
Table of Content
- Introduction
- Recognizing web scraping opportunities
- Key components of a scraping project
- Packaging and Deploying your scraper
- Example Scraping Project with Python
- Example Scraping Project with Go
- Conclusion
Introduction
The web we all know and love is a huge pool of unstructured data, usually presented in the form of pages that can be accessed through a web browser. Web scraping seeks to harness the power of this data by automating it's extraction using well selected tools of choice, to save us time and effort. In this article, I will guide you through some of the steps involved in writing web scrapers to tame the beast. The concepts explained are language agnostic but since I am transitioning from the dynamically typed joyous Python syntax to the rigid static Go syntax, this article will explain with examples from both sides. It then rounds off by giving a brief description of two projects written in Python and Go respectively. The projects in question achieve very different goals but are all built on this awesome concept of web scraping.
You will learn the following:
- Recognizing web scraping opportunities
- Key components of a scraping project
- Packaging and Deploying your scraper
🚩 A lot of the code snippets shown in this article will not compile on their own, as most times I will be making reference to a variable declared in a previous snippet or using an example url, e.t.c
Recognizing web scraping opportunities
There is tremendous data online in the form of web pages. This data can be transformed from unstructured to structured data to be stored in a database, used to power a dashboard, e.t.c.
The trick to recognizing web scraping opportunities is as simple as having a project that requires data which is available on web pages, but not easily accessible through standardized libraries or web APIs.
Another indicator is the volatility of the data i.e how frequently the data to be scraped updates or changes on the site.
A strong web scraping opportunity is usually consolidation.

Consolidation refers to the combination of two or more entities. In our case refers to the merging of data obtained from different sources into one single endpoint. Take for instance, a project to build a dashboard for displaying major disease statistics in West Africa. This project is a major undertaking and will usually involve several processes, including but not limited to manual data collection. Let us assume however that we have access to multiple websites, each having some small part of the data we need. We can scrape all the websites in question and consolidate the data into one single dashboard while saving time and effort.
Some caveats exist however, one being that some websites have terms and conditions barring scraping, especially for the purpose of commercial use. Some sites resort to blacklisting suspicious IP addresses that send too many requests at too rapid a rate as it may break their servers.
Key components of a scraping project
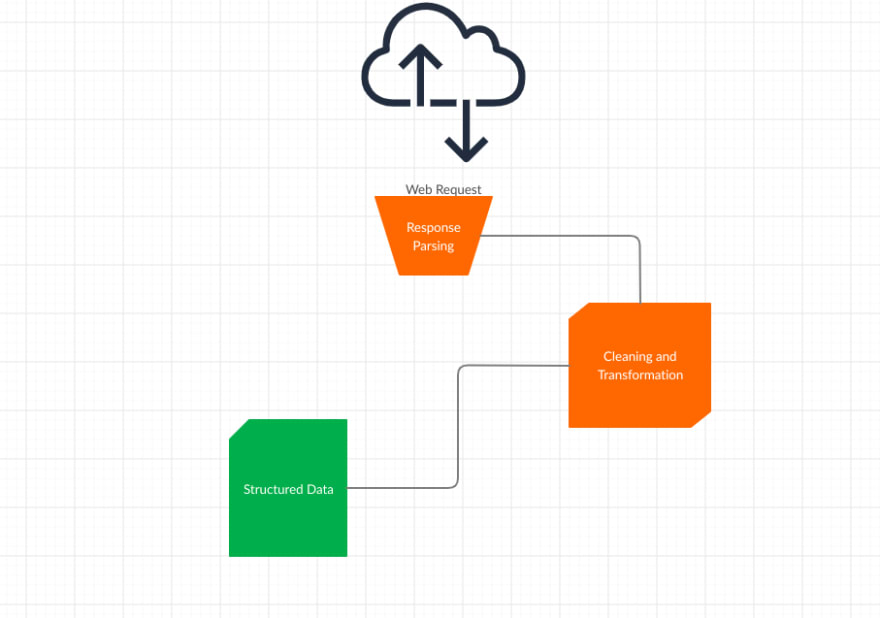
There are some persistent components in every web scraping project:
- Manual Inspection
- Web Request
- Response Parsing
- Data Cleaning and Transformation
Manual Inspection
To successfully create a web scraper, it is important to understand the concepts of HTML pages. A website is a soup containing multiple moving parts of code. In order to extract relevant information, we have to inspect the web page for the pieces of relevance. Manual inspection is first carried out before anything just to get a general feel of the information on the page.
To manually inspect a page, right click on the web page and then select "Inspect". This allows you peer into the soul or source code of the website.
