
This is the seventh article in the series, Udacity: SUSE Cloud Native Foundations. Join me as we explore how to create, manage, and maintain multiple containers using a container orchestrator.
In this section, we'll cover the following:
Kubernetes - The What and the Why
When deploying a containerized application into production, we must ensure that it will operate at scale. This would mean that there would not be just one instance of the containerized application, but thousands. For that we can utilized a container orchestrator such as:
- Docker Swarm
- Apache Mesos
- CoreOS Fleet
- Kubernetes
Among all the options, Kubernetes have become the leading choice in the industry in managing containerized workloads. Its main features are:
☑️ Portability
Kubernetes can be hosted on any available infrastructure, including public, private, and hybrid cloud.
- open-source nature
- vendor agnosticism.
☑️ Scalability
This enables application to scale based on the amount of incoming traffic. Elasticity is also at the core of Kubernetes.
- HPA (Horizontal Pod Auto scaler) - determines the replicas needed for a service.
☑️ Resilience
It is necessary to quickly recover and minimize any downtime. Kubernetes has powerful self-healing capability which can handle most container failures.
- ReplicaSet
- readiness
- liveness probes
☑️ Service Discovery
Automatically identify and reach new services once these are available.
- cluster level DNS (or Domain Name System) - which simplifies the accessibility of workloads within the cluster.
- routing and load balancing of incoming traffic - ensures requests are served without application overload.
☑️ Extensibility
Uses the building-block principle. It has a set of basic resources that can be easily adjusted.
- rich API interface, that can be extended to accommodate new resources or CRDs (Custom Resource Definitions).
☑️ Operational Cost
Efficiency of resource consumption within a Kubernetes cluster, such as CPU and memory.
- powerful scheduling mechanism - decides which node has sufficient resources that can handle the workload.
- on-demand - infrastructure resources are allocated on-mand.
- cluster auto scaler - automatically scale the cluster size based on the current incoming traffic. which guarantees that the cluster size is directly proportional to the traffic that it needs to handle.
Kubernetes Architecture
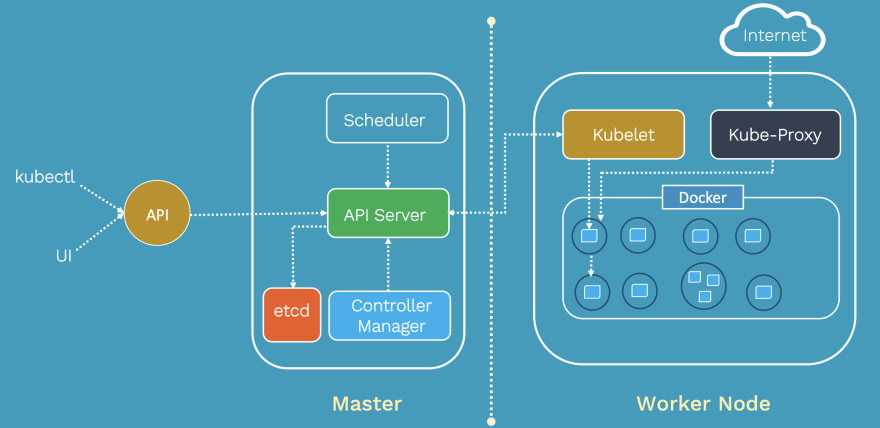
Cluster
A collection of distributed physical or virtual servers or nodes, which is used to host and manage workloads. It has two types:
-
Master node (control plane)
Makes global decisions about the cluster. Its components are:
- kube-apiserver - exposes the Kubernetes API
- kube-scheduler - decides which node will handle workload
- kube-control-manager - ensures resources are up-to-date
- etcd - backs-up and keeping manifests for the entire cluster
-
Worker nodes (data plane)
Used to host application workloads. Note that both component below are running on all nodes - both on master and work nodes.
- kubelet - agent that runs on every node, notifies the kube-apiserver that this node is part of the cluster
- kubeproxy - network proxy that ensures the reachability and accessibility of workloads places on this specific node
If you're interested to dig deeper into the Kubernetes architecture, you may check out the following links:
Creating a Cluster
To provision a cluster, you must ensure the control plane and data plane is up and running. This is referred to as bootstraping of cluster which can be done manually but would require executing components independently which introduces risk of misconfiguration.
You can also automate the cluster bootstrapping on on-premise or public cloud platforms using different tools.
For production-grade cluster:
- kubeadm
- Kubespray
- Kops
- K3s
For development-grade cluster,, which can be used for testing:
- kind
- minikube
- k3d
k3s is a lightweight version of kubernetes that can be installed using oen binary.
- operational 1-node cluster
- instals kubectl - CLI tool
Kubeconfig
The kubeconfig file contains all the metadata and authentication details, which grants users to access the cluster and query the cluster objects.
- usually stored locally under the ~/.kube/config file
- for k3s, it is within /etc/rancher/k3s/k3s.yaml
- user can set location through
--kubeconfigkubectl flag - user can set location via
KUBECONFIGenvironment variable
A kubeconfig file has three sections:
- Cluster - metadata for a cluster,
- User - user credentials needed to authenticate to your cluster(s)
- Context - links a user to a cluster. If the user credentials are valid and the cluster is up, access to resources is granted. Also, a current-context can be specified, which instructs which context (cluster and user) should be used to query the cluster.
Here is an example of a kubeconfig file:
apiVersion: v1
# define the cluster metadata
clusters:
- cluster:
certificate-authority-data: {{ CA }}
server: https://127.0.0.1:63668
name: udacity-cluster
# define the user details
users:
# `udacity-user` user authenticates using client and key certificates
- name: udacity-user
user:
client-certificate-data: {{ CERT }}
client-key-data: {{ KEY }}
# `green-user` user authenticates using a token
- name: green-user
user:
token: {{ TOKEN }}
# define the contexts
contexts:
- context:
cluster: udacity-cluster
user: udacity-user
name: udacity-context
# set the current context
current-context: udacity-context
Once you have a valid kubeconfig file and the cluster is up, here are some commands you can use to inspect the cluster:
Gets cluster and add-ons endpoints.
kubectl cluster-info
List all the nodes in the cluster. The "wide" options provides wider output or more details.
kubectl get nodes
kubectl get nodes -o wide
Describes node configuration, like version, IP, capacity, pods, CIDR...
kubectl describe node {{NODE NAME}}
So far so good! We've covered a lot in this section. Up next, we'll check out what Kubernetes resources we can use to deploy applications into the Kubernetes clusters.
If you enjoy this write-up and would like to learn more, make sure to hit the Follow *just below and bookmark the series. I'll also be glad to connect with you on Twitter.
See you there!* 😃


Top comments (0)