Your Pipeline Is 20.6h Behind: Catching World Sentiment Leads with Pulsebit
We’ve just observed a striking anomaly: a 24-hour momentum spike of +0.684 related to the topic of "world." This spike is particularly noteworthy because it’s not just a number; it reflects a significant shift in sentiment, driven by emerging narratives—specifically, the humbling achievement of a humanoid robot breaking the half marathon world record in Beijing. As developers, we need to be aware of these shifts and the languages that underpin them.
If your pipeline fails to account for multilingual origins or the dominance of certain entities, you might be missing crucial signals. You could be 20.6 hours behind, as evidenced by the leading language being Spanish. This delay not only hampers your ability to act on emerging trends but also leaves you vulnerable to missing out on defining narratives that capture public interest. The sheer volume of articles (26 processed) indicates that this is more than a passing trend—it’s a significant development that can reshape sentiment.

Spanish coverage led by 20.6 hours. German at T+20.6h. Confidence scores: Spanish 0.90, English 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
Let’s dive into the code that allows us to catch these signals in real-time. We can execute a query to filter out articles in Spanish, focusing on our topic of interest:
import requests
# Define the parameters for our API call
topic = 'world'
score = +0.043
confidence = 0.90
momentum = +0.684
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query by language/country
response = requests.get(
'https://api.pulsebit.com/v1/articles',
params={'topic': topic, 'lang': 'sp'}
)
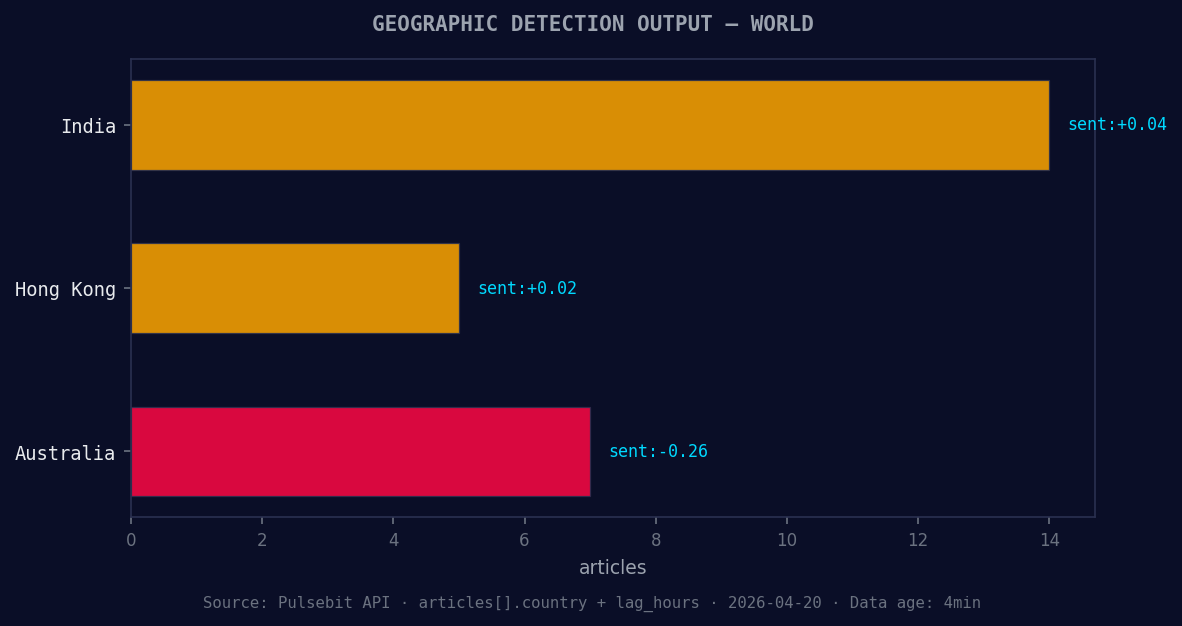
*Geographic detection output for world. India leads with 14 articles and sentiment +0.04. Source: Pulsebit /news_recent geographic fields.*
# Check if the response is valid
if response.status_code == 200:
articles = response.json()
print(f"Fetched {len(articles)} articles in Spanish about {topic}.")
else:
print("Error fetching articles:", response.status_code)
# Prepare the cluster reason for meta-sentiment moment
cluster_reason = "Clustered by shared themes: administration, warms, imf, world, bank."
# Meta-sentiment moment: Score the narrative framing itself
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
# Output the sentiment score
if sentiment_response.status_code == 200:
sentiment_data = sentiment_response.json()
print(f"Sentiment Score: {sentiment_data['score']} with confidence {sentiment_data['confidence']}.")
else:
print("Error fetching sentiment:", sentiment_response.status_code)
This code snippet demonstrates two key steps. First, we filter articles based on language, ensuring we capture the most relevant narratives. Second, we analyze the thematic narrative by scoring it through our sentiment analysis endpoint. This dual approach allows us to stay on top of emerging stories, particularly those that are forming around concepts like "world," "robot," and "Google," while contrasting against mainstream narratives such as "administration," "warms," and "IMF."
Here are three specific builds to consider based on this spike:
Language-Specific Monitoring: Set up a threshold where any topic that exceeds a momentum score of +0.5 in the Spanish language triggers an alert. This can be done through a real-time monitoring system or webhook, allowing you to react swiftly.
Meta-Sentiment Analysis: Create a service that automatically scores the sentiment of cluster reasons for any narrative that exceeds a confidence level of 0.85. This can help you gauge not just raw sentiment but also the framing of discussions, particularly useful when topics like "robot" and "world" emerge.
Forming Theme Tracker: Build a dashboard that visualizes the forming themes against mainstream narratives. It should highlight discrepancies and shifts, allowing you to quickly identify where emerging discussions are gaining traction compared to traditional topics.
If you’re ready to start building with this data, head over to our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes. Let’s harness the power of sentiment data together!

Top comments (0)