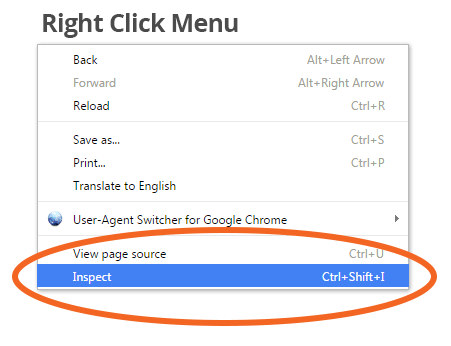
On clicking "Inspect", a console should pop up. This console lets you navigate and see the corresponding HTML tag for every information displayed on the page.

Web Request
This involves sending a request to a website and receiving the response. The request being can be configured to receive html pages, get files, set retry policy, e.t.c. The corresponding response received contains a lot of information we might want to use such as status code, content length, content type and response body. These are all important information that we then proceed to parse during the Response Parsing stage. There are libraries to achieve that in Python (e.g requests) and Go (e.g http)
Here is an implementation in Python
"""
Web Requests using Python Requests
"""
import requests
from requests.adapters import HTTPAdapter
# simple get request
resp = requests.get("http://example.com/")
# posting form data
payload = {'username':'niceusername','password':'123456'}
session = requests.Session()
resp = session.post("http://example.com/form",data=payload)
# setting retry policy to 5 max retries
session.mount("http://stackoverflow.com", HTTPAdapter(max_retries=5))
Here is the corresponding implementation in Go
/**
Web Requests using Go net/http
**/
package main
import "net/http"
func main(){
// simple get request
resp, err := http.Get("http://example.com/")
// posting form data
resp, err := http.PostForm("http://example.com/form",
url.Values{"key": {"Value"}, "id": {"123"}})
}
Unfortunately, net/http does not provide retries, but we can make use of third party libraries e.g pester
/** Retry Policy with pester **/
package main
import "github.com/BoseCorp/pester"
func main() {
client := pester.New()
// set retry policy to 5 max retries
client.MaxRetries = 5
resp, _ := client.Get("http://stackoverflow.com")
}
Response Parsing
This involves extracting information from the web page and still goes hand in hand with manual inspection mentioned earlier. As the name suggests, we parse the response by making use of the attributes provided by the response e.g the response-body, status-code, content-length, e.t.c. of which HTML which is contained in the response-body is usually the most laborious to parse, assuming we were to do it ourselves. Thankfully, there are structured stable libraries that help us parse HTML easily.
<!--- Assume this is our html -->
<html>
<body>
<p>
This is some
<b>
regular
<i>HTML</i>
</b>
</p>
<table id="important-data">
<tr>
<th>Name</th>
<th>Country</th>
<th>Weight(kg)</th>
<th>Height(cm)</th>
</tr>
<tr>
<td>Smith</td>
<td>Nigeria</td>
<td>42</td>
<td>160</td>
</tr>
<tr>
<td>Eve</td>
<td>Nigeria</td>
<td>49</td>
<td>180</td>
</tr>
<tr>
<td>Tunde</td>
<td>Nigeria</td>
<td>65</td>
<td>175</td>
</tr>
<tr>
<td>Koffi</td>
<td>Ghana</td>
<td>79</td>
<td>154</td>
</tr>
</table>
</body>
</html>
For Python, the undeniable king of the parsers is BeautifulSoup4
import requests
from collections import namedtuple
from bs4 import BeautifulSoup
TableElement = namedtuple('TableElement', 'Name Country Weight Height')
request_body = requests.get('http://www.example.com').text
# using beautiful soup with the 'lxml' parser
soup = BeautifulSoup(request_body, "lxml")
# extract the table
tb = soup.find("table", {"id": "important-data"})
# find each row
rows = tb.find_all("tr")
table = []
for i in rows:
tds = i.find_all("td")
# tds would be empty for the row with only table heads (tr)
if tds:
tds = [i.text for i in tds]
table_element = TableElement(*tds)
table.append(table_element)
# print first person name
print(table[0].Name)
For Go, there is no undisputed king of parsing in my opinion, but my immediate favourite has come to be Colly. Colly combines the work of net/http into it's library, so it can perform both web request and parsing
package main
import (
"strconv"
"fmt"
"github.com/gocolly/colly"
)
type TableElement struct {
Name string
Country string
Weight float64
Height float64
}
func main() {
// table array to hold data
table := []TableElement{}
// instantiate collector
c := colly.NewCollector()
// set up rule for table with important-data id
c.OnHTML("table[id=important-data]", func(tab *colly.HTMLElement) {
tab.ForEach("tr", func(_ int, tr *colly.HTMLElement) {
tds := tr.ChildTexts("td")
new_row := TableElement{
Name: tds[0],
Country: tds[1],
Weight: strconv.ParseFloat(tds[2], 64),
Height: strconv.ParseFloat(tds[3], 64),
}
// append every row to table
table = append(table, new_row)
})
})
// assuming the same html as above
c.Visit("http://example.com")
// print first individual name
fmt.Println(table[0].Name)
}
Data Cleaning and Transformation
If somehow scraping the html tags gave you the final form of the data you are looking for then 🎉 , your work is majorly done. If it is not, then the next part is usually very integral and involves rolling up your sleeves and doing some cleaning and transformation. Text coming from within tags is usually messy, unnecessarily spaced and might need some regular expression magic to further extract reasonable data.
