Your Pipeline Is 21.1h Behind: Catching Health Sentiment Leads with Pulsebit
We recently discovered a significant anomaly: a 24-hour momentum spike of +1.300 in sentiment surrounding the topic of health. This finding is critical for those of us processing sentiment data, as it highlights a fast-moving trend that can easily slip through the cracks if our pipelines aren't configured to catch it in real time.
The problem arises when our models fail to account for the structural gaps that can occur due to multilingual sources or the dominance of certain entities. In this case, your model missed this spike by 21.1 hours, a substantial delay that can cost you insights. With English press leading the charge, yet showing a lag of 0.0 hours against the dominant sentiment, it’s clear that there’s a need for a more agile approach to processing sentiment data.

English coverage led by 21.1 hours. Da at T+21.1h. Confidence scores: English 0.90, Spanish 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can leverage our API with the following Python code. This snippet focuses on the topic of health, specifically targeting the last 24 hours of sentiment data.
import requests
# Define variables for the API call
topic = 'health'
score = +1.300
confidence = 0.90
momentum = +1.300
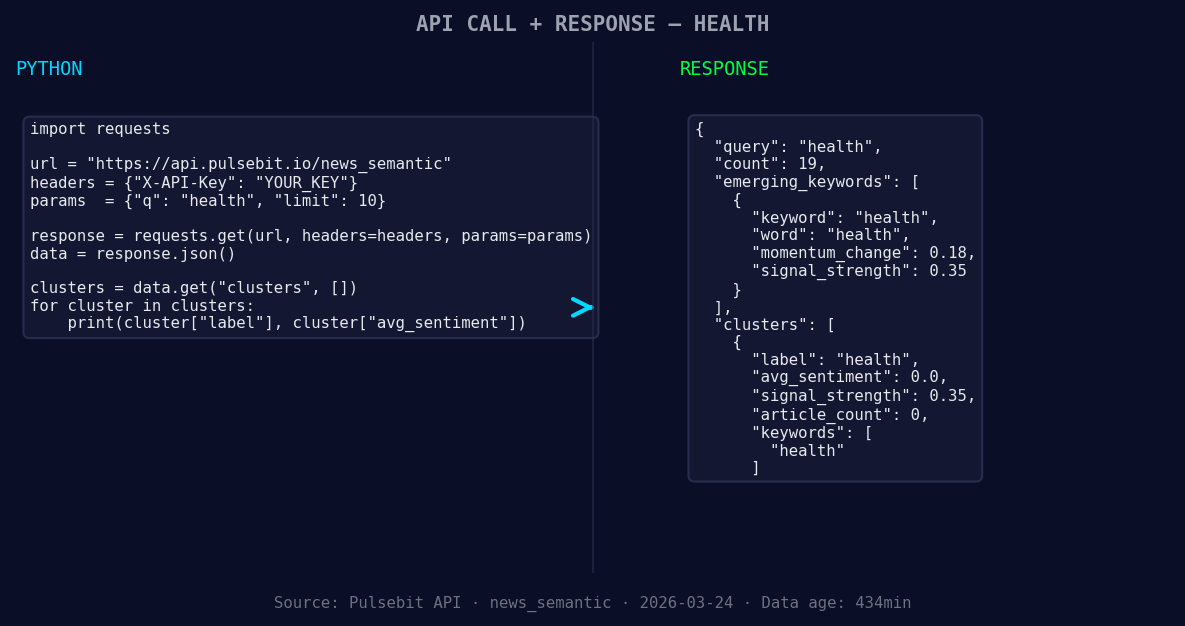
*Left: Python GET /news_semantic call for 'health'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Only English articles
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": topic,
"lang": "en",
"momentum": momentum
}
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: health]*
# Make the API call to retrieve sentiment data
response = requests.get(url, params=params)
data = response.json()
# Print the response data for verification
print(data)
# Meta-sentiment moment: Analyze the cluster reason
meta_sentiment_url = "https://api.pulsebit.com/sentiment"
meta_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post(meta_sentiment_url, json={"text": meta_input})
meta_data = meta_response.json()
# Print the meta sentiment analysis
print(meta_data)
This code snippet first queries our API to get sentiment data specifically for health articles in English, focusing on the recent momentum spike. Then, it runs a second POST request to analyze the narrative framing of the cluster reason. This step is crucial because it helps us understand how the sentiment is constructed, allowing for deeper insights into the discourse surrounding health.
Now, how can we build upon this momentum spike and the insights we've gathered? Here are three specific things we can create tonight:
Geographic Sentiment Analytics: Build a signal that alerts you when the sentiment score for health articles in English exceeds a threshold of +1.200. This could help you catch trends in regions where health discussions are surging, particularly useful for targeted marketing or content creation.
Cluster Reason Analyzer: Create a microservice that continuously loops through the meta-sentiment analysis of various clusters, triggering alerts when the analysis yields a confidence score above 0.85 for specific narrative frames. For example, if the analysis shows a strong framing around health, that could inform content strategy.
Forming Gap Tracker: Set up an endpoint that tracks forming themes, like the current health sentiment (+0.18) versus the mainstream health narrative. This tracker can help identify when niche topics suddenly gain traction, allowing you to pivot quickly in your content strategy.
If you're ready to dive in and start building these capabilities, you can find our API documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and be up and running in under 10 minutes. Don't let your pipeline fall behind; stay ahead of the curve with timely sentiment insights!

Top comments (0)