
Until recently, websites were pushing for web crawlers to index their content properly.
Now, a new type of crawler, AI crawlers, is changing the game, with negative repercussions on open source content and increasingly on companies that rely on content.
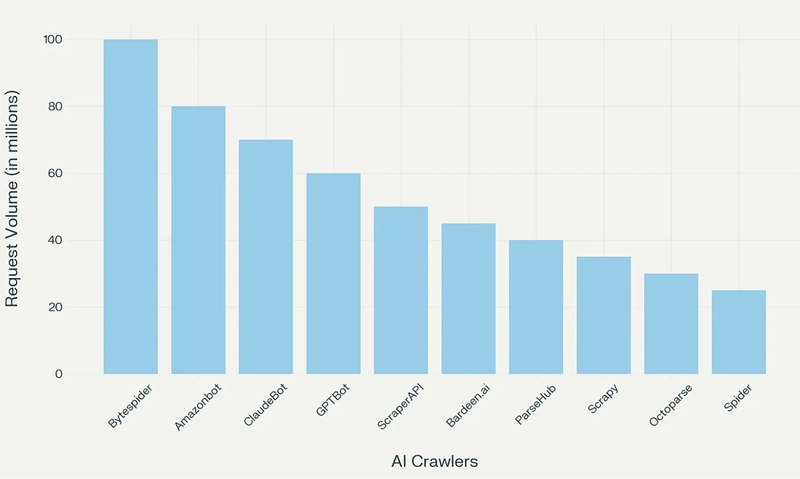
Here is how to fight back.
Why AI Crawlers Are Bad For The Internet As We Know It
In short:
- Spikes in costs for the website owners
- Outages or performance issues for the users
- DDoS outages — In the worst cases
Eventually, you get to the case of the founder of TechPays.com, where he noticed an over 10x increase in data outbound and over 90% of the traffic was AI crawlers.
Why Is This A Problem?
Because the content is scrapped for free and will then be sold to you through OpenAI, Meta AI, and whatever.
Three Ways to Fight AI Crawlers
So here are three ways to fight AI crawlers with their pros and cons.
- Using JavaScript
- Deploying AI Tarpits and Labyrinths
- Rate Limiting and Advanced Filtering
Using JavaScript
It seems AI crawlers struggle with JavaScript-heavy websites!
AI crawlers like GPTBot (OpenAI), Claude (Anthropic), and PerplexityBot have difficulty processing, or don’t process at all, JavaScript-rendered content.
While they fetch JavaScript files, they don’t execute the code, which results in useless content from the scraper's point of view.
Fight AI Crawlers Deploying AI Tarpits and Labyrinths
Tarpits are tools designed to trap AI crawlers in an endless maze of content, wasting their computational resources and time while protecting your actual content.
These tools create dynamic networks of interconnected pages that lead nowhere, effectively preventing crawlers from accessing legitimate content.
Popular Tarpit Solutions
- Nepenthes — Creates an “infinite maze” of static files with no exit links, effectively trapping AI crawlers and wasting their resources. This is brutal, and if you are searching for vengeance, this is the right tool for you!
- Cloudflare’s AI Labyrinth: Uses AI-generated content to slow down, confuse, and waste the resources of crawlers that don’t respect “no crawl” directives. See how to use AI Labyrinth to stop AI crawlers
- Iocaine: Uses a reverse proxy to trap crawlers in an “infinite maze of garbage” with the intent to poison their data collection. Iocaine is also based on Nepenthes but “Iocaine is purely about generating garbage.”

Fight AI Crawlers Using Rate Limiting and Advanced Filtering
Setting up geographical filtering with challenges (like CAPTCHAs or JavaScript tests) for visitors from countries outside your target market can significantly reduce unwanted crawler traffic.
A few examples:
- The sysadmin of the Linux Fedora project had to block the entire country of Brazil to combat aggressive AI scrapers!
- The founder of TechPays.com also tried this before moving to stronger measures like turning on Cloudflare’s AI crawler block
Find more techniques to deal with AI crawlers, but this is a pretty good starting point.
Final Considerations
Most likely, a good approach consists of a combination of several techniques like IP blocking and Cloudflare’s AI crawler blocking.
Furthermore, tarpit technologies and advanced rate limiting seem to be more robust against aggressive crawlers.
Obviously, you don’t want to block completely all AI crawlers because it could potentially hide your content from human visitors who rely on AI-powered searches to find your site.

Top comments (14)
My company's Saas product is hosted on unique sub-domains, one assigned to each customer. We often see "waves" of crawler traffic, even from legitimate bots such as Bing. Throttling legitimate bots using robots.txt is ineffective because of the different subdomains. Recently, we have had several "DDOS" type situations, with crawlers firing up on 1000s of our sub-domains within minutes. Our product relies heavily on dynamically generated content, so it spins up all our servers, eats through all available memory, and kills the databases by running 1000s of qps.
In the last month, Bingbot has been one of the worst culprits. Even though we have set up rates and good search times within the Bing console, this wave of bots seems not to respect those parameters. It occurred to us that these could be other scrapers faking Bingbot, but the handful of IPs I have tried do checkout with Bing.
To protect our servers and customers from this nuisance, I have configured our HAProxy-based load balancers to return 429 responses if a particular IP address accesses more than a certain number of sub-domains within a limited period of time. We use this same system to block bots scanning for compromised scripts (e.g., WordPress PHP, .env files, etc.).
Cool to hear your prod experience!
Have you had any thoughts about how this affects your website's visibility on the Bing chatbot?
As an example, searching with Perplexity seems to trigger a search across different websites. (maybe in real-time?)
If I were one of those websites, I would want to be searched by Perplexity's bot because I am sure there is an ongoing search about my product or something adjacent, right?
We are concerned about how this might affect our SEO. From what we have seen, we still get the BingBots scanning most of our domains daily, but in a low-key fashion that doesn't trigger the circuit breakers. It's our understanding that by returning a 429, we are not indicating that we don't exist, more that we were just overloaded and to try again later. As for Perplexity/Bing Chatbots, we rely on SEO from our customers' sites that are linked to our marketing site. Still, we keep the marketing on a separate infrastructure without the restrictions.
Don't fight AI bots and crawlers make them your friend — prerendering.com
Mmm, I have a few questions. Based on the article and on what people experienced, how do you think prerendering will reduce load?
How can you choose when to block or allow page crawl?
Good points!
I think 1 is very viable when the content is static (some post/article) but not possible if we need to show dynamic content, right? E.g. techpays.com has some filters to figure out a salary range given your role/location etc.
It's good for static and dynamic websites, cache TTL can get set in a range between 1 hour to 31 days
Thanks so much
Do you have a website that has experienced something similar?
great info.. thanks
No problem! Have you experienced something similar?
Same experience here — at first we were excited to see traffic going up, then came the shock of realizing it was just aggressive AI crawlers burning through our plan quotas.
Neat, I liked how it showed real ways to stop sneaky botshow can we protect online content without hurting the good parts of the internet?