Your Pipeline Is 19.0h Behind: Catching Energy Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24h momentum spike of -1.000 in the energy sector. This figure not only suggests a significant downturn in sentiment, but it comes at a time when discussions around energy are heating up. With two articles clustering around the theme "A New Oil Shock Accelerates a Return to Nuclear Power," it's clear that sentiment is shifting rapidly.
But here's the kicker: if your pipeline isn’t equipped to handle multilingual origins or entity dominance, you might have missed this crucial signal by a staggering 19.0 hours. The leading language here is English, and it’s clear that the narrative around energy, particularly concerning nuclear power, is evolving faster than your existing model can keep up with. Ignoring this gap is not just a missed opportunity; it’s a potential loss in predictive accuracy that could cost you dearly.

English coverage led by 19.0 hours. Da at T+19.0h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
To catch these spikes efficiently, we can leverage our API to filter sentiment data by language and then analyze the narratives that are emerging. Below is a Python snippet to get you started:
import requests
*Left: Python GET /news_semantic call for 'energy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.io/v1/sentiment"
params = {
"topic": "energy",
"score": -0.217,
"confidence": 0.75,
"momentum": -1.000,
"lang": "en" # Filter for English articles
}
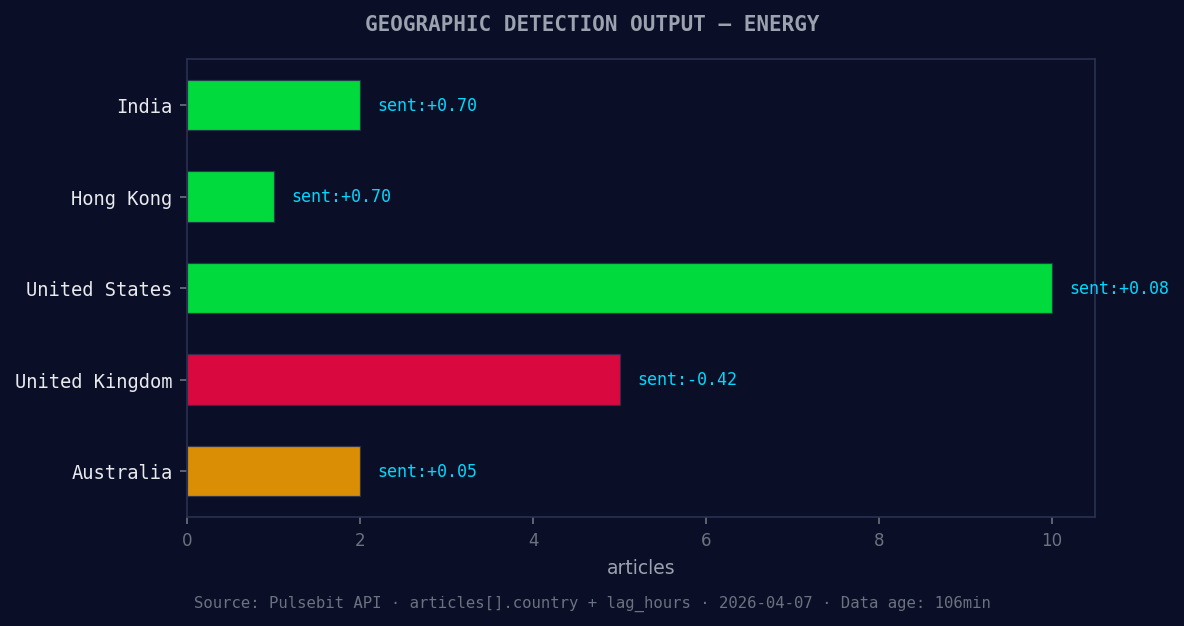
*Geographic detection output for energy. India leads with 2 articles and sentiment +0.70. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Check if the response is successful
if response.status_code == 200:
print("Filtered Data:", data)
else:
print("Error fetching data:", response.status_code)
In this code, we use our API to filter sentiment data specifically for English-language articles about energy. This allows us to catch sentiment shifts that might otherwise be lost in translation.
Next, we need to run the clustered narrative back through our sentiment scoring to understand the framing of the story. Here's how you do that:
# Step 2: Meta-sentiment moment
narrative = "Clustered by shared themes: fuel, his, why, high, costs."
meta_sentiment_url = "https://api.pulsebit.io/v1/sentiment"
# Request sentiment score for the narrative
meta_response = requests.post(meta_sentiment_url, json={"text": narrative})
if meta_response.status_code == 200:
meta_data = meta_response.json()
print("Meta Sentiment Data:", meta_data)
else:
print("Error fetching meta sentiment:", meta_response.status_code)
This second part sends the clustered themes through our sentiment endpoint, allowing us to gauge how the narrative itself is being framed in the context of the emerging energy crisis. This insight is what can really set you apart in making informed decisions.
Now that we have our signals, here are three concrete builds you can implement tonight:
Language-Specific Alerts: Set up a webhook that alerts you when the sentiment score for energy in English drops below a specific threshold, say -0.25. This will keep you ahead of negative shifts.
Meta-Sentiment Dashboard: Create a dashboard that visualizes the meta-sentiment scores over time. Use the average scores from narratives like "Clustered by shared themes: fuel, his, why," so you can see how public perception evolves alongside energy developments.
Geographic Trend Analysis: Analyze sentiment trends using our geo filter. For example, you could filter by countries with nuclear programs and compare their sentiment against the mainstream narrative. This could uncover localized sentiment spikes that are otherwise hidden in broader analyses.
Ready to dive in? Head over to pulsebit.lojenterprise.com/docs to get started. You can copy-paste the snippets above and have this running in under 10 minutes. Let’s not let your pipeline fall behind; stay ahead of the sentiment curve!

Top comments (0)