
This is the third article in the series, Udacity: SUSE Cloud Native Foundations. Here I'll be going through the design requirements that you need to put in mind when architecting cloud native applications.
In this section, we'll go over the design factors that needs to be considered before building any application. It is vital to define the design and structure right at the beginning.
- Monoliths and Microservices
- Trade-offs for Monoliths and Microservices
- Practices for Application Development
Design Considerations
It is necessary to allocate time at the start to identifying the design consideration ensure that the application will be built and maintained with minimal engineering effort.
-
List all requirements
In this phase, we determine the following:- Stakeholders - who will sponsor the project?
- Functionalities - what functions should be included?
- End users - For whom is this service?
- Input and Output Process - What will be the flow?
- Engineering Teams - Who are needed in doing the project?
-
List all available resources
Here we determine what is the context of implementing these functionalities.- Engineering resources - Who can work on the project?
- Financial resources - How much is the budget?
- Timeframes - How soon do we want the project to finish?
Monoliths and Microservices
After the assessment of requirements, we can now move to determining the architecture to be used in building the application. There are two models which are usually referenced: monoliths and microservices.
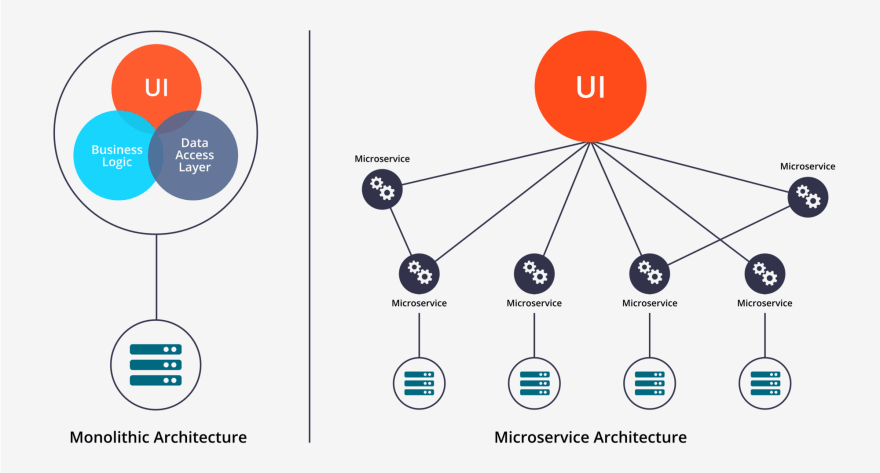
An application will typically have three tiers:
- UI (User Interface) - handles HTTP requests from the users and returns a response
- Business logic - contained the code that provides a service to the users
- Data layer - implements access and storage of data objects

In a monolithic architecture, application tiers can be described as:
- part of the same unit
- managed in a single repository
- sharing existing resources (e.g. CPU and memory)
- developed in one programming language
- released using a single binary
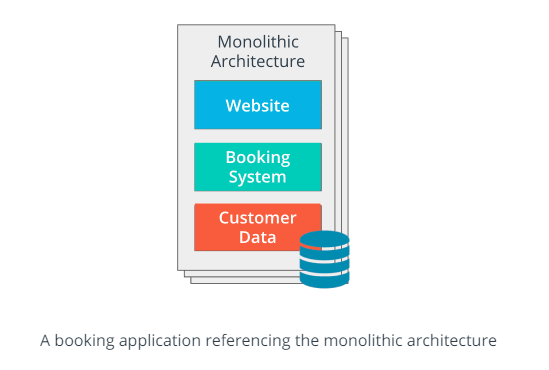
In a microservice architecture, application tiers are managed independently, as different units which are:
- managed in a separate repository
- own allocated resources (e.g. CPU and memory)
- well-defined API (Application Programming Interface) for connection to other units
- implemented using the programming language of choice
- released using its own binary
Trade-offs

