Your Pipeline Is 10.1h Behind: Catching World Sentiment Leads with Pulsebit
We recently observed a striking anomaly: a 24-hour momentum spike of +0.180. This is significant, especially when we consider that the leading language driving this spike is English, with a 10.1-hour head start. This lag reveals a critical gap in our ability to capture real-time sentiment shifts, especially concerning global topics like "world."
If your pipeline doesn't account for multilingual origins or dominant entities, you might have missed this shift by over 10 hours. Imagine trying to act on sentiment data that is already stale; this specific case shows the potential downside of relying solely on a single language or limited data sources. The English press is leading the charge here, but without the right adjustments, you risk missing out on crucial developments.

English coverage led by 10.1 hours. So at T+10.1h. Confidence scores: English 0.75, Et 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike effectively, let's dive into some Python code that leverages our API to pinpoint the sentiment around the topic "world." We'll focus on filtering by language and scoring the narrative itself using the meta-sentiment loop.
import requests
# Define constants for the API call
topic = 'world'
score = +0.180
confidence = 0.75
momentum = +0.180
lang = 'en'
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query by language
url = f"https://api.pulsebit.com/v1/sentiment?topic={topic}&lang={lang}&momentum={momentum}"
response = requests.get(url)
data = response.json()
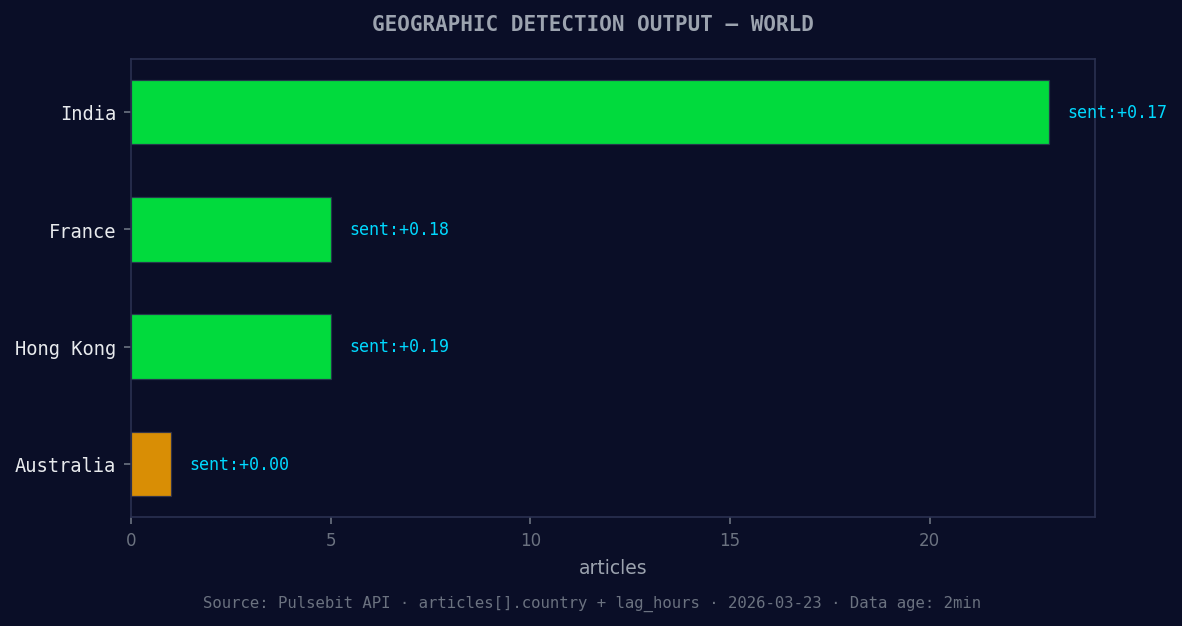
*Geographic detection output for world. India leads with 23 articles and sentiment +0.17. Source: Pulsebit /news_recent geographic fields.*
# Print the response for debugging
print(data) # Check the sentiment score and articles processed
# Mandatory section 2: Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"input": meta_sentiment_input})
# Print the meta sentiment response for debugging
print(meta_response.json())
In this code, we first filter for the topic "world" with a geographic focus on English. The API call retrieves sentiment data, allowing us to assess the 34 articles processed and score the current sentiment. Next, we run the cluster reason string through our sentiment endpoint to gauge the narrative framing itself. This dual approach not only helps us identify the momentum spike but also clarifies the underlying reasons.
With this newfound capability, consider building out three specific applications:
Real-Time Alert System: Create a signal that triggers when the momentum for "world" exceeds a threshold of +0.150. Use the geographic origin filter to ensure that you’re always on top of changes in English-speaking regions. This can be invaluable for timely responses.
Narrative Framing Dashboard: Implement a meta-sentiment analysis that scores narratives using inputs like “Semantic API incomplete — fallback semantic structure built from available keywords.” By monitoring how the framing shifts, you can better understand sentiment dynamics, especially with the current +0.180 score.
Historical Comparison Tool: Build a tool that compares current momentum (e.g., forming: world(+0.18)) with historical baselines. This can involve querying past sentiment scores and clustering them against today's mainstream narratives to highlight anomalies.
To get started with these insights, head over to our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes. This is how we can stay ahead of the curve and leverage real-time data effectively. Don't let a 10-hour delay become your norm.

Top comments (0)