
As a young boy I was always reluctant to do chores around the house. I just felt that doing the same thing again and again everyday was boring. As I grew up, this mentality changed for the better (thank god), and was hilariously replaced by the following quote in my professional life:
If it takes longer than 30 seconds, automate it.
Recently, I was tasked with creating about 18 repositories for an organization that I maintain for DSC-VIT, powered by Google Developers. All of the repositories needed to be created for the projects that we have planned for the first two quarters of 2020. I decided to make a shell script for it and the following are some of the things I learnt in the process.
Index
- Modular code in shell 👌
- Echo is bad at JSON 💩
- Easy arrays in shell 🌟
- Did my curl succeed? 🌀
- GitHub API rate limitation 🐌
- Switch-Case structure in shell 🌓
- Cross platform execution 🐳
- Unofficial bash strict mode 👮
Look up the code over here:
 L04DB4L4NC3R
/
gitcr
L04DB4L4NC3R
/
gitcr
A dead simple script to create/delete repos in bulk

GitCR
A dead simple script for bulk creation and deletion of GitHub repositories
Check out the blog related to this project: 7 things I learnt from a script for repository creation.
Functionalities
- Bulk create repositories from a template
- Revert creation
Instructions to run
Pre-requisites
- Docker, or a linux based system with curl and jq installed.
- Github personal access token with write and delete permissions.
- A template repository.
Setup
You'll need 2 things to get started:
-
A file called
.envwith the following variables. See the sample. -
The second thing that is needed is a
repos.txtfile with the name of the repositories that you want to create. The number of repositories can be anywhere between 1 to 5000, due to the rate limitation of the GitHub API. eg:
repo-1
repo-2
repo-3
...
repo-5000
See a sample here
Execution
To run the scripts on any platform, replace {PATH}…
Importing functions
I wanted modularity in my code right off the bat. This meant breaking down my code into smaller files with smaller functions and then creating one entrypoint (CLI) for their execution. I had functions to create repositories in bulk, delete and revert creation in bulk as well. I also added a function to give out a neat little manual if someone hit help.
├── functions
│ ├── config.sh
│ ├── create.sh
│ ├── manual.sh
│ └── revert.sh
├── gitcr
├── .env
├── README.md
└── repos.txt
I had to do 2 kinds of imports:
- Importing environment variables
- Importing functions
Both of them can be achieved via a simple syntax:
# in gitcr
. ./functions/config.sh
. ./functions/create.sh
. ./functions/manual.sh
. ./functions/revert.sh
All of the functions and exported variables in the included files can then be used directly in the main file. Note that I have used a . to import the aforementioned since it is recognized by sh shell. You can also use the source keyword to include them in bash but it is not recognized by sh.
Echo is bad at JSON
I wanted to write the output from every iteration to the console, or a JSON file, as specified by the user. The first thought that hit my mind was to use the echo command and pipe it out to a file, or console. echo is quite bad at that since it is not build for formatting JSON. Instead, I used jq for the same. So it looked like this:
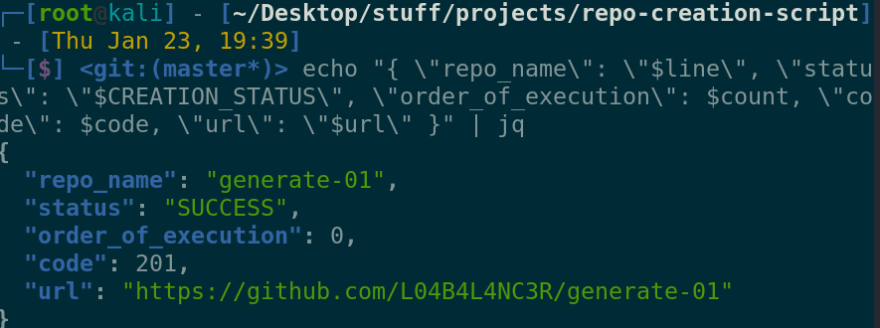
jq took garbage formatting and parsed a completely formatted JSON out of it. This can then be piped to a file at will.

Arrays in shell
For storing the JSON output in each iteration, I used an array. Arrays in shell can be declared and used in the following way:
result = () # an empty array
result=("abcd") # an array with 0-th index = "abcd"
echo ${result[0]} # printing out the index
result[1] = "defg" # assigning value to an index
echo ${result[@]} # the '@' can be used for returning the whole array
result[$iterator] = 2 # variables can be used as indices.
Note that memory for arrays can not be pre-allocated in shell.
Checking if a curl request succeeded
curl command has a -i flag which prints out the request details such as the status code returned as well as the message. This can be extracted from the request and be used to check if the request actually succeeded or not.
The following code returns the first line of information about the curl request.
$ res=`curl -i -s -XDELETE https://api.github.com/repos/$owner_name/$line -H "Authorization: token $token" | head -1 `
$ echo $res
HTTP/1.1 401 Unauthorized
The res variable can be broken down to get both the HTTP status code of the response, as well as its message, in the following way:
# To get the status code
$ code=`echo $res | cut -d" " -f2`
$ echo $code
401
# To get the status code response
$ status_of_res=`echo $res | cut -d" " -f3-5`
$ echo $status_of_res
Unauthorized

Now what happened here?
Notice that the head -1 command returns the first line of text from any input. We took that first line and we did a split with space as a delimiter, using the cut -d" " -f2 command.
-f2 flag means that we want the second token from the splitted string. Note that this numbering starts from 1 rather than 0. f3-5 means that we want tokens from 3 to 5, since HTTP status code messages can be more than a word long and the sentence does not have any more words after that.
Now we can use the status code we got to check if the request succeeded. GitHub API gives a status 204 after a DELETE request succeeds, so a simple check would look something like this:
if [[ $code -eq 204 ]]
then
echo "Request Succeeded"
else
echo "Request Failed"
fi
GitHub API rate limitation
GitHub API v3 has a rate limitation of about 5000 requests per authenticated user and 60 requests per hour for unauthenticated users. Whenever a request is sent to the API, it returns the total rate limitation and the amount remaining for the user, in the form of response headers:
X-RateLimit-Limit: 5000
X-RateLimit-Remaining: 4998
So if you are thinking about a bulk transaction application which uses the GitHub API, read more about rate limitation here.
For me, adding the validation in the script was easy:
- Read the number of repositories the user wants to create
- If the number is greater than 5000, then fail
Which is easily programmable in the following way:
# Read number of words in repos.txt
repo_count=`wc -w < repos.txt`
if [ $repo_count -gt $GITHUB_MAX_REQUESTS ]
then
echo "You are only allowed 5000 repos"
exit 1
fi
A more pragmatic way would be to check the X-RateLimit-Remaining header by pinging the GitHub API and then deciding how many repositories can user create, which is also easily doable by text processing curl response headers.
remaining=`curl -i -s -XDELETE https://api.github.com/repos/L04DB4L4NC3R/BOGUS_REPO -H "Authorization: token $token" | grep X-RateLimit-Remaining | head -1 | cut -d":" -f2`
Here, grep searches for the X-RateLimit-Remaining header, head -1 takes only the first sentence and cut -d":" -f2 uses a colon delimiter to extract only the number out of the header key-value pair, which is then stored in a variable called remaining.
Switch Case in shell
Switch-case statements in shell have a very unique syntax:
cli(){
case $1 in
create)
create $@
;;
revert)
revert $@
;;
*)
helpFunc
;;
esac
}
Notice the terminating word esac is actually the opposite of case. This syntax was designed in a way to make programming of CLI applications easy. The ) lexeme is used as a case statement and the case keyword is used as a switch statement if you compare it to other programming languages. Wildcard * has been used to match the default case in scenarios where the user enters something that is not handled by the CLI.
The create, revert and helpFunc are functions. In shell, functions are called without any parenthesis. Arguments can be passed to them by writing them in a space separated format after the function call. Interestingly, the $@ is used to pass all of the arguments (that we got when we executed the CLI) to the functions that are being called.
./gitcr create --out=json
# $@ in the gitcr function = "./gitcr" "create" "--out=json"
# When passed to the create function, it retains all of the
# original parameters
Cross platform execution
One of the challenges I faced while making this script was to make it
cross-platform. Docker came to the rescue! You can use a bash container, which occupies only 15 MB.

The following steps can be used for a cross-platform CLI job:
- Use a bash container
- Copy all files that are not user defined
- Build an image and push to DockerHub
- During runtime, mount a volume which has user defined files
- Delete the container after it has completed execution
The Dockerfile looked like this:
FROM bash
RUN apk update && apk add curl && apk add jq
RUN mkdir -p /usr/app/cli
WORKDIR /usr/app/cli
COPY . .
RUN chmod +x gitcr
During runtime, the following command can be executed:
docker run --rm --mount type=bind,source="{PATH}",target=/usr/app/cli/ angadsharma1016/gitcr -c "bash /usr/app/cli/gitcr create"
What happened here?
This command runs a container based off of a particular image, which has all of the code. During runtime, it takes in user defined files like .env and repos.txt as a volume mount inside the container and simply runs the CLI. Your system does not need to have bash and other tools installed.
Unofficial bash strict mode
Always start your bash scripts with the following lines:
set -euo pipefail
IFS=$'\n\t'
It means the following things:
-
set -e: Exit script if any of the commands throw a return code 1 -
set u: Any undeclared variable referenced will result in an error -
set -o pipefail: Commands in pipes won't fail silently -
IFS: Internal Field Separator controls what bash calls a word
If followed, the unofficial bash strict mode can save hours of debugging time. Read more it here
Conclusion
One night of hacking away at my zsh and trying to act like I know what I am doing taught me a lot about how to actually write useful scripts that automate a lot of work that you either have to do stat, or will have to do in the near future. It's always better to take some time off the task at hand to actually figure out a better solution to do the said task sustainably in the future.
Don't mind writing code or working on tools that other people have worked on before, as long as it is for your own personal learning (or rolling out a product better than market alternatives). Stay hungry and stay foolish!

Top comments (5)
curl command provides an option to get http response code directly, so instead of using "cut" command you can use following:-
Also: If you're going to do it over and over again; automate it.
Indeed 😊
Nice post , for GitHub rate limiting consider to use v4 ( with graphql ) , I fixed some problems with the v4
Thank you :) Yeah I considered using v4 but then I figured that 5000 rate limit is actually not bad for bulk creation of repositories. I hardly see a use case where someone would want to create more repos than that, at once, in an hour 😂