Your Pipeline Is 29.1h Behind: Catching World Sentiment Leads with Pulsebit
We just discovered an intriguing spike: a sentiment score of +0.075 and a momentum of +0.065 centered around the topic of "world." What’s particularly shocking is that our leading language is English, lagging by 29.1 hours against the backdrop of a significant narrative involving Pope Leo's comments on global tyrants amidst the Trump controversy. This is a glaring anomaly that any sentiment analysis pipeline should catch, but many aren’t equipped to do so.
The issue here is structural: your model likely missed this significant sentiment shift by 29.1 hours due to a lack of handling for multilingual origins or entity dominance. If your pipeline can't adapt to varying language contexts or prioritize entities like Pope Leo, you're left in the dust, unable to react to high-impact narratives. This means missing critical insights and being unresponsive to sentiment shifts that could drive your strategy.

English coverage led by 29.1 hours. Af at T+29.1h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can leverage our API effectively. Here’s a quick Python snippet that demonstrates how to identify this sentiment shift:
import requests
# Setting up parameters for the API call
topic = 'world'
score = +0.075
confidence = 0.95
momentum = +0.065
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query by language/country
response = requests.get("https://api.pulsebit.com/v1/news", params={
"topic": topic,
"lang": "en",
"score": score,
"confidence": confidence,
"momentum": momentum
})
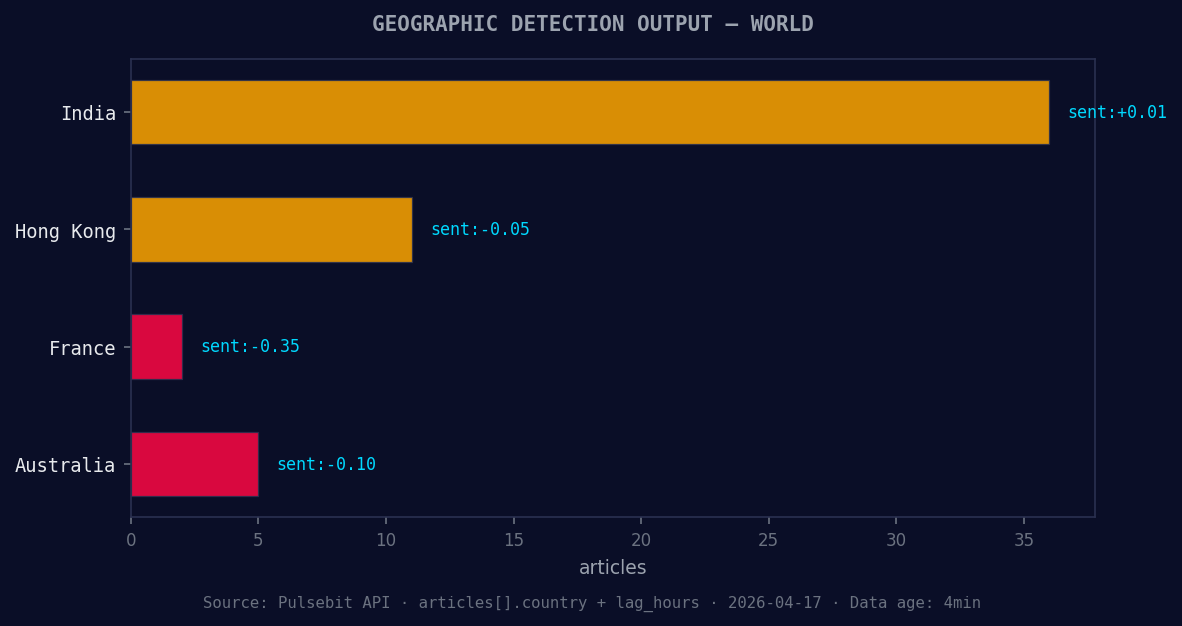
*Geographic detection output for world. India leads with 36 articles and sentiment +0.01. Source: Pulsebit /news_recent geographic fields.*
articles = response.json()
# Meta-sentiment moment: Running the cluster reason string back through the sentiment endpoint
cluster_reason = "Clustered by shared themes: pope, leo, cameroon, world, trump."
meta_sentiment_response = requests.post("https://api.pulsebit.com/v1/sentiment", json={
"text": cluster_reason
})
meta_sentiment = meta_sentiment_response.json()
In this code, we first query the API to filter articles based on the topic "world" and the English language. Then, we run a meta-sentiment analysis on the narrative framing itself. This dual approach allows us to catch both the immediate sentiment and the underlying narrative themes. The insights derived from the cluster reason provide a richer context for our sentiment score.
Now that we’ve set the stage, here are three specific builds we can integrate using this pattern to improve our sentiment analysis pipeline:
Entity Dominance Filter: Enhance your model by tracking dominant entities like "Pope Leo." Set a signal threshold where sentiment scores above +0.05 trigger alerts. This helps ensure you never miss critical narratives that could lead to significant shifts.
Language Sensitivity Module: Implement a geo filter to isolate sentiment trends based on language. For instance, if you observe a forming sentiment for "world" (+0.00) in English, but a contrasting sentiment in French or Spanish, create a comparative analysis to understand the divergence.
Dynamic Narrative Scoring: Use the meta-sentiment loop to generate dynamic scores based on emerging themes. For example, run a POST request with "Clustered by shared themes: news, world, education" and analyze the sentiment outputs. This keeps your sentiment assessment current and reflective of real-time shifts in public discourse.
By leveraging these builds, you can ensure your pipeline is resilient and responsive to both immediate sentiment shifts and the evolving narrative landscapes.
To get started, dive into our API documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can set this up in under 10 minutes and keep your models ahead of the curve.

Top comments (0)