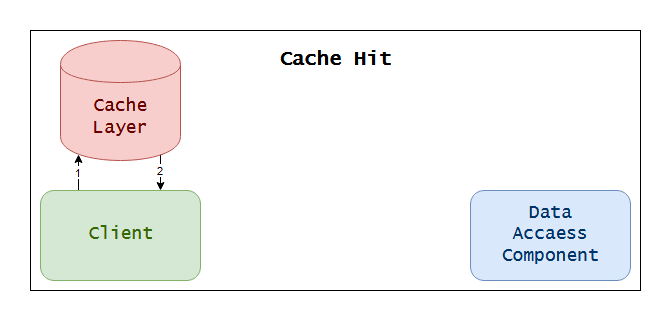
Again the trip here is shorter, so the pattern is actually working.
Rationale
This technique, as Cache Aside, is a lazy caching technique, unless we want to do a cache primer. Also, exactly as with Cache Aside, there is the problem of stale data, but again that problem can be tackled with TTL.
So, why should anyone go for Cache Aside over Cache Inline?
Since the Client now is responsible of communicating directly with the Cache Layer, when the Resource Manager fails, we pay a penalty only on the first request - when we go through the Cache Miss path -, making our system on the whole more robust.
Also, having removed the dependency between what we cache and what we get from Data Access Component, we could potentially have two different kind of model: a Model, which is representing what we get from Data Access Componentm and CachedModel representing what we cache.
This will indeed widen the spectrum of what you can achieve with cache: you can, for example, hydrate or transform cached data to gain on performance on multiple operation with just one cached entry.
Let's give an example of this.
Suppose you are serving a list of bank transactions you get from this AwesomeBankAPI. Your application is supposed to expose two different endpoints: getAllTransactions and getPayments. Of course AwesomeBankAPI does not expose any filtering function. What you could do is storing the the list of all the transactions on the first call to any of those endpoints.
From this point on, if the call is towards getAllTransactions, you return the list as is. If the call is towards getPayments you will take the whole list from cache (rather than calling AwesomeBankAPI again) and you just need to do the filtering on your end.
Code or it never happened
You can find a more detailed version of these examples here
shikaan / design-patterns
Examples of usage of design patterns in real life code
design-patterns
Examples of usage of design patterns in real life code
These are the reference resources for this series of articles
The example I am showing here is written in Node. It's a simple application meant to communicate with XKCD to fetch latest comics.
CacheLayer in this example is represented by a simple Map. I am using a CacheManager to deal with it, so that if you want to experiment with a real caching engine (like redis, or memcached) you can do that without much effort.
The DataAccessComponent is represented by a simple XKCDClient which exposes (in a Vanilla JavaScript fashion...) only a getLastComics method.
The other component is indeed ResourceManager which is being used only in the inline-caching example.
Since all these components are eventually the same, I just created two different clients sharing and using them in different ways, based on the strategy we want to follow.
The Cache Inline example is about requesting twice the same resource (namely, last three XKCD comics), but the second time the request is way faster. This is because we are not doing any cache-primer, so the first time we are actually calling XKCD API, the second time we are retrieving information from the cache.
The Cache Aside example instead, shows how powerful can be caching when we want to request resources which can calculated from what we already have. In this specific example, we are fetching last five comics from XKCD and then we are fetching only last two. The second call of course is not calling the API.
The main difference here is then that we are using the cache to get a resource we didn't have before, rather than using CacheLayer to get something we already fetched.
Again, those two strategies can (and usually do) live together. If you want to play a bit with these examples, you might try to make the ResourceManager from the first example a bit smarter so that it can either use the entries as they are (hence, what's already in the repo) or it can try to extract the required info from CacheLayer and decide whether calling the API or not.
Final words
This closes the first episode of this Christmas special (yes, as TV shows).
As you might have noticed I am trying to keep this shorter and easier than usual, so you can easily follow without your laptop when you are hallucinating because of Christmas-sized food portions.
As always, if you have any feedback (the thing is too simplified, you miss my memes, I suck at naming things), please drop a comment and make this better together :D
Until next time!
1. Pretty much anywhere else in Italy people eat meat for Christmas. I am from a messed up place where eating a giant eel should symbolize victory of Good against the Evil in the shape of a snake...
2. Unfortunately there no standard jargon here, so I had to make up these names. If you have any suggestions to improve them, please tell me (:
3. Knowing what is the right expiration date for every entry is something between wisdom and black magic. Most likely a lot of errors and trials (or experience, if you wish) will guide in choosing the best TTL for your case

Top comments (4)
Your articles are amazing, keep writing! I've been following what you're posting several month now, and it's always a pleasure to read your contributions to dev.to 😁
Thank you Nans! I mean it :)
great post! Hi man, where can I find more resources on caching? I appreciate that. :D
Let me link you the articles from where I took the names. They cover (from different perspectives and different degrees of completeness) pretty much the same I did here:
These are all articles about Caching in web development, not in general. Caching algorithms and, in general, caching outside web development have a different set of concerns I didn't talk about in this article. You can find some more information on the topic here:
Last one is easier to tackle in my eyes. There was also a very good resource called "Functional caching something" I can't recall and I am not able to find anymore. I will edit this comment if I find it