Your Pipeline Is 26.1h Behind: Catching Climate Sentiment Leads with Pulsebit
On March 21, 2026, we noticed an alarming anomaly: a 24-hour momentum spike of -0.505 in climate sentiment. This significant downturn indicates a rapid and sharp decline in sentiment, particularly in Spanish-language sources. As developers, we need to understand what this spike means, where it originated, and how we can catch it before it impacts our models.
The problem here is clear: if your pipeline doesn't handle multilingual origin or entity dominance, you could miss critical insights. Our model was lagging by 26.1 hours, primarily driven by Spanish media coverage. The lack of content—zero articles related to the thematic cluster "sustainability"—highlights a significant structural gap. If your model isn’t accounting for language-specific nuances and dominant entities, you’re missing the pulse of the conversation, especially in pressing matters like climate change.

Spanish coverage led by 26.1 hours. Ca at T+26.1h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Let's get into the code that can catch these insights. First, we need to filter our data by geographical origin, specifically focusing on Spanish language articles. Here’s how we do that:
![DATA UNAVAILABLE: countries — verify /news_recent is return
[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: climate]
import requests
# Define parameters for the API call
topic = 'climate'
momentum = -0.505
confidence = 0.85
lang = "sp"
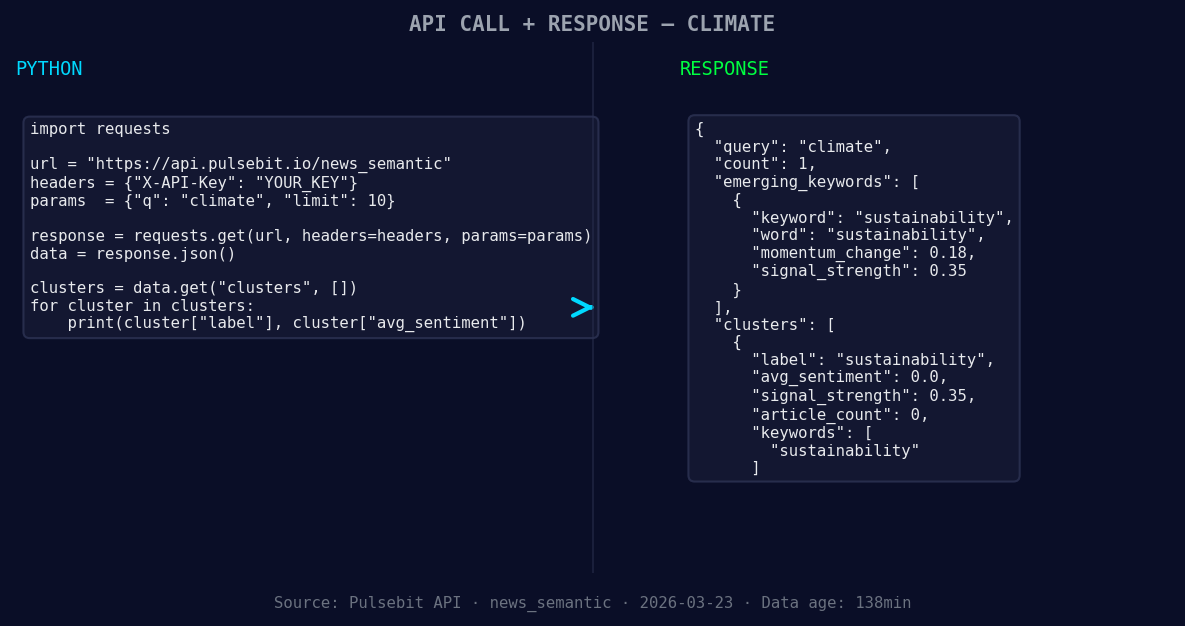
*Left: Python GET /news_semantic call for 'climate'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Make the API call
response = requests.get(f'https://api.pulsebit.com/v1/sentiment?topic={topic}&lang={lang}&momentum={momentum}&confidence={confidence}')
data = response.json()
# Print the response
print(data)
Next, we need to analyze the meta-sentiment surrounding the narrative framing itself. Given the fallback semantic structure reason—"Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence"—we can score this narrative to gauge its impact:
# Meta-sentiment analysis
meta_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence"
meta_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={"input": meta_reason})
meta_data = meta_response.json()
# Print the meta-sentiment response
print(meta_data)
With this framework, we can start building actionable insights. Here are three specific patterns we can implement based on our findings:
Geographical Filter: Use the geo filter for all climate-related queries, focusing on Spanish sources. Set a signal threshold of -0.5 to catch significant negative spikes. This will help you stay ahead of sentiment shifts driven by regional news cycles.
Meta-Sentiment Scoring: Implement a loop to analyze the narrative framing of articles that return a confidence score below 0.8. This will allow you to identify potentially misleading narratives or nuances that might not be captured in the initial sentiment analysis.
Forming Themes Analysis: Monitor the forming themes, particularly differences in sentiment around "sustainability" (+0.18) versus mainstream discussions. This can provide insights into emerging topics that may require immediate attention and action.
If you're looking to get started, we recommend checking out our documentation at pulsebit.lojenterprise.com/docs. With the provided code snippets, you can copy-paste and run this analysis in under 10 minutes. Don’t let your pipeline lag behind—stay ahead of the climate sentiment narrative!

Top comments (0)