"""
Extracting Content Filename from Content-Disposition using Python regex
"""
import re
# assume we have a response already
content_disp = response["Header"]["Content-Disposition"][0]
filename_re = re.compile('filename="(.*)"')
filename = re.match(filename_re, content_disp)[0]
print(filename)
# Avengers (2019).mp4
/**
Extracting Content Filename from Content-Disposition using Go regex
**/
package main
import (
"regexp"
"fmt"
)
func main() {
re := regexp.MustCompile(`filename="(.*)"`)
content := response.Header["Content-Disposition"][0]
filename := re.FindStringSubmatch(content)[1]
fmt.Println(filename)
// Avengers (2019).mp4
}
Furthermore, to clean data while easily melting, pivoting and manipulating its rows and columns, one could make use of Pandas in Python and it's Go equivalent Gota
import pandas as pd
# using the previous tables variable which is a list of TableElement namedtuples
df = pd.DataFrame(data=tables)
print(df.head())
""" Console output
Name Country Weight Height
0 Smith Nigeria 42 160
1 Eve Nigeria 49 180
2 Tunde Nigeria 65 175
3 Koffi Ghana 79 154
"""
package main
import (
"github.com/go-gota/gota"
"fmt"
)
func main(){
// using the previous tables variable which is a slice of TableElement structs
df := dataframe.LoadStructs(tables)
fmt.Println(df.head())
}
/** Console output
Name Country Weight Height
0 Smith Nigeria 42 160
1 Eve Nigeria 49 180
2 Tunde Nigeria 65 175
3 Koffi Ghana 79 154
**/
Refer to this awesome article on data cleaning with Pandas.
Packaging and Deploying your scraper
Packaging
This is all dependent on the use case of your scraper. You can determine your use case by asking questions like:
- Should the scraper stream data to another endpoint or should it remain dormant until polled?
- Are you storing the data for usage at a latter time?
They will guide you into selecting the proper packaging for your scraper.
The first question helps you consider the scraper as either a webservice or a utility. If it is not a streaming scraper, you should consider using it as a library or Command Line Interface(CLI). Optionally you can decide to build a Graphic User Interface(GUI) if you are into that sort of thing. For CLI, I would suggest Python's argparse and ishell for Golang. For creating cross platform desktop GUI, PyQt5 for Python and Fyne for Golang should suffice
NOTE 📝 : If you are setting up a streaming type scraper especially, you may have to apply a few tricks such as rate limiting, ip and header rotation, e.t.c so as not to get your scraper blacklisted.
The second question helps decide whether to add a database into the mix or not. View Python psycopg and Go pq to be able to connect to a PostgresQL database
I have been able to rely on Flask for spawning simple Python servers and using them to deploy scrapers isn't much of a hassle either.
from flask import Flask
from flask import request, jsonify
app = Flask(__name__)
def scraping_function(resp):
""" scraping function to extract data """
...
data = {"Name": "", "Description":""}
return jsonify(data)
@app.route('/')
def home():
username = request.args.get('category')
# dynamically set the url to be scraped based on the category received
url = f"https://example.com/?category={category}"
resp = request.Get(url)
json_response = scraping_function(resp)
return json_response
if __name__=='__main__':
app.run(port=9000)
For Golang, net/http is still the way to go for spawning small servers to interface with logic.
package main
import(
"net/http"
"encoding/json"
"os"
)
type Example struct {
Name string
Description string
}
func scraping_function(r http.Response) Example {
// scraping function to extract data
data := Example{}
return data
}
func handler(w http.ResponseWriter, r *http.Request) {
category := r.URL.Query().Get("category")
if category == "" {
http.Error(w, "category argument is missing in url", http.StatusForbidden)
return
} else {
url := "https://example.com/?category=" + category
resp, _ := http.Get(url)
scraping_result = scraping_function(resp)
// dump results
json_output, err := json.Marshal(scraping result)
if err != nil {
log.Println("failed to serialize response:", err)
return
}
w.Header().Add("Content-Type", "application/json")
w.Write(json_output)
}
func main(){
http.HandleFunc("/", handler)
// check if port variable has been set
if os.Getenv("PORT") == "" {
http.ListenAndServe(":9000", nil)
} else { http.ListenAndServe(":"+os.Getenv("PORT")) }
}
To interact with the server, just use curl. If it is running on port 9000, the command to test both servers is shown as
curl -s 'http://127.0.0.1:9000/?category=cats'
{
"Name": "",
"Description": "",
}
Deployment
Your scraper web application was never meant to live on your system. It was built to win, to conquer, to prosper, to fly (okay enough of the cringey Fly - Nicki Minaj motivational detour). PaaS such as Heroku makes it easy to deploy both Python and Golang web applications by just writing a simple Procfile. For flask applications, it is much better to use a production ready server such as Gunicorn. Just add it to your requirements.txt file at the root of your application.
# Flask Procfile
web: gunicorn scraper:app
File layout for flask scraper
|-scraper.py
|
|-requirements.txt
|
|-Procfile
Read Deploying a Flask application to Heroku for a deeper look into the deployment process.
For the golang application, make sure to have a go.mod file at the root of the project and a Procfile as well. Using your go.mod, Heroku knows to generate a binary located in bin/ named after your main package scipt
# Go Procfile
web: ./bin/scraper
File layout for net/http scraper
|-scraper.go
|
|-go.mod
|
|-Procfile
Read Getting Started on Heroku with Go for more information
Example Scraping Project with Python
I was playing around with creating a reverse image search engine using Keras's ResNet50 and Imagenet weights and made a small search page for it. The problem however, was that whenever I got the image class in question, I would have to redirect to Google.I want to display the results on my own web application, I cried. I tried using Google's API but at the same time I wanted the option of switching the search engine to perhaps something else like Bing. The corresponding script grew into it's own open source project and ended up involving multiple contributors and numerous scraped engines. It is available as a python library and has been used by over 600 other github repositories, mostly bots that need search engine capability within their code.

View Search Engine Parser on Github
Example Scraping Project with Go
I was visiting my favourite low data movie download site netnaija, but that day was particularly annoying. I moved to click and I got redirected to pictures of b**bs. I just want free movies, I cried.
I proceeded to create Gophie. It is a CLI tool which enables me to be the cheapskate I am without getting guilt tripped. Search and download netnaija movies from the comfort of my terminal. Scraping 1, Netnaija 0.

View Gophie on Github
Conclusion
In this article, you've come across some of the ideas that go into creating web scrapers for data retrieval. Some of this information, with a little more research on your part can go into creating Industry-standard scrapers. I tried to make the article as end to end as possible however this is my first attempt at writing a technical article, so feel free to call my attention to anything crucial you feel I might have missed or leave questions in the comments below. Now go and scrape everything!
PS ✏️ : I am not sure if it is legal to scrape Google, but Google scrapes everybody. Thank you

Top comments (11)
I love how you broke down everything in this article from html, colly and python.
One thing that I surely relate to is the popups! Sites like netnaija have a lot of them and I'm glad you pointed this out.
Good writeup Diretnan!
Keep scribbling...
For popups or any other dynamic element on webpages you can use Selenium and a headless browser to get the information.
Thanks, that's a good overview of the basics.
With scraping things can get big and serious fast and the codebase would get very big quickly. The majority of the work would be maintaining different scrapers/parsers for different websites that are always changing etc.
There's an excellent library/framework for creating scrapers (spiders) in Python: Scrapy. It takes a bit of a learning and setup but it's really really powerful once you master the concepts. There are daemons like scrapyd, web admin interface like Spiderkeeper etc and these work quite nicely together. If you're serious about scraping then you'd need a proxy solution also. I've had really good experience with Luminati. They're expensive but the best. And the comes cracking the captchas and other advanced topics. So scraping is a big world on its own. Happy scraping! :)
Exactly!... things get complicated quickly but there are excellent libraries out there to help. Thanks for the helpful references too
Awesome tutorial thank you. but for a non-tech user it is quiet hard to do a workable scraper for my WooCommerce store.
As a side solution i am using eCommerce scraper via e-scraper.com maybe it helps somebody too.
But I am not giving up))) Thank you for your input!!!
Nice Article
It is an educating and interesting piece of knowledge to be shared. Very aspiring and encouraging information. Thanks a lot. You can also visit: schoolentry.xyz/ is good to go, u can check them out. myfinanceblog.xyz/ for finance, scholarstufz.xyz/ for scholarship, rsguide.xyz/ for relationship and scholarshipshall.com/ scholarship again.
I loved the way you wrote this article. Super good!!!!
Thanks!
I love the way u simplified Ur work in details .nice work. soundcrib.net
Nice content dotunsblog.com.ng/
Some comments have been hidden by the post's author - find out more