Your Pipeline Is 18.0h Behind: Catching Investing Sentiment Leads with Pulsebit
We recently encountered a significant data anomaly: a 24-hour momentum spike of -0.207 in the investing sentiment. This figure raises a red flag about how fast sentiment can shift, and if you're not on top of it, you might miss critical signals. With the leading language being English and a lag of 18.0 hours, this situation highlights a substantial gap in our pipelines that handle multilingual origin or entity dominance.

English coverage led by 18.0 hours. So at T+18.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
When your model is 18 hours behind, you risk missing out on crucial investment insights, especially when the leading language indicates a shift in sentiment. This delay can cost you valuable time and opportunities, particularly with a topic like investing that can be highly reactive to news and developments. The lack of articles on "world" further emphasizes a structural gap, suggesting that our systems might not be adequately equipped to handle real-time multilingual sentiment.
To catch up, we need to implement a more responsive strategy. Here’s how we can do this programmatically using our API.
import requests
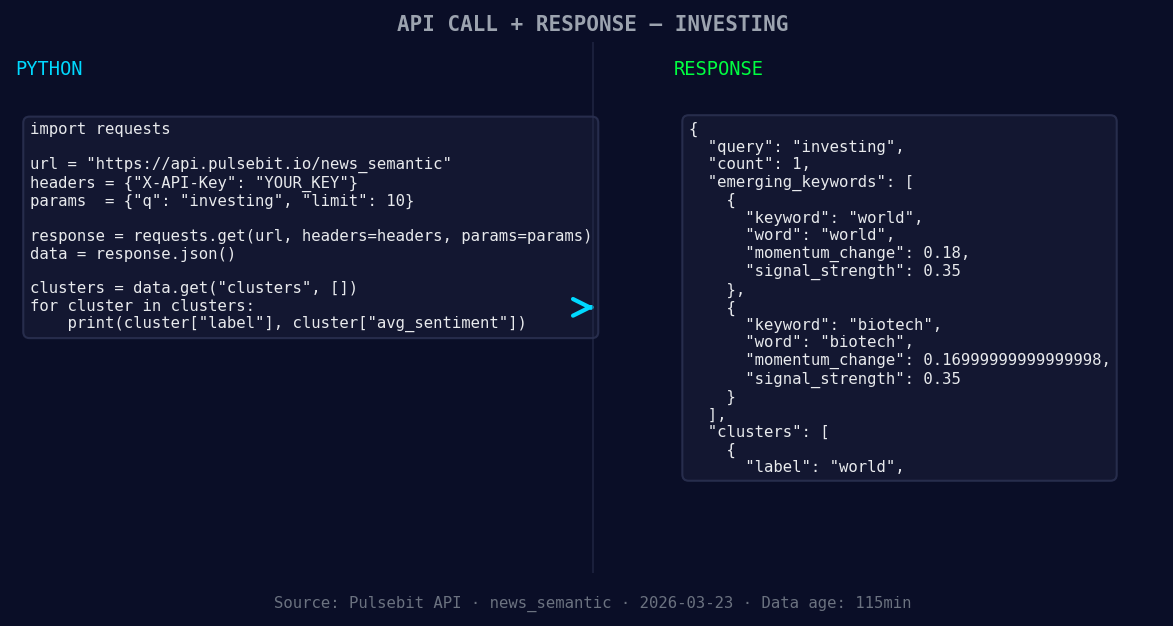
*Left: Python GET /news_semantic call for 'investing'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'investing'
score = -0.207
confidence = 0.85
momentum = -0.207
lang = "en"
# Geographic origin filter
url = f"https://api.pulsebit.com/v1/sentiment?topic={topic}&lang={lang}"
response = requests.get(url)
data = response.json()
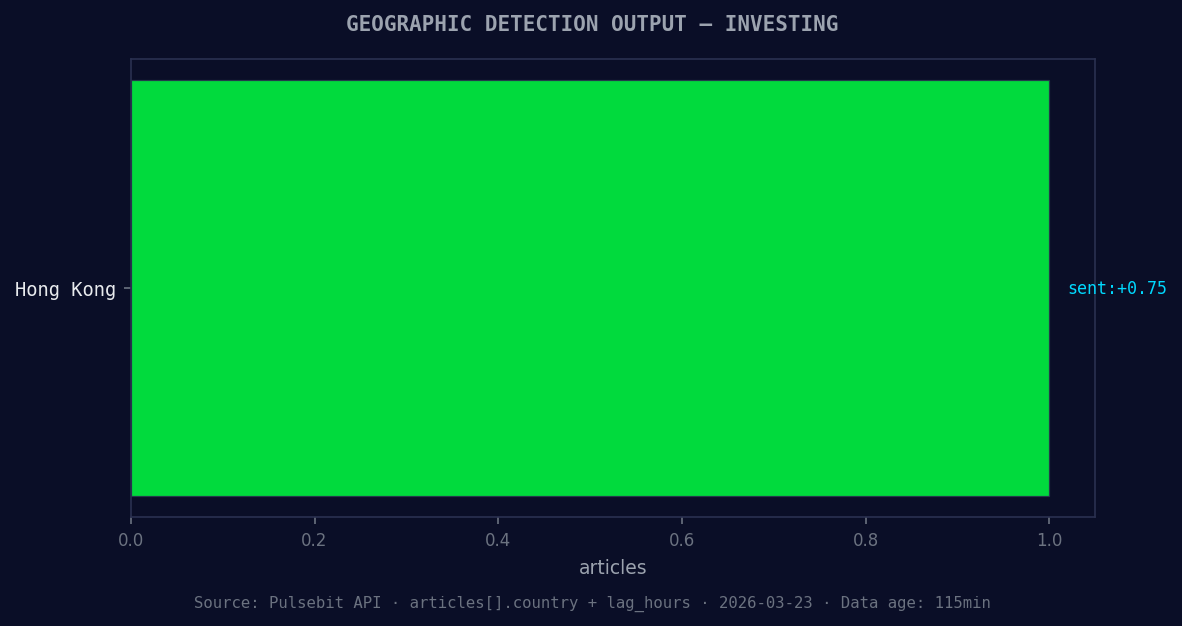
*Geographic detection output for investing. Hong Kong leads with 1 articles and sentiment +0.75. Source: Pulsebit /news_recent geographic fields.*
print(data) # Check the response for sentiment analysis