Both the monolithic and microservices architecture has their own set of trade-off that we need to consider:
-
Development Complexity
Development complexity represents the effort required to deploy and manage an application.- Monoliths - one programming language; one repository; enables sequential development
- Microservice - multiple programming languages; multiple repositories; enables concurrent development
-
Scalability
Scalability captures how an application is able to scales up and down, based on the incoming traffic.- Monoliths - replication of the entire stack; hence it's heavy on resource consumption
- Microservice - replication of a single unit, providing on-demand consumption of resources
-
Time to deploy
Time to deploy encapsulates the build of a delivery pipeline that is used to ship features.- Monoliths - one delivery pipeline that deploys the entire stack; more risk with each deployment leading to a lower velocity rate
- Microservice - multiple delivery pipelines that deploy separate units; less risk with each deployment leading to a higher feature development rate
-
Flexibility
Flexibility implies the ability to adapt to new technologies and introduce new functionalities.- Monoliths - low rate, since the entire application stack might need restructuring to incorporate new functionalities
- Microservice - high rate, since changing an independent unit is straightforward
-
Operational Cost
Operational cost represents the cost of necessary resources to release a product.- Monoliths - low initial cost, since one code base and one pipeline should be managed. However, the cost increases exponentially when the application needs to operate at scale.
- Microservice - high initial cost, since multiple repositories and pipelines require management. However, at scale, the cost remains proportional to the consumed resources at that point in time.
-
Reliability
Reliability captures practices for an application to recover from failure and tools to monitor an application.- Monoliths - in a failure scenario, the entire stack needs to be recovered. Also, the visibility into each functionality is low, since all the logs and metrics are aggregated together.
- Microservice - in a failure scenario, only the failed unit needs to be recovered. Also, there is high visibility into the logs and metrics for each unit.
Summary:
There is no "golden path" to design a product, but a good understanding of the trade-offs will provide a clear project roadmap.
Application Deployment: Best Practices

You've determine the suitable model for your application based on the criteria we're specified above. Next step would now be implementation.
When building solutions, it is important to keep in mind the best practices that we need to follow during the release and maintenance phases. Doing so would ensure high availability and increased resiliency.
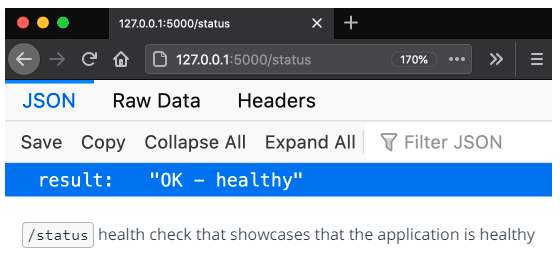
Health Checks
These are mainly about the status of the application and ensuring it meets the expected behavior to take on the traffic. These are normally HTTP endpoints such as /health or status which returns HTTP response codes to let you know if the application is healthy.
Metrics
These are used to quantify the performance of an application. Metrics include statistics collected on the services such as number of logins, number of active users, number of reqeusts handled, CPU utilization, and memory. Metrics are usually returned via an HTTP endpoint such as /metrics.
Logs
Like metrics, logs aggregation provides significant insights on the application's operation on a particular timeframe. Logs are extremely beneficial in troubleshooting and debugging application issues.
They are usually collected through standard out(STDOUT) or standard error (STDERR) through a passive logging mechanism and then sent to the shell, or they can be collected through logging tools such as Splunk and stored at the backend. Logs can also go directly to the backend storage without a monitoring tool by using active logging.
| Logging Levels | Meaning |
|---|---|
| DEBUG | record fine-grained events of application processes |
| INFO | provide coarse-grained information about an operation |
| WARN | records a potential issue with the service |
| ERROR | notifies an error has been encountered, however, the application is still running |
| FATAL | represents a critical situation, when the application is not operational |
As well, it is common practice to associate each log line with a timestamp, that will exactly record when an operation was invoked.

Tracing
Tracing can be used to understand the full journey of a request, including all the invoked functions. This is usually integrated through a library and can be utilized by the developer to record each time a service is invoked.
These records for individual services are defined as spans. A collection of spans define a trace that recreates the entire lifecycle of a request.
Resource Consumption
This is about the resources that an application uses to perform its operations, usually CPU, memory, network throughput, and number of concurrent requests.
You can check out the following links if you'd like to learn more:
- Pattern: Health Check API
- Best Practice on Metric Naming
- How to Log a Log: Application Logging Best Practices
- log4j - Logging Levels
- Enabling Distributed Tracing for Microservices With Jaeger in Kubernetes
I initially wanted to limit these series into 6 parts but I find that it'll be helpful to include the exercises and solutions, and to make sure that each article wouldn't be too long, I'll be putting the course works on separate articles. 😃
Up next, we'll be doing two labs about application health checks and application logging.
If you enjoy this write-up and would like to learn more, make sure to hit the Follow just below and bookmark the series. I'll also be glad to connect with you on Twitter.
See you there! 😃


Top comments (0)