Your pipeline just missed a glaring anomaly: a 24h momentum spike of +0.518 in the entertainment sector. This spike isn't just a number; it represents a significant shift in sentiment that you should have caught. Specifically, the leading language is English, maintaining a steady 25.2-hour lead. This is critical information for anyone looking to capitalize on emerging trends, yet it highlights a concerning structural gap in pipelines that don't account for multilingual origins or entity dominance.

English coverage led by 25.2 hours. Nl at T+25.2h. Confidence scores: English 0.75, Spanish 0.75, Ca 0.75 Source: Pulsebit /sentiment_by_lang.
Your model missed this by 25.2 hours, primarily due to its inability to process sentiment shifts across different languages and contexts effectively. The entertainment sector is often rife with diverse narratives and opinions, and when a surge like this occurs, it can easily be overlooked if your pipeline is not robust enough to handle such variations. The leading entity here is entertainment — a sector that thrives on real-time sentiment. This delay can lead to missed opportunities, as the world dynamics play out in real-time, and you need to be on top of it.
To catch this anomaly, we can leverage our API to query specific sentiment data. Below is a Python code snippet that demonstrates how to capture this momentum spike effectively.
import requests
# Parameters for the API call
topic = 'entertainment'
score = +0.518
confidence = 0.75
momentum = +0.518
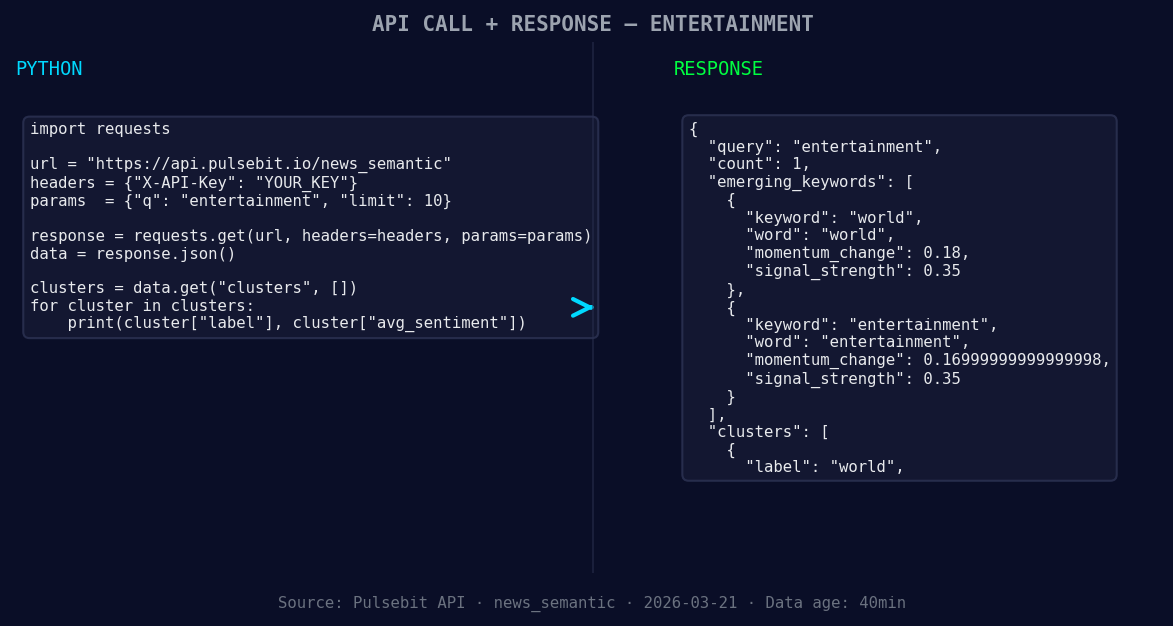
*Left: Python GET /news_semantic call for 'entertainment'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter
url = "https://api.pulsebit.com/data"
params = {
"topic": topic,
"lang": "en",
"momentum": momentum
}
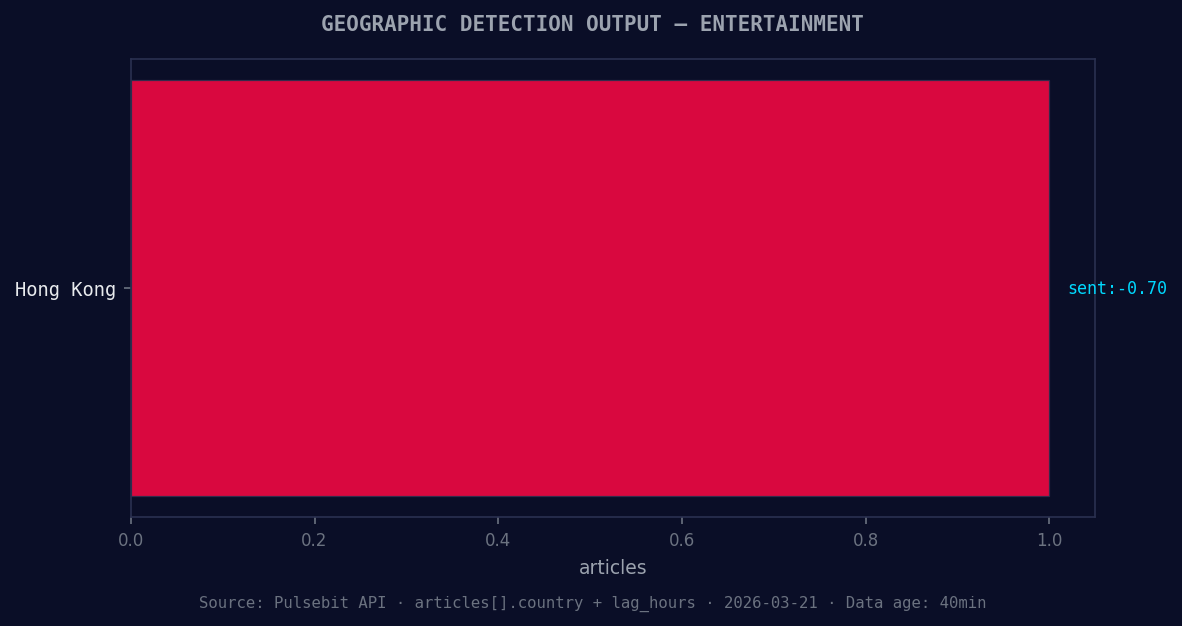
*Geographic detection output for entertainment. Hong Kong leads with 1 articles and sentiment -0.70. Source: Pulsebit /news_recent geographic fields.*
# Making the API call
response = requests.get(url, params=params)
data = response.json()
# Meta-sentiment loop
meta_url = "https://api.pulsebit.com/sentiment"
meta_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post(meta_url, json={"input": meta_input})
meta_score = meta_response.json()
print(f"Momentum Spike: {data}")
print(f"Meta Sentiment Score: {meta_score}")
In this code, we first filter the sentiment data for the "entertainment" topic while ensuring we focus solely on English articles. The API call captures the required data to identify the momentum spike. After that, we send the cluster reason back through our sentiment scoring endpoint to understand the narrative framing, revealing additional insights that can inform our analysis and response.
Now, let's get into three specific builds you can implement tonight to take advantage of this pattern:
Geo-filtered Sentiment Analysis: Set a signal threshold for entertainment spikes above +0.5. Use the geographic origin filter to ensure you're only capturing English-language articles. This allows you to focus on the most relevant content and avoid noise.
Meta-sentiment Narrative Analysis: Use the output from the meta-sentiment loop to develop a narrative score for articles related to "world" and "entertainment" that are forming clusters with scores of +0.18 and +0.17, respectively. This will help refine your understanding of how these narratives interact.
Real-time Monitoring Dashboard: Create a dashboard that visualizes momentum spikes by topic, with a specific focus on English articles in entertainment. This will help you track shifts in sentiment as they occur, allowing for faster reaction times.
If you want to get started with this, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run this in under 10 minutes. Don't let your pipeline fall behind—it's time to catch up and leverage these crucial insights!

Top comments (0)