This code snippet fetches sentiment data by filtering for the English language. Note how we use the lang parameter to ensure we’re getting relevant results from the right geographic origin.
Next, let’s evaluate the narrative framing using the meta-sentiment moment. We need to run the cluster reason string through our sentiment endpoint:
# Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print(meta_data) # Review the sentiment score of the narrative
This POST request allows us to score the narrative itself, providing insight into how we might need to adjust our approach or messaging in light of the sentiment analysis.
Now that we have a clearer picture of the sentiment landscape, there are three specific builds we can implement tonight:
Geo Filter for Real-time Sentiment: Set up a signal that monitors the sentiment in English-speaking regions, focusing on a threshold of -0.207. Use the geographic origin filter to ensure you're catching sentiment shifts promptly.
Meta-Sentiment Loop: Construct a feedback loop that continuously evaluates the narrative framing around investment topics. Score narratives like "Semantic API incomplete" with a confidence threshold of 0.85 to identify potential gaps in our understanding.
Forming Themes Analysis: Create a monitoring system that flags forming themes such as "world(+0.18)" and "biotech(+0.17)" while comparing them against mainstream sentiments. This will allow us to see how emerging narratives are developing relative to established ones.
By implementing these strategies, we can ensure we're not behind the curve when it comes to sentiment analysis in investing.
For more on how to integrate these insights into your workflow, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy and paste the code above to start running these analyses in under 10 minutes. Let's get to work and close that 18-hour gap!

Top comments (0)