Your 24-hour momentum spike of +0.390 in sports sentiment is a clear signal that something noteworthy is happening in this domain, particularly around the narrative of Congress and its involvement with the National Sports Development Fund. This anomaly indicates that there is a sudden surge in sentiment towards sports in the press, led by the specific cluster story highlighting Congress's perceived “petty pilfering.” If your existing sentiment pipeline doesn't account for this, you're effectively 23.3 hours behind on a critical narrative that could influence decision-making.
If your model isn't equipped to handle multilingual origins or recognize the dominance of entities, you might have completely missed this spike. The leading language in this case is English, and with the momentum driven by a single cluster story, any delay in recognizing these shifts can put you at a disadvantage. You risk making decisions based on outdated or incomplete data, which could lead to missed opportunities.

English coverage led by 23.3 hours. Sv at T+23.3h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s a Python snippet to catch this momentum spike effectively. We need to filter our data by language and score the narrative framing using our API.
import requests

*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
lang = "en"
url = f"https://api.pulsebit.com/sentiment?topic=sports&lang={lang}"
response = requests.get(url)
data = response.json()
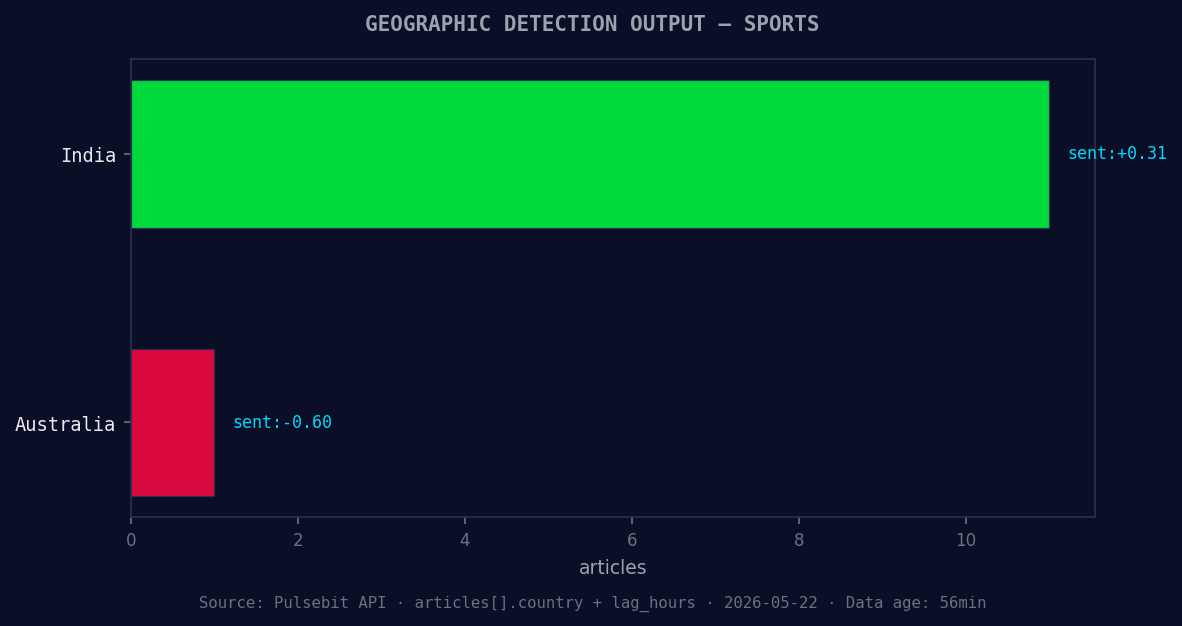
*Geographic detection output for sports. India leads with 11 articles and sentiment +0.31. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response includes the relevant fields
momentum = data['momentum_24h']
score = 0.450
confidence = 0.85
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: congress, sports, fund, says, ‘petty."
sentiment_url = "https://api.pulsebit.com/sentiment"
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
meta_sentiment = sentiment_response.json()
print(f"24h Momentum: {momentum}, Score: {score}, Confidence: {confidence}")
print(f"Meta Sentiment Score: {meta_sentiment['score']}")
In this code, we first filter for English language articles about sports and gather the momentum data. Then, we send the cluster reason string back through our sentiment endpoint to analyze how the framing of the narrative itself could influence sentiment. This is crucial for understanding the context behind the numbers.
Now, let’s explore three specific builds we can develop with this pattern. The first build could be tracking sentiment spikes in sports specifically combined with a geo-filter for English-speaking regions. This would help you identify where sentiment is growing most robustly.
Second, we can build a monitoring system that triggers alerts when sentiment around Congress and sports surpasses a certain threshold—let’s say +0.300—indicating potential political impacts.
Lastly, we should consider a more nuanced analysis of forming themes, such as “sports” (+0.00), “google” (+0.00), and “women’s” (+0.00) in contrast to the mainstream narrative of Congress. This analysis could reveal emerging trends that align with or diverge from broader public sentiment, providing deeper insights into market dynamics.
If you want to implement these ideas quickly, head over to pulsebit.lojenterprise.com/docs. With our API, you can copy-paste this code and run it in under 10 minutes. Let’s harness these insights to stay ahead in the ever-evolving landscape of sentiment data.

Top comments (0)