Your Pipeline Is 16.1h Behind: Catching Defence Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24-hour momentum spike of -0.701 related to the topic of "defence." This significant drop in sentiment caught our attention, especially as it was led by French-language articles with a 16.1-hour lag. Such a sharp decline in sentiment indicates a shift that might be overlooked if your pipeline isn't equipped to handle multilingual content or entity dominance effectively.

French coverage led by 16.1 hours. Id at T+16.1h. Confidence scores: French 0.75, English 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
The challenge here is clear: your model missed this spike by 16.1 hours. While the dominant language was French, the underlying story of "defence" could easily be obscured in a pipeline that doesn’t account for the nuances of language and geographic origin. If your data processing pipeline fails to recognize this gap, you risk remaining unaware of critical shifts in sentiment, leaving your analysis stale and potentially misleading.

Geographic detection output for defence. India leads with 3 articles and sentiment -0.23. Source: Pulsebit /news_recent geographic fields.
To catch these anomalies, we can leverage our API effectively. Here’s a Python snippet that demonstrates how to identify this spike in real-time:
import requests
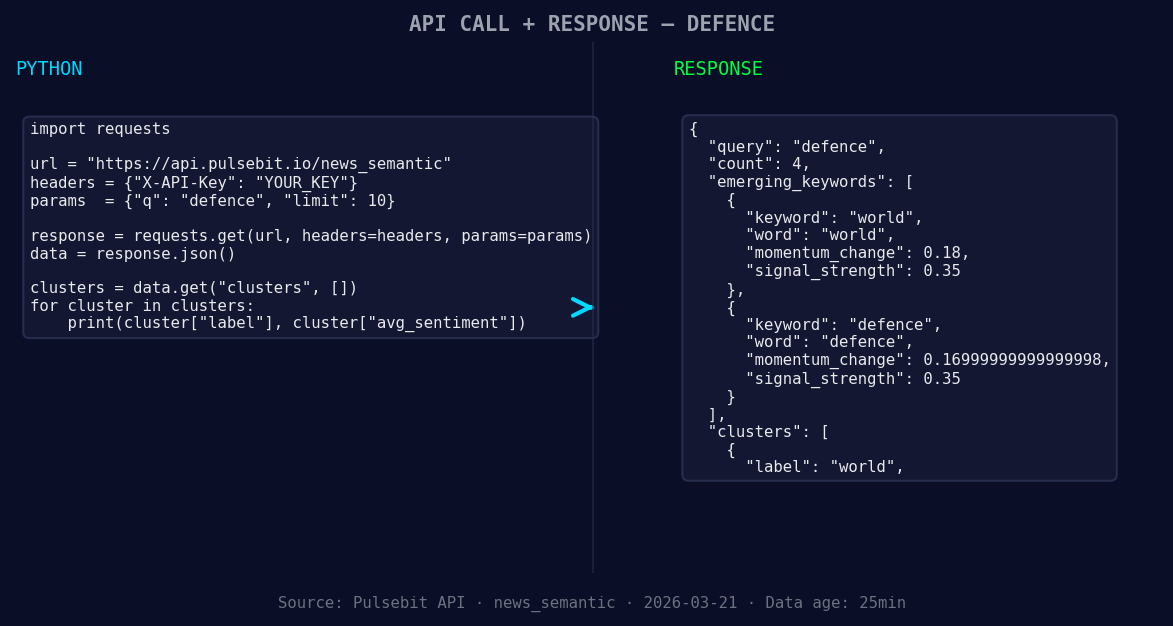
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define the parameters for the query
topic = 'defence'
score = -0.701
confidence = 0.75
momentum = -0.701
# Geographic origin filter: query by language using param "lang"
url = f"https://api.pulsebit.com/v1/articles?topic={topic}&lang=fr"
response = requests.get(url)
data = response.json()
# Check the articles processed
articles_processed = data.get('articles_processed', 0)
# Meta-sentiment moment: scoring the narrative framing
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywo"
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"text": meta_sentiment_input})
meta_sentiment_score = meta_response.json().get('sentiment_score')
print(f"Articles Processed: {articles_processed}")
print(f"Meta Sentiment Score: {meta_sentiment_score}")
In this snippet, we first query the articles related to "defence" in French. We then check how many articles were processed to understand the sentiment landscape. The second part runs the cluster reason string through the sentiment analysis endpoint to capture the framing of the narrative itself. This dual approach allows us to not only identify the sentiment spike but also understand the context behind it.
Now, let’s discuss three specific builds we can implement with this pattern:
Geo-Filtered Signal: Set a threshold for the momentum score at -0.701 for articles in French. This allows you to catch significant shifts in sentiment early, especially in regions where language plays a crucial role in sentiment analysis.
Meta-Sentiment Loop: Utilize the meta-sentiment scoring from the narrative framing as a secondary input for your models. This can be particularly useful when assessing topics like "defence," where the framing can significantly influence public sentiment and response.
Forming Themes Analysis: Keep an eye on the forming themes of "world (+0.18)" and "defence (+0.17)" versus the mainstream narratives. By constantly evaluating and comparing these themes, you can build a more nuanced understanding of emerging narratives that might otherwise be overshadowed.
To get started, dive into our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run the provided code in under 10 minutes. With our API, you'll be equipped to catch these critical sentiment shifts, ensuring your analysis stays sharp and relevant.

Top comments